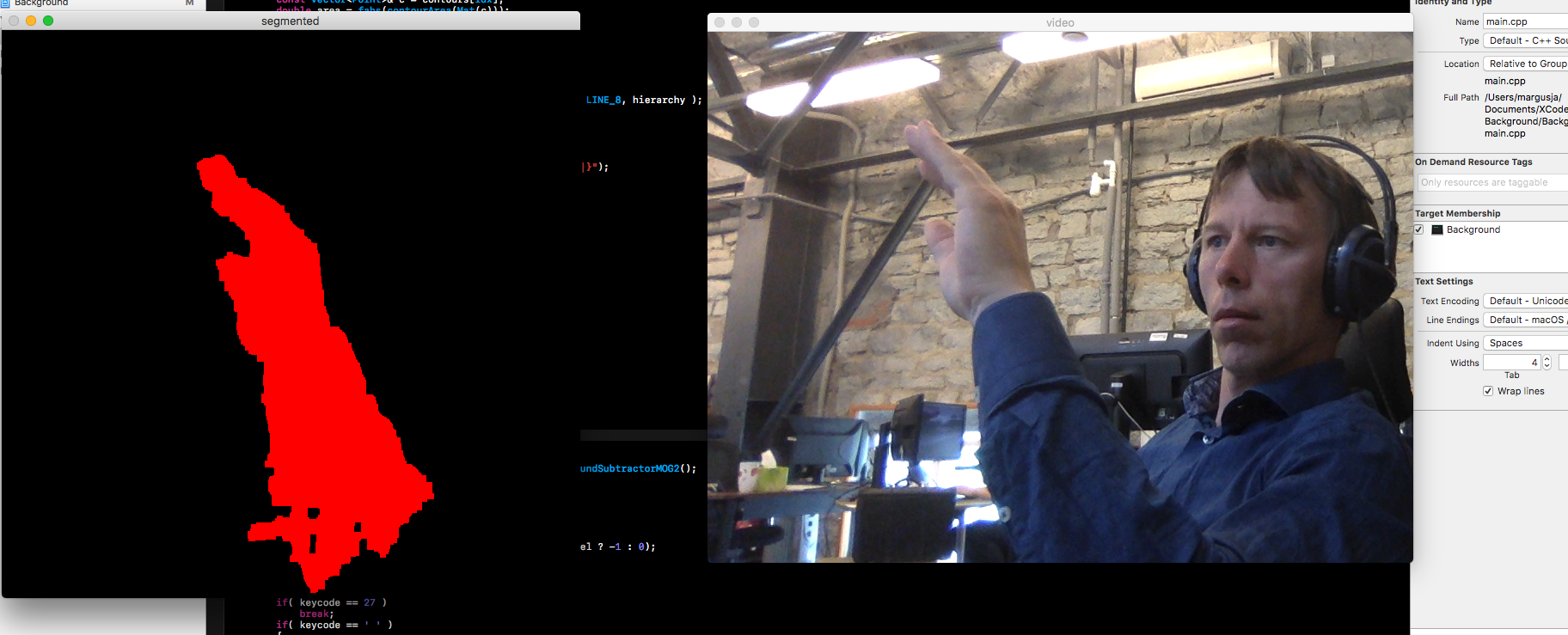
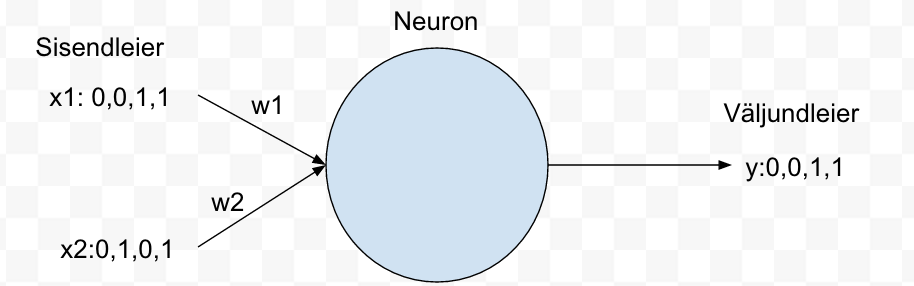
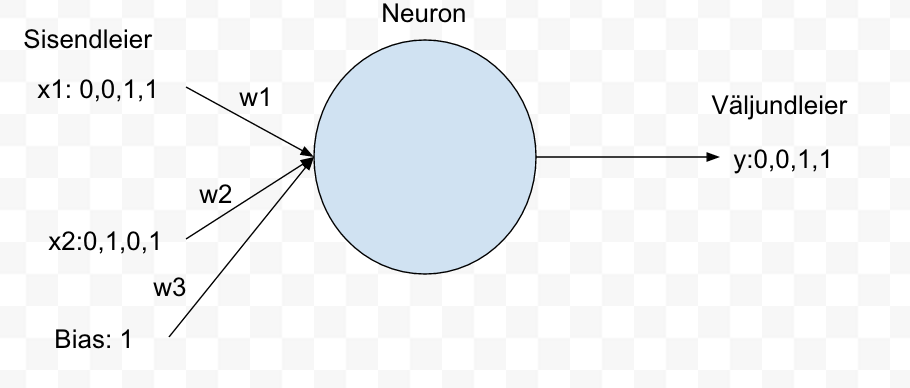
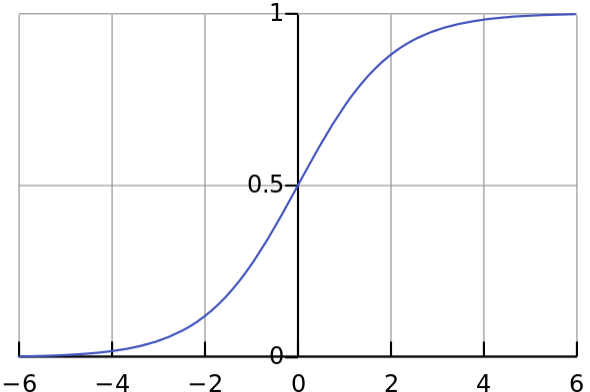
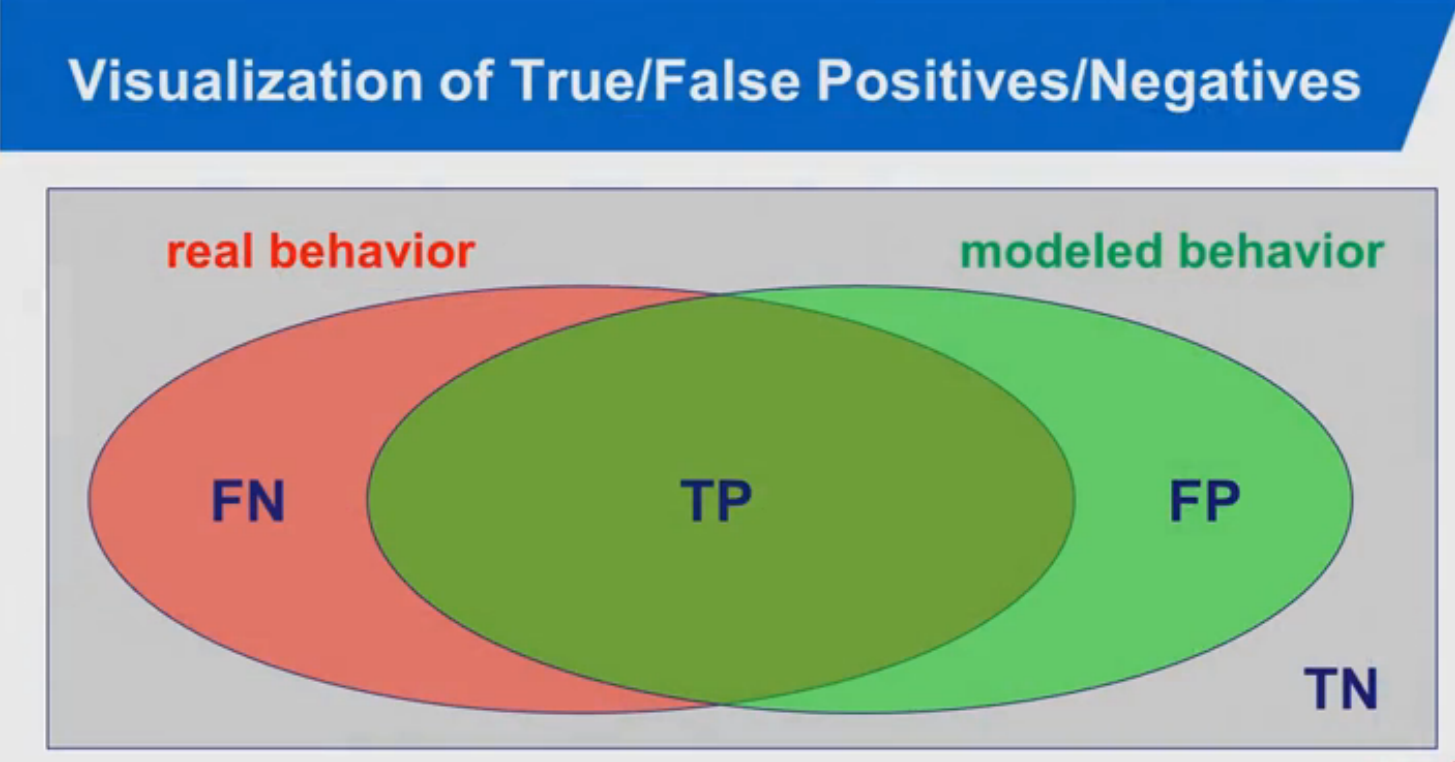
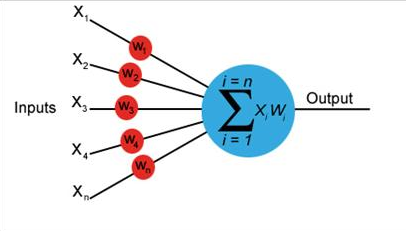
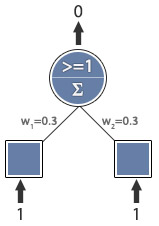
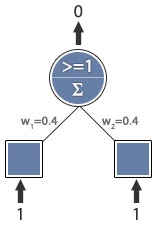
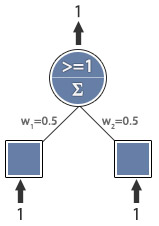
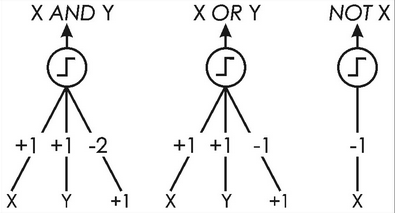
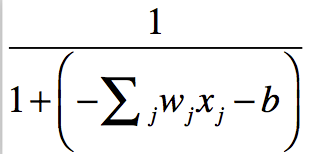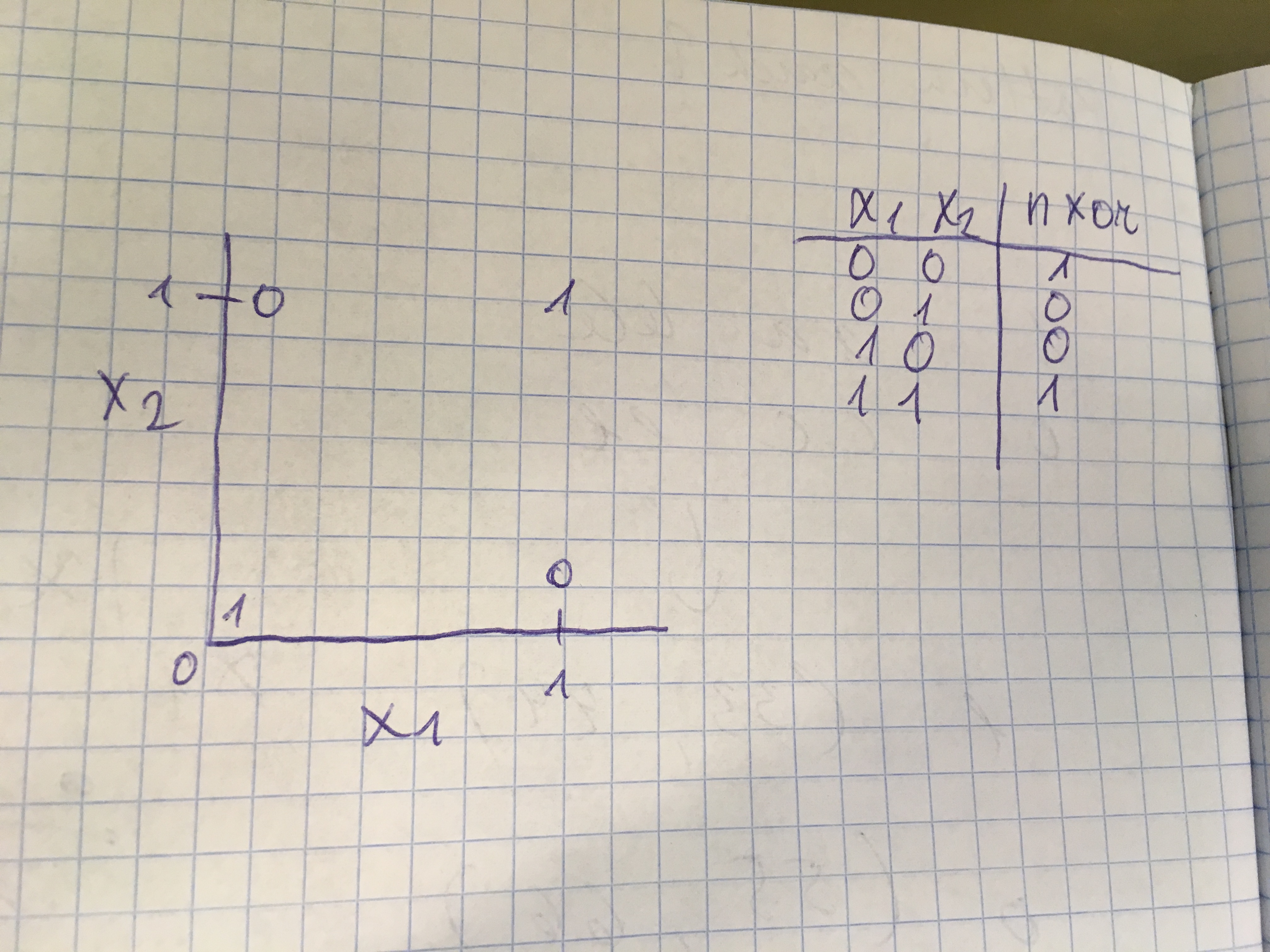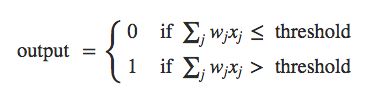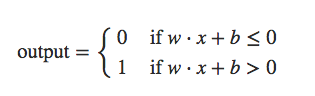I have example picture
Now I converted it in to 28×28 image

ImageMagick:
Original:
[margusja@bigdata18 ~]$ identify seven_28_28.png
seven_28_28.png PNG 527×524 527×524+0+0 8-bit DirectClass 13KB 0.000u 0:00.000
[margusja@bigdata18 ~]$ convert seven_28_28.png -resize 28×28 seven_28_28_new.png
28×28 pixel image
[margusja@bigdata18 ~]$ identify seven_28_28_new.png
seven_28_28_new.png PNG 28×28 28×28+0+0 8-bit DirectClass 1.7KB 0.000u 0:00.000
Take image as a text
[margusja@bigdata18 ~]$ convert seven_28_28_new.png txt:-
0,0: (209,203,196,255) #D1CBC4 srgba(209,203,196,1)
1,0: (210,204,197,255) #D2CCC5 srgba(210,204,197,1)
2,0: (209,203,195,255) #D1CBC3 srgba(209,203,195,1)
3,0: (207,201,193,255) #CFC9C1 srgba(207,201,193,1)
4,0: (206,202,194,255) #CECAC2 srgba(206,202,194,1)
5,0: (210,205,197,255) #D2CDC5 srgba(210,205,197,1)
6,0: (210,205,198,255) #D2CDC6 srgba(210,205,198,1)
7,0: (203,198,195,255) #CBC6C3 srgba(203,198,195,1)
8,0: (191,187,189,255) #BFBBBD srgba(191,187,189,1)
9,0: (186,182,184,255) #BAB6B8 srgba(186,182,184,1)
10,0: (203,196,192,255) #CBC4C0 srgba(203,196,192,1)
11,0: (208,202,194,255) #D0CAC2 srgba(208,202,194,1)
12,0: (207,202,194,255) #CFCAC2 srgba(207,202,194,1)
13,0: (209,204,196,255) #D1CCC4 srgba(209,204,196,1)
14,0: (210,205,196,255) #D2CDC4 srgba(210,205,196,1)
15,0: (210,204,196,255) #D2CCC4 srgba(210,204,196,1)
16,0: (211,204,196,255) #D3CCC4 srgba(211,204,196,1)
17,0: (211,205,196,255) #D3CDC4 srgba(211,205,196,1)
18,0: (212,205,197,255) #D4CDC5 srgba(212,205,197,1)
19,0: (212,205,197,255) #D4CDC5 srgba(212,205,197,1)
20,0: (211,205,196,255) #D3CDC4 srgba(211,205,196,1)
21,0: (214,206,198,255) #D6CEC6 srgba(214,206,198,1)
22,0: (215,208,199,255) #D7D0C7 srgba(215,208,199,1)
23,0: (213,206,198,255) #D5CEC6 srgba(213,206,198,1)
24,0: (213,206,198,255) #D5CEC6 srgba(213,206,198,1)
25,0: (213,206,198,255) #D5CEC6 srgba(213,206,198,1)
26,0: (213,206,198,255) #D5CEC6 srgba(213,206,198,1)
27,0: (215,209,201,255) #D7D1C9 srgba(215,209,201,1)
…
0,27: (198,194,192,255) #C6C2C0 srgba(198,194,192,1)
1,27: (199,195,192,255) #C7C3C0 srgba(199,195,192,1)
2,27: (199,196,191,255) #C7C4BF srgba(199,196,191,1)
3,27: (195,193,189,255) #C3C1BD srgba(195,193,189,1)
4,27: (194,193,189,255) #C2C1BD srgba(194,193,189,1)
5,27: (196,194,191,255) #C4C2BF srgba(196,194,191,1)
6,27: (200,198,195,255) #C8C6C3 srgba(200,198,195,1)
7,27: (201,199,195,255) #C9C7C3 srgba(201,199,195,1)
8,27: (201,199,196,255) #C9C7C4 srgba(201,199,196,1)
9,27: (202,201,198,255) #CAC9C6 srgba(202,201,198,1)
10,27: (203,202,198,255) #CBCAC6 srgba(203,202,198,1)
11,27: (203,202,198,255) #CBCAC6 srgba(203,202,198,1)
12,27: (203,201,197,255) #CBC9C5 srgba(203,201,197,1)
13,27: (203,202,198,255) #CBCAC6 srgba(203,202,198,1)
14,27: (204,203,198,255) #CCCBC6 srgba(204,203,198,1)
15,27: (205,204,199,255) #CDCCC7 srgba(205,204,199,1)
16,27: (204,202,198,255) #CCCAC6 srgba(204,202,198,1)
17,27: (204,203,199,255) #CCCBC7 srgba(204,203,199,1)
18,27: (204,203,199,255) #CCCBC7 srgba(204,203,199,1)
19,27: (203,201,197,255) #CBC9C5 srgba(203,201,197,1)
20,27: (203,200,196,255) #CBC8C4 srgba(203,200,196,1)
21,27: (204,200,197,255) #CCC8C5 srgba(204,200,197,1)
22,27: (204,201,198,255) #CCC9C6 srgba(204,201,198,1)
23,27: (204,202,198,255) #CCCAC6 srgba(204,202,198,1)
24,27: (206,203,198,255) #CECBC6 srgba(206,203,198,1)
25,27: (208,204,200,255) #D0CCC8 srgba(208,204,200,1)
26,27: (207,204,200,255) #CFCCC8 srgba(207,204,200,1)
27,27: (209,207,203,255) #D1CFCB srgba(209,207,203,1)
More easily working data
[margusja@bigdata18 ~]$ convert seven_28_28_new.png -colorspace gray seven_28_28_gray.png
[margusja@bigdata18 ~]$ convert seven_28_28_gray.png txt:- | more | awk {‘print $1 ” ” substr($2, 2, 3)’}
0,0: 154
1,0: 156
2,0: 154
3,0: 150
4,0: 151
5,0: 157
6,0: 157
7,0: 146
8,0: 129
9,0: 121
10,0: 143
11,0: 152
12,0: 152
13,0: 155
14,0: 157
15,0: 156
16,0: 156
17,0: 157
18,0: 158
19,0: 158
20,0: 157
21,0: 160
22,0: 163
23,0: 160
24,0: 160
25,0: 160
26,0: 160
27,0: 164
…
0,27: 139
1,27: 141
2,27: 141
3,27: 136
4,27: 136
5,27: 138
6,27: 144
7,27: 146
8,27: 146
9,27: 149
10,27: 150
11,27: 150
12,27: 149
13,27: 150
14,27: 152
15,27: 154
16,27: 151
17,27: 152
18,27: 152
19,27: 149
20,27: 148
21,27: 149
22,27: 150
23,27: 151
24,27: 153
25,27: 155
26,27: 155
27,27: 159