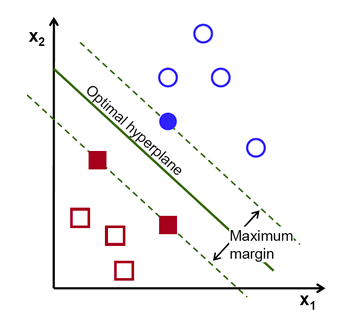
SVM (Support Vector Machine) püüab eristada n-dimensioonilises ruumis sarnaseid gruppe üksteisest, eristades neid joontega.
Parim joon (hyperplane rohkem kui 2D ruumis) on selline, mis asub kõikidest eristatud gruppidest võimalikult kaugel. Allpool oleval joonisel on selleks “Optimal hyperplane” joon
![]() ehk y = wx+b
ehk y = wx+b
w – weight vector (kaalu vektor)
b- bias
x – punkt treeningsetis, mis on lähim hyperplane’le ehk punkte teeningsetis , mis on lähim hyperplanele, kutsutakse Support Vectoriks (e canonical hyperplane).
Support vectoreid on kõige raskem klassifitseerida, kuna nad on nn decision linele kõige lähemal.
x on vektor.
Optimaalne hyperplane on esitletav väga paljudel Bo ja Bx kombinatsioonidena –![]()
Nüüd leiame kauguse hyperplane (Bo, B) ja punkti x vahel – 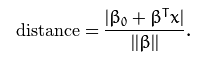 * Antud juhul võib käsitleda valemis olevat avaldist ||B|| = |B| eg abs(b) (For complex numbers, Norm[z] is Abs[z].)
* Antud juhul võib käsitleda valemis olevat avaldist ||B|| = |B| eg abs(b) (For complex numbers, Norm[z] is Abs[z].)
Võtame näiteks lihtsa andmehulga lineaarselt eraldatava R^2 ruumis:
Grupp 1 (+1) on: {(3;1), (3; -1), (6;1), (6;-1)}
Grupp 2 (-1) on: {(1;0), (0;1), (0;-1), (-1;0)}
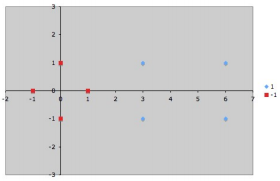
On näha, et jaotus saab olla selgelt lineaarne ja support vektorid oleks antud juhul:
{s1=(1;0), s2=(3;1), s3=(3;-1)}
Valides bias (b) = 1 saame:
{s1’=(1;0;1), s2’=(3;1;1), s3’=(3;-1;1)}
Koostame võrrandisüsteemi:
a1*s1’*s1′ + a2*s2’*s1′ + a3*s3’*s1′ = -1 // tegu on -1 grupi (grupp 1) support vectoriga
a1*s1’*s2′ + a2*s2’*s2′ + a3*s3’*s2′ = +1 // tegu on +1 grupi (grupp 2) support vectoriga
a1*s1’*s3′ + a2*s2’*s3′ + a3*s3’*s3′ = +1 // tegu on +1 grupi (grupp2) support vectoriga
Teades s1′, s2′ ja s3′ saame:
a1*{1,0,1}*{1,0,1} + a2*{3,1,1}*{1,0.1}*a3*{3;-1;1}*{1,0,1} = -1
a1*{1,0,1}*{3;1;1} + a2*{3,1,1}*{3;1;1}*a3*{3;-1;1}*{3,1,1} = +1
a1*{1,0,1}*{3,-1,1} + a2*{3,1,1}*{3,-1.1}*a3*{3;-1;1}*{3,-1,1} = +1
Korrutame vektorid:
a1*2 + a2*4 + a3*4 = -1
a1*4 + a2*11 + a3*9 = +1
a1*4 + a2*9 + a3*11 = +1
…
a1=-3.5; a2=0.75; a3=0.75
w’ = a1*s1’1 + a2*s2′ + a3*s3′ = -3.5*{1;0;1} + 0.75*{3;1;1} + 0.75*{3;-1;1} = {-3.5;0;-3.5} + {2.25;0.75;0.75} + {2.25;-0.75;0.75} = {1;0;-2}
Kuna me laiendasime meie algseid vektoreid biase (1), siis vektori w’ kaks esimest elementi on w ja viimane element on b ehk y = {1;0}*x + -2 graafikuga:
 , kus on nähe selgelt kolm (kollast) support vektorit ja neid eraldav arvutatud hyperplane.
, kus on nähe selgelt kolm (kollast) support vektorit ja neid eraldav arvutatud hyperplane.
Siiani tegelesime lineaarse probleemiga. Kujutame seekord, et meil on selline andmehulk:
Group 1 (+1) {(-2;-2), (2;2), (2;-2), (-2;-2)}
Group 2 (-1) {(-1;1), (1;1), (1;-1), (-1;-1)}
mida saab 2D kordinaatteljestikul esitleda nii:
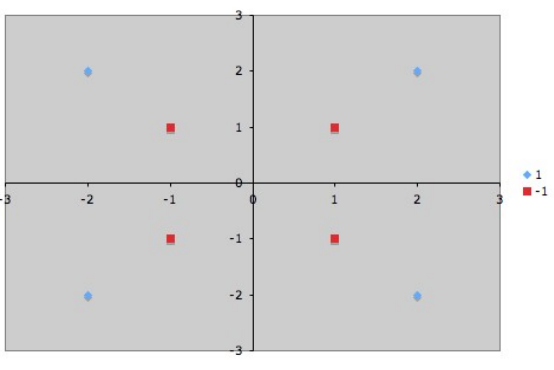
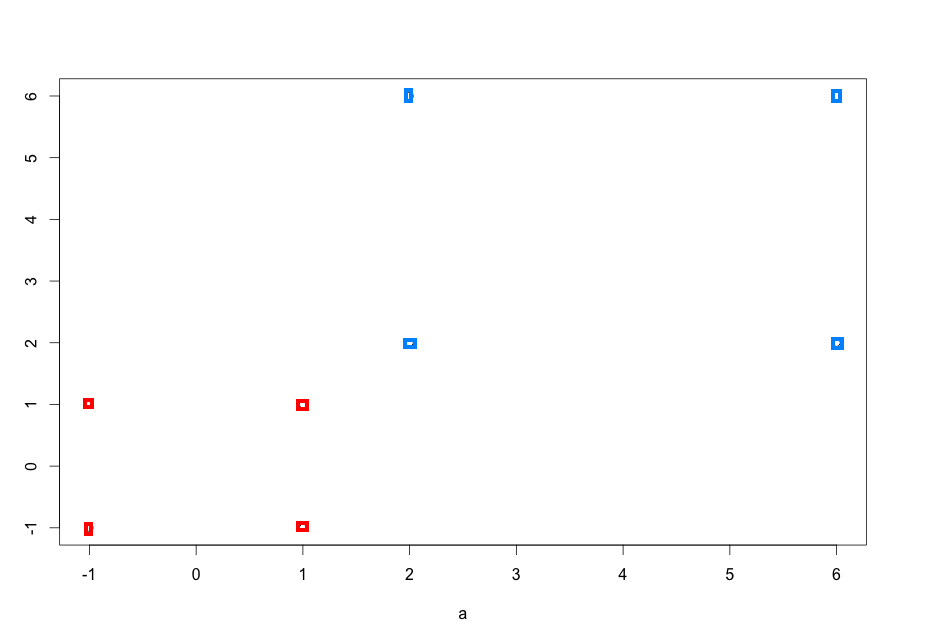
Mittelineaarse probleemi korral võib punktid anda teatud funktsiooni sisendiks, mis teisendab input space -> feature space
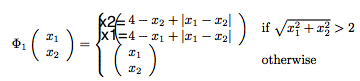
Näeme, et tingimusele sqr(x1^2 + x2^2) > 2 vastavad punktid {(-2;-2), (2,2), (2,-2), (-2,-2)} , mis kuuluvad gruppi +1. Funktsioon tagastab meile uue andmehulga:
Group 1 (+1) {(2;2), (6;2), (6;6), (2;6)}
Group 2 (-1) {(-1;1), (1;1), (1;-1), (-1;-1)}
Kanneme andut punktid kordinaatteljestikule:
Ja nüüd on antud andmehulka juba võimalik lineaarselt lahendada.
Võib kasutada ka tehnikat, mida kutsutakse Kernel Trick
Põhimõtteliselt anname input space ehk sisendandmetele juurde veel ühe mõõtme ja tekitame features space R^2 -> R^3
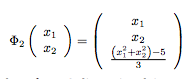
tulemusena tekib R^3 andmehulk:
Group 1 (+1) {(-2;-2;1), (2;2;1), (2;-2;1), (-2;-2;1)}
Group 2 (-1) {(-1;1;-1), (1;1;-1), (1;-1;-1), (-1;-1;-1)}
, mis on lineaarse(te) support vektoritega eraldatav.
Visuaalselt oleks see nüüd esitletav:
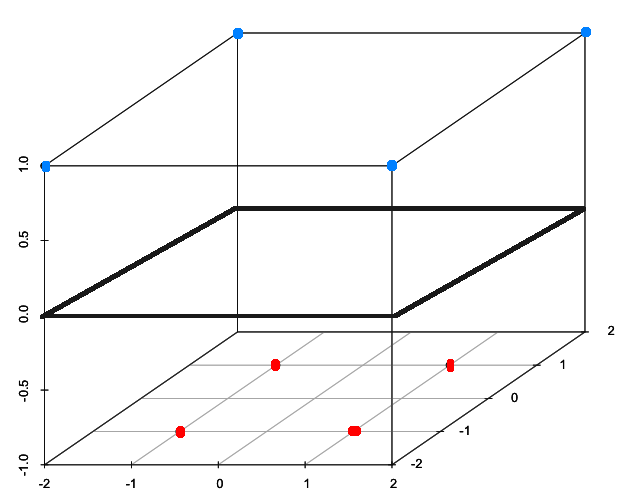 , selgelt on nüüd eristatavad lineaarselt punased ja sinised punktid 3D ruumis.
, selgelt on nüüd eristatavad lineaarselt punased ja sinised punktid 3D ruumis.
SVM andmete ettevalmistamine:
- Viia kõik tekstilised klassifikaatorid numbrilisele kujule
- Scaling – aitab vältida olukorda, kus mõni atribuut domineerib teise üle.
Tuleb kindlasti eristada, mida otsitakse, kas regressioonimudelit või klassifitseerimist (SVM-Type: C-classification)
Mida praktilist SVN annaks?
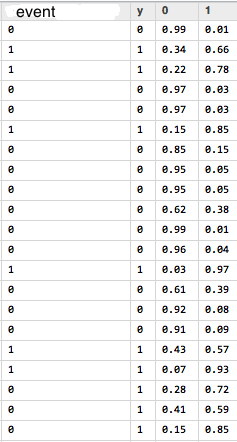
Oletame, et meil on hulk andmeid, mis iseloomustavad mingit objekti ja meil on iga objektiga seotud sündmus kujul 1 ja 0 e 1 tähendab, et sündmus toimus ja 0, et sündmus ei toimunud.
Kasutades SVN abi, saame näiteks alloleval pildil oleva info, mis kirjeldab:
event – reaalselt toimunud sündmus treeningandmetes; y – ennustatud event SVN poolt; 0 – sündmuse mittetoimumise tõenäosus; 1 – sündmuse toimumise tõenäosus