Paar märkust endale, et ei peaks koguaeg Googlit kulutama.
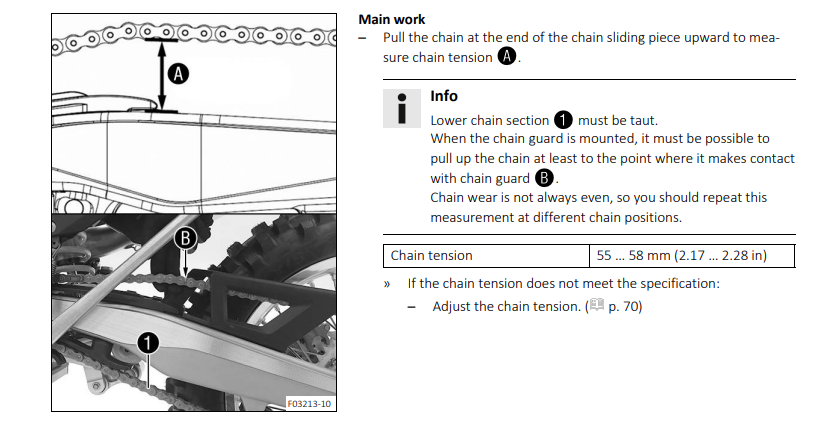
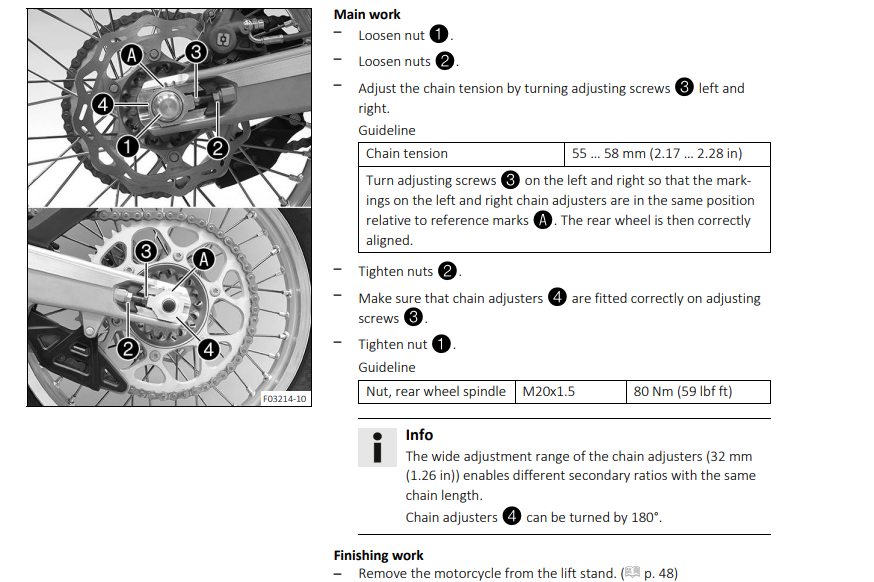
Originaal https://azwecdnepstoragewebsiteuploads.azureedge.net/21_3215013_en_OM.pdf
If you're inventing and pioneering, you have to be willing to be misunderstood for long periods of time
Paar märkust endale, et ei peaks koguaeg Googlit kulutama.
Originaal https://azwecdnepstoragewebsiteuploads.azureedge.net/21_3215013_en_OM.pdf
In case you have free space in volume group it is easy to increase logical volume.
Check volume group free space:
vgs
Extend logical volume by 1G:
lvextend -L +1G /dev/sysvg/var
Resize part:
xfs_growfs /dev/sysvg/var
Done!
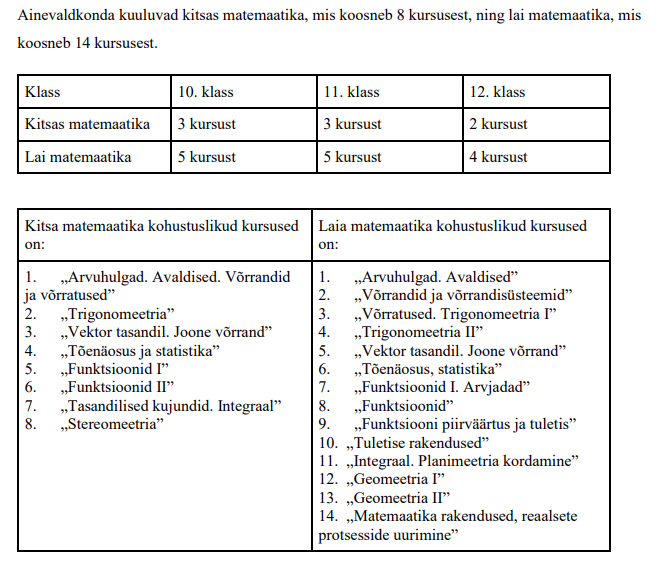
§ 10. Arvestuslike kirjalike tööde hindamine
(1) Hindamisel võetakse aluseks järgmine protsendiskaala:
1) 90–100% punktide arvust – hinne «5»;
2) 70–89% punktide arvust – hinne «4»;
3) 50–69% punktide arvust – hinne «3»;
4) 25–49% punktide arvust – hinne «2»;
5) 0–24% punktide arvust – hinne «1».
Loeme flash sisu faili blink.hex:
avrdude -v -V -c arduino -p atmega328p -P /dev/cu.usbmodem1201 -U flash:r:blink.hex:i
Kirjutame failisisu blink.hex arduino flash mälusse:
avrdude -v -V -c arduino -p atmega328p -P /dev/cu.usbmodem1201 -U flash:w:blink.hex:i
Loeme eeprom sisu faili eeprom-blink.hex:
avrdude -v -V -c arduino -p atmega328p -P /dev/cu.usbmodem1201 -U eeprom:r:blink.hex:i
Kirjutame failisisu eeprom-blink.hex arduino eeprom mälusse:
avrdude -v -V -c arduino -p atmega328p -P /dev/cu.usbmodem1201 -U eeprom:w:blink.hex:i
Kompileerime hello.asm faili:
;hello.asm
; turns on an LED which is connected to PB5 (digital out 13)
.include "./m328Pdef.inc"
ldi r16,0b11111111
out DDRB,r16
out PortB,r16
Start:
rjmp Startavra hello.asm
Laadime kompileeritud hex faili hello.hex kivi peale flash mälu osasse:
avrdude -v -V -c arduino -p atmega328p -P /dev/cu.usbmodem1201 -U flash:w:hello.hex:i
After many-many hours solution was not in fluend side but in fluent-bit side
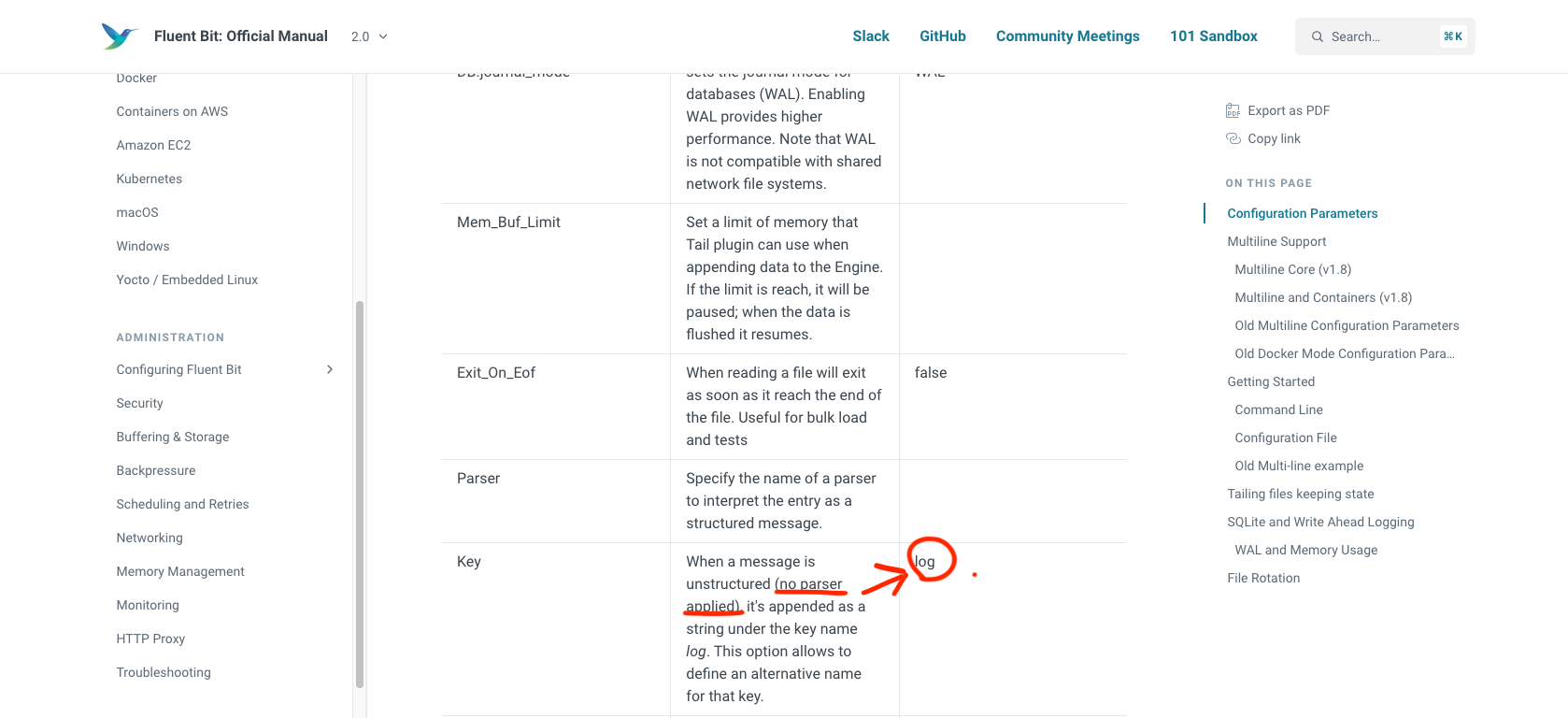
Kuna mul oli jube segadus, kuidas Avita gümnaasiumikursuste õpikuid organiseerib, siis endale siinkohal väike spikker, mille ma sain siit.
docker run -e SSL_SUBJECT="example.com" paulczar/omgwtfssl
https://github.com/paulczar/omgwtfsslKui ma hakkan mõtisklema, kes ma inimesena olen ja mida minult ootab õpetajaroll, siis hetkel on need veel kaks täiesti erinevat planeeti. Miks ma ütlen “veel”. Sest umbes kaks aastat tagasi olid need veel kaks erinevat galaktikat. Aasta ülikoolis on antud lõhet juba korralikult vähendanud.
Ligi kaks aastat tagasi olin ma kohutav lapsevanem õpetajana. Pean siinkohal silmas lapsevanemat, kes kodus peaks oma last õppimises aitama ja juhendama. Ma olin närviline, ma ei mõistnud, miks laps koolis midagi tegemata on jätnud või miks ta kodus minu juhendamisel mõne asjaga hakkama ei saa. Tihti tõstsin ka häält. Lapse motiveerimiseks kasutasin suurema osa ajast hirmutamist, mis päädis sellega, et ma lõhkusin ta nutitelefoni ja tõin talle nuputelefoni asemele.
Kui ma nüüd proovin analüüsida, miks ma selliselt käitusin, siis üks põhjus võib-olla on enda lapsepõlves kogetu ja eeskujud.
Kui ma nüüd proovin mõtiskleda teemal, mida ootab minult õpetaja roll. Üks oluline loetelu on isikuomadused, mis on kirjas õpetaja kutsestandardis.
Ma usun, et selle osaga mul ei ole kõige hullem. Õppijana saan ma sellega hakkama. Oma igapäevatöös (IT-spetsialistina) saan ma enesejuhtimisega samuti hakkama. Kindlasti on siinkohal ka arenguruumi, kuid ma leian, et mul on olulisemaid isikuomadusi, mida eelisjärjekorras luubi alla võtta.
Ma ise arvan, et antud isikuomadusega ei ole väga halvasti. Oma praegusel positsioonil (tööalaselt) olen piisavalt ettevõtlik. Samuti oma ühe suurema hobi (langevarjundus) raames olen samuti üsna aktiivselt ettevõtlik erinevates rollides.
Kui ma isikuomaduste loetelu vaatasin, siis tundus mulle ennast esmapilgul vaadates olukord üsna nutune. Praegu aga olen juba kolmanda punkti juures ja mulle tundub, et siin ma olen endaga isegi täiesti rahul. Kindlasti saab paremini, aga ma leian, et ma olen nii era- kui ka tööelus piisavalt vastutustundlik.
Ma arvan, et enesekindlus on seotud, kui mugavalt ma ennast mingis domeenis tunnen. Kui ma pean rääkima mingil teemal, kus minu teadmised on kesised, siis loomulikult olen ma ebakindel. Ja loomulikult vastupidi – olles mingis teemas väga kodus, tunnen ma ennast nagu kala vees. Siit saab järeldada ainult seda, et õpetajana tuleb ennast õpetatavas aines ja eelkõige õpetatavas aineteemas spetsialistiks teha.
Nii ja naa. Tihti seostatakse loomingulisust millegi uue välja mõtlemisega. Näiteks mõne teose loomisega. Siinkohal oleks ma lootusetu. Kui aga läheneda teise nurga alt, et loomine on ka olemasolevate asjade tark kombineerimine, siis ma usun, et minu puhul pole lootus kadunud. Ka minu praegusel töökohal on selline kombineerimise loomingulisus väga vajalik ja ennast kiites võin tõdeda, et tuleb vahel välja küll. Lausa nii hästi, et üsna viisakas tööandja on selle eest nõus päris korraliku raha maksma. Aga, et mitte liiga uhkeks minna, siis ma usun, et õpetaja kontekstis on mul kindlasti arenguruumi.
Ütlen ausalt – siin on arenguruumi. Uskuge, ma proovin. Lihtsalt juurdunud vaated on nii sisse kulunud ja praegune ühiskond muutub nii kiiresti, et väga raske on kaasa minna, kui selle nimel eraldi vaeva ei näe. Ja kuidas sa harjutad sallivust? Oma mõttemaailma muutmist?
Ma usun, et suurem osa inimestel on empaatiavõime olemas. Ilmselt ka minul. Kindlasti ma ei ole kõige suurema empaatiavõimega, aga ma ise väga loodan, et üle kriitilise taseme mul seda siiski jagub.
Ma ei teagi, kas ausus on isikuomadus. Kindlasti on probleem, kui sa oled lausvalelik e lausa haiglaslikult valetaja. Ma ei saa väita, et ma pole elus valetanud (kas sina saad?), aga ma ei arva, et mul aususega probleem oleks. Pigem, kui ma nüüd mõtlen, siis ma lasin tuttavatel ennast arvustada just antud töö jaoks. Pigem peeti mind vahel liiga ausaks.
Lähtudes teistelt saadud tagasisidest, siis võiks ütelda, et olen positiivse ellusuhtumisega. Kui ma nüüd päris aus olen, siis on mul siiski vahel halb omadus keerulistes olukordades asju väga mustas valguses näha. Aga see on saladus ja pigem jääme selle juurde, kuidas teised mind tajuvad.
Teine huvitav võrdluskoht on enda võrdlemine õpetajaeetika koodeksiga.
No siin on ikka minna veel. Ja ma pole kindel kas ma lõpuni jõuan ja kas ma üldse lõpuni tahan jõuda. Mulle tundub, et kui olla väärikas sellel moel, mis on välja toodud õpetajaeetika koodeksis
“Väärikus tähendab, et kõikidel inimestel on võrdsed õigused, olenemata nende soost, päritolust,rahvusest, vanusest, usust, seksuaalsest orientatsioonist, vaadetest ja võimetest. Õpetaja on salliv inimeste erisuste, teiste kultuuride ning tavade suhtes.Õpetaja austab oma partnereid ja toimib taktitundeliselt. Õpetaja märkab ahistamist ja sekkub selle tõkestamiseks. Tal on kohustus vastu hakata inimväärikust kahjustavatele muudatustele hariduselus.”
Ma peaaegu olen nõus, aga las ta jääb. Püüan õpilaste ees olla väärikas.
Tulenevalt oma põhikoolikogemusest pean ma õiglast õpetajat väga oluliseks. Isegi kui sa ei olnud võib-olla viieline või olid sa vähemkindlustatud perest, siis oli vähemalt õiglase õpetaja tunnis olla inimlik. Kindlasti on see üks omadus, millele ma enda puhul ka rõhuda sooviksin. Ma tean, et sa võid nüüd viidata minu eelmisele punktile, kus ma rääkisin, et mul võib olla väärikusega probleeme ja see võib õiglusega tõesti seotud olla. Samas tean ma mitut väga õiglast õpetajat, keda ma tõesti imetlen. Samas antud kontekstis on nad väga vääritud.
Kui ma antud osa üle mõtisklesin, siis esialgu soovisin olla hirmus originaalne ja mõelda väga suurelt. Peale suure segaduse peas, mida ma formuleerida ei suutnud, naasin reaalsusesse ja püüan oma visiooni, mis on minu peas täna, siinkohal selgesõnaliselt kirja panna.
2017 aastal läbiviidud uuringus IT oskuste arendamine Eesti koolides (Kori jt. 2019) selgus, et matemaatika ja informaatika lõimimine on oluline ja antud valdkonnas annaks rohkem ära teha. Kuna minu eriala on matemaatika- ja informaatika õpetaja, siis ma leian, et minu eesmärk on mõlema kõnealuse aine lõimimine ja õpetamine viisil, kus ma kasutan informaatikat matemaatika õpetamisel ja vastupidi.
Lisaks tooksin ka välja ühe nn alamvisiooni informaatikas. Informaatika on lai mõiste. Mina sooviksin informaatikaõpetajana keskenduda just programmeerimise õpetamisele.
Kasutatud kirjandus
Kori, K., Beldman, P., Tõnisson E,. Luik P,. Suviste R,. Siiman L,. Pedaste, M. (2019). IT oskuste arendamine Eesti koolides.
https://wise.com/documents/IT%20oskuste%20arendamine%20Eesti%20koolides.pdf (14.09.2021).

Õppeaines “Informaatika koolis” viimase postitusena tuleb siia minu retsensioon Janekile. Janeki õpimapp asub aadressil https://janekpress.weebly.com/blog.
Janek on lisaks ainega seotud postitustele lisanud ka mõned teemavälised postitused (mida oli ka huvitav lugeda), seetõttu pidin natukene rohkem vaeva nägema, et kontrollida, kas kõik vajalikud postitused on olemas. Olid.
Teemasid on kajastatud erineva põhjalikusega. Nagu Janek ka ise oma kokkuvõtvas videos mainib, siis näiteks ekraanivideo tegemine oli üks tema lemmikutest, mida on ka näha antud postituse käsitluse põhjalikusest.
Samuti meeldis mulle digitahvlite postitus, kus sain ka enda jaoks ideid.
Üldiselt olid kõik vajalikud postitused piisavalt käsiteltud ja põnev lugeda. Asjade interneti ja VR postituse juures oli ka nõutud video, mida ma ei leidnud.
Janek on kenasti ka oma kokkuvõttes välja toonid, mida ta antud aine raamis õppis. Mulle meeldis eriti, et Janek lõi õpimapi keskkonna ja ta arvas, et seda on ka muul otstarbel asjalik kasutada.
Keskkonna kujundus ja illustratsioonid mind kuidagi ei häirinud. Rõhutan, et ma ei tea kujundusest ja kasutatavusest midagi. Samas, mina sain kenasti hakkama. Samuti oli keelekasutus minule kenasti vastuvõetav. Paaris kohas leidsin, ilmselt kiirustamisest tulnud, kirjavigu.
Kokkuvõttes arvan, et see tunnike, mis ma Janeki õpimapis kolasin oli väärt ajakasutus!