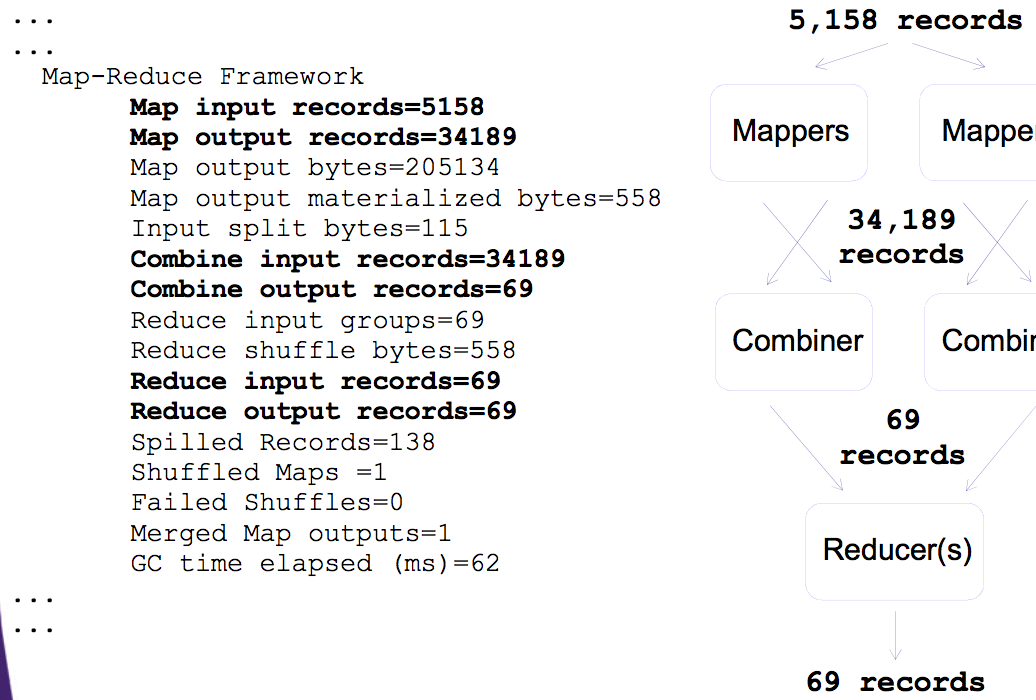
Let’s create two very simple log files. Into log1.txt file lets put in example users problems log data and into log2.txt file solutions log data
log1.txt:
user1 | 2014-09-23 | error message 1
user2 | 2014-09-23 | error message 2
user3 | 2014-09-23 | error message 3
user4 | 2014-09-23 | error message 1
user5 | 2014-09-23 | error message 2
user6 | 2014-09-23 | error message 12
user7 | 2014-09-23 | error message 11
user1 | 2014-09-24 | error message 1
user2 | 2014-09-24 | error message 2
user3 | 2014-09-24 | error message 3
user4 | 2014-09-24 | error message 10
user1 | 2014-09-24 | error message 17
user2 | 2014-09-24 | error message 13
user1 | 2014-09-24 | error message 1
log2.txt:
user1 | support2 | solution message 1
user2 | support1 | solution message 2
user3 | support2 | solution message 3
user1 | support1 | solution message 4
user2 | support2 | solution message 5
user4 | support1 | solution message 6
user2 | support2 | solution message 7
user5 | support1 | solution message 8
Create two tables for datasets above:
hive> create table log1 (user STRING, date STRING, error STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘|’ STORED AS TEXTFILE;
OK
Time taken: 5.968 seconds
hive> LOAD DATA INPATH ‘/user/margusja/hiveinput/log1.txt’ OVERWRITE INTO TABLE log1;
Loading data to table default.log1
rmr: DEPRECATED: Please use ‘rm -r’ instead.
Moved: ‘hdfs://bigdata1.host.int:8020/apps/hive/warehouse/log1’ to trash at: hdfs://bigdata1.host.int:8020/user/margusja/.Trash/Current
Table default.log1 stats: [numFiles=1, numRows=0, totalSize=523, rawDataSize=0]
OK
Time taken: 4.687 seconds
hive> create table log2 (user STRING, support STRING, solution STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘|’ STORED AS TEXTFILE;
OK
Time taken: 0.997 seconds
hive> LOAD DATA INPATH ‘/user/margusja/hiveinput/log2.txt’ OVERWRITE INTO TABLE log2;
Loading data to table default.log2
rmr: DEPRECATED: Please use ‘rm -r’ instead.
Moved: ‘hdfs://bigdata1.host.int:8020/apps/hive/warehouse/log2’ to trash at: hdfs://bigdata1.host.int:8020/user/margusja/.Trash/Current
Table default.log2 stats: [numFiles=1, numRows=0, totalSize=304, rawDataSize=0]
OK
Time taken: 0.72 seconds
hive>
Now let’s make SQL over two datafile placed to HDFS storage using HIVE:
hive> select log1.user, log1.date, log1.error, log2.support, log2.solution from log2 join log1 on (log1.user = log2.user);
And result. We see now how two separated log file are joined together and now we can see in example that user2 has error message 2 in 2012-09-23 and support2 offered solution message 7.
user1 2014-09-23 error message 1 support2 solution message 1
user1 2014-09-23 error message 1 support1 solution message 4
user2 2014-09-23 error message 2 support1 solution message 2
user2 2014-09-23 error message 2 support2 solution message 5
user2 2014-09-23 error message 2 support2 solution message 7
user3 2014-09-23 error message 3 support2 solution message 3
user4 2014-09-23 error message 1 support1 solution message 6
user5 2014-09-23 error message 2 support1 solution message 8
user1 2014-09-24 error message 1 support2 solution message 1
user1 2014-09-24 error message 1 support1 solution message 4
user2 2014-09-24 error message 2 support1 solution message 2
user2 2014-09-24 error message 2 support2 solution message 5
user2 2014-09-24 error message 2 support2 solution message 7
user3 2014-09-24 error message 3 support2 solution message 3
user4 2014-09-24 error message 10 support1 solution message 6
user1 2014-09-24 error message 17 support2 solution message 1
user1 2014-09-24 error message 17 support1 solution message 4
user2 2014-09-24 error message 13 support1 solution message 2
user2 2014-09-24 error message 13 support2 solution message 5
user2 2014-09-24 error message 13 support2 solution message 7
user1 2014-09-24 error message 1 support2 solution message 1
user1 2014-09-24 error message 1 support1 solution message 4
Time taken: 34.561 seconds, Fetched: 22 row(s)
More cool things:
We can select only specified user:
hive> select log1.user, log1.date, log1.error, log2.support, log2.solution from log2 join log1 on (log1.user = log2.user) where log1.user like ‘%user1%’;
user1 2014-09-23 error message 1 support2 solution message 1
user1 2014-09-23 error message 1 support1 solution message 4
user1 2014-09-24 error message 1 support2 solution message 1
user1 2014-09-24 error message 1 support1 solution message 4
user1 2014-09-24 error message 17 support2 solution message 1
user1 2014-09-24 error message 17 support1 solution message 4
user1 2014-09-24 error message 1 support2 solution message 1
user1 2014-09-24 error message 1 support1 solution message 4
Time taken: 31.932 seconds, Fetched: 8 row(s)
We can query by date:
hive> select log1.user, log1.date, log1.error, log2.support, log2.solution from log2 join log1 on (log1.user = log2.user) where log1.date like ‘%2014-09-23%’;
user1 2014-09-23 error message 1 support2 solution message 1
user1 2014-09-23 error message 1 support1 solution message 4
user2 2014-09-23 error message 2 support1 solution message 2
user2 2014-09-23 error message 2 support2 solution message 5
user2 2014-09-23 error message 2 support2 solution message 7
user3 2014-09-23 error message 3 support2 solution message 3
user4 2014-09-23 error message 1 support1 solution message 6
user5 2014-09-23 error message 2 support1 solution message 8
Now lets forward our awesome join sentence to the next table – log3 where we are going to hold our joined data
hive> create table log3 (user STRING, date STRING, error STRING, support STRING, solution STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘ \t’ STORED AS TEXTFILE;
hive> insert table log3 select log1.user, log1.date, log1.error, log2.support, log2.solution from log2 join log1 on (log1.user = log2.user)
And now we cat use very simple sql to get data:
hive> select * from log3;
OK
user1 2014-09-23 error message 1 support2 solution message 1
user1 2014-09-23 error message 1 support1 solution message 4
user2 2014-09-23 error message 2 support1 solution message 2
user2 2014-09-23 error message 2 support2 solution message 5
user2 2014-09-23 error message 2 support2 solution message 7
user3 2014-09-23 error message 3 support2 solution message 3
user4 2014-09-23 error message 1 support1 solution message 6
user5 2014-09-23 error message 2 support1 solution message 8
user1 2014-09-24 error message 1 support2 solution message 1
user1 2014-09-24 error message 1 support1 solution message 4
user2 2014-09-24 error message 2 support1 solution message 2
user2 2014-09-24 error message 2 support2 solution message 5
user2 2014-09-24 error message 2 support2 solution message 7
user3 2014-09-24 error message 3 support2 solution message 3
user4 2014-09-24 error message 10 support1 solution message 6
user1 2014-09-24 error message 17 support2 solution message 1
user1 2014-09-24 error message 17 support1 solution message 4
user2 2014-09-24 error message 13 support1 solution message 2
user2 2014-09-24 error message 13 support2 solution message 5
user2 2014-09-24 error message 13 support2 solution message 7
user1 2014-09-24 error message 1 support2 solution message 1
user1 2014-09-24 error message 1 support1 solution message 4
Time taken: 0.075 seconds, Fetched: 22 row(s)
hive>