Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate
Apache-zookeeper http://zookeeper.apache.org/doc/trunk/index.html
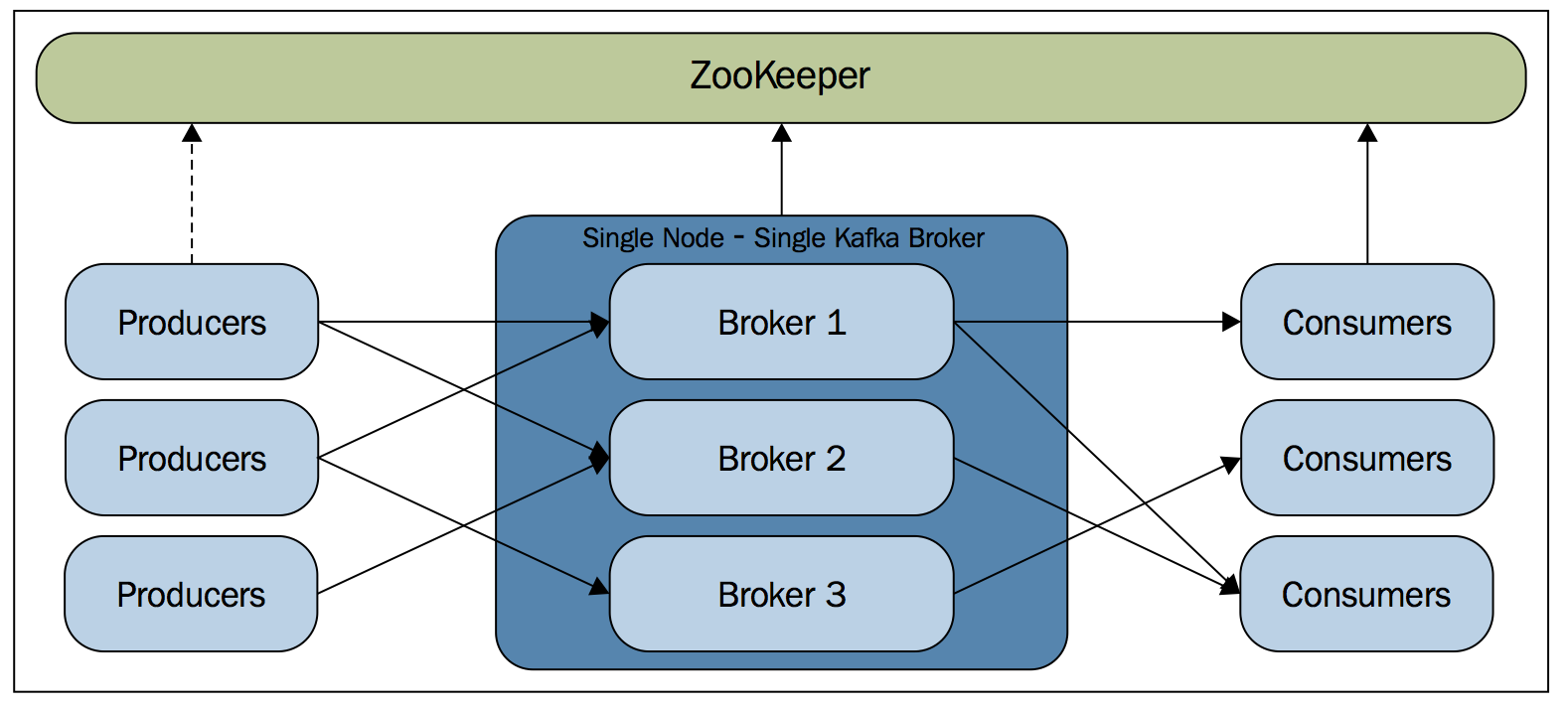
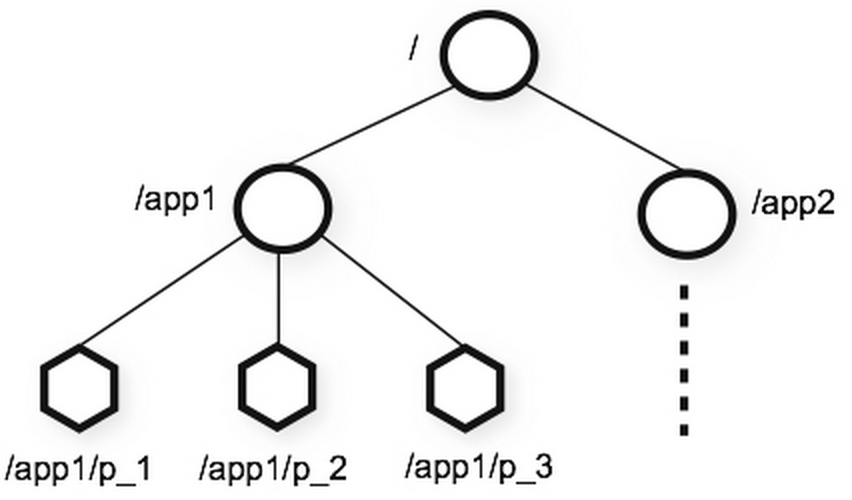
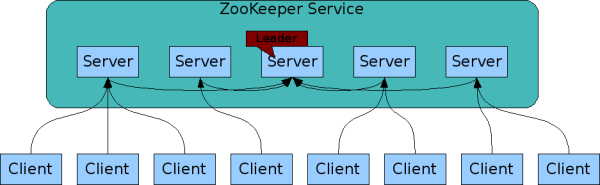
zookeeper on mõeldud hoidma teenuste seadistusi ja staatusi. Näiteks antud juhul on zookeeper serverites talletatud informatsioon, millised storm’i workerid on olemas.
Zookeeper teenus võib olla jaotunud eraldi serverite vahel, mis tagab kõrge veakindluse
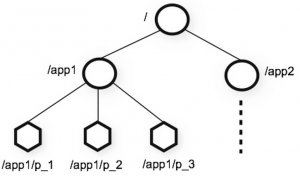
Zookeeper hoiab seadistusi hierarhias
Näiteks minu testkeskkonnas on üks storm supervisor e worker ja hetkel on üks topoloogia, see kajastub zookeeperis:
[root@sandbox ~]# /usr/lib/zookeeper/bin/zkCli.sh -server 127.0.0.1:2181
Connecting to 127.0.0.1:2181
…
[zk: 127.0.0.1:2181(CONNECTED) 1] ls /storm
[workerbeats, errors, supervisors, storms, assignments]
[zk: 127.0.0.1:2181(CONNECTED) 2] ls /storm/storms
[engineMessages5-2-1398208863]
[zk: 127.0.0.1:2181(CONNECTED) 3]
Zookeeper võimaldab stormi workereid dünaamiliselt juurde lisada. Storm master e nimbus oskab zookeeper serverist saadud info kohaselt workereid kasutada. Näiteks, kui mõni worker mingil põhjusel ei ole enam kättesaadav, siis zookeeper saab sellest teada, kuna heardbeate enam ei tule ja nimbus organiseerib voogude teekonnad ringi tekitades kadunud workeri asemel uue, eeldusel, et on kuhugile tekitada ehk on veel vabu supervisoreid.
Storm
Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
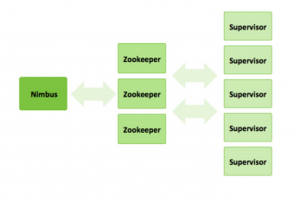
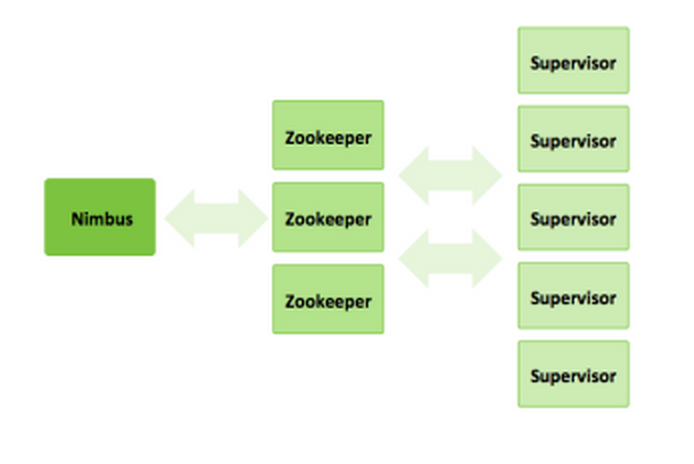
Nimbus
On master topoloogias, kes kordineerib, kasutades zookeeper-klastris olevat informatsiooni, storm-supervisorite töid ehk tagab voogude läbimise topoloogiast.
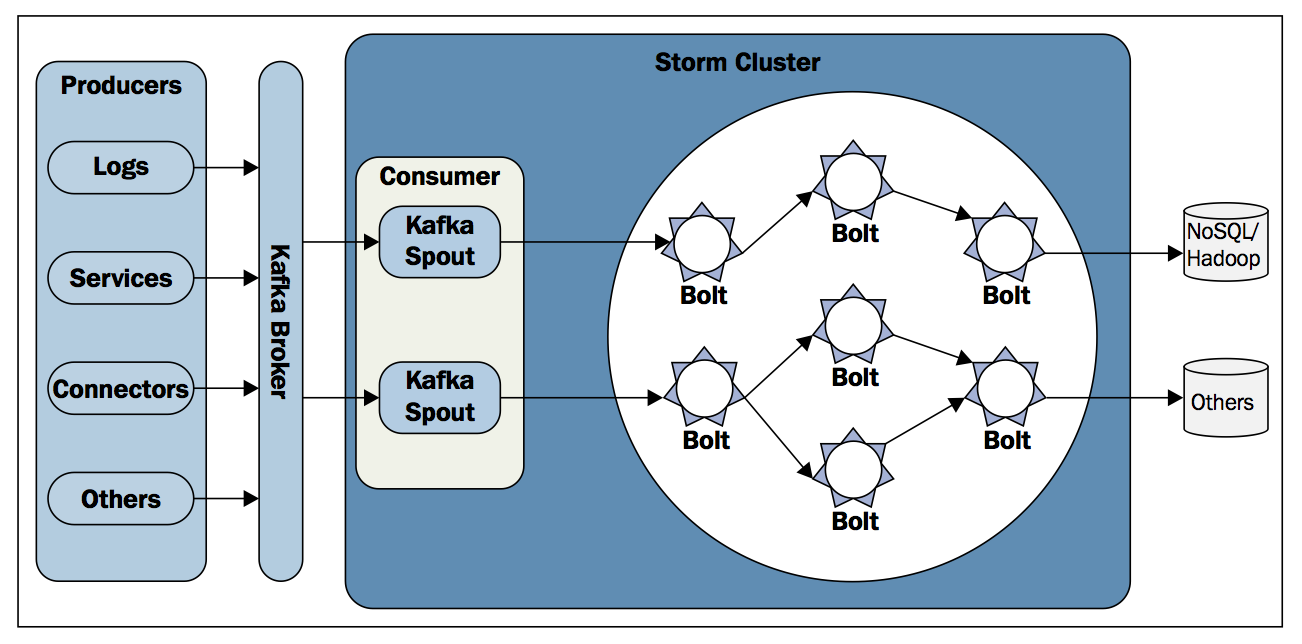
Storm-supervisor ehk worker
Spout(id) ja/või Bolt(id), kes kuuluvad mingisse topoloogiasse. Võivad asuda ühes füüsilises serveris või jaotatud erinevate füüsiliste serverite vahel. Zookeeperi abil annavad nimbusele teada oma olemasolust.
Storm-supervisor versus supervisor (http://supervisord.org/)
Etteruttavalt selgitan, et antud juhul on kasutusel kaks supervisor teenust, mis on erinevad ja mida on vaja lahti seletada.
storm-supervisor – strom worker
supervisor – Process Control System.
On kasutusel, tagamaks, et teenused – nimbus, zookeeper, storm_supervisor (worker) oleksid kiirelt taastatud, kui mõni neist peaks mingil põhjusel seiskuma.
Näide:
Hetkel on minu testkeskkonnas supervisor (mitte storm-supervisor) kontrolli all vajalikud storm teenused
[root@sandbox ~]# supervisorctl
storm-supervisor RUNNING pid 3483, uptime 2:14:55
storm_nimbus RUNNING pid 3765, uptime 1:44:23
storm_ui RUNNING pid 3672, uptime 2:13:09
zookeeper RUNNING pid 3484, uptime 2:14:55
supervisor>
Peatades näiteks storm_nimbus protsessi 3765
[root@sandbox ~]# kill -9 3765
supervisord logis:
2014-04-22 17:53:20,884 INFO exited: storm_nimbus (terminated by SIGKILL; not expected)
2014-04-22 17:53:20,884 INFO received SIGCLD indicating a child quit
2014-04-22 17:53:21,894 INFO spawned: ‘storm_nimbus’ with pid 4604
2014-04-22 17:53:22,898 INFO success: storm_nimbus entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
Kontrollime supervusord statust
supervisor> status
storm-supervisor RUNNING pid 3483, uptime 2:30:50
storm_nimbus RUNNING pid 4604, uptime 0:00:38
storm_ui RUNNING pid 3672, uptime 2:29:04
zookeeper RUNNING pid 3484, uptime 2:30:50
On näha, et just on uus protsess käivitatud.
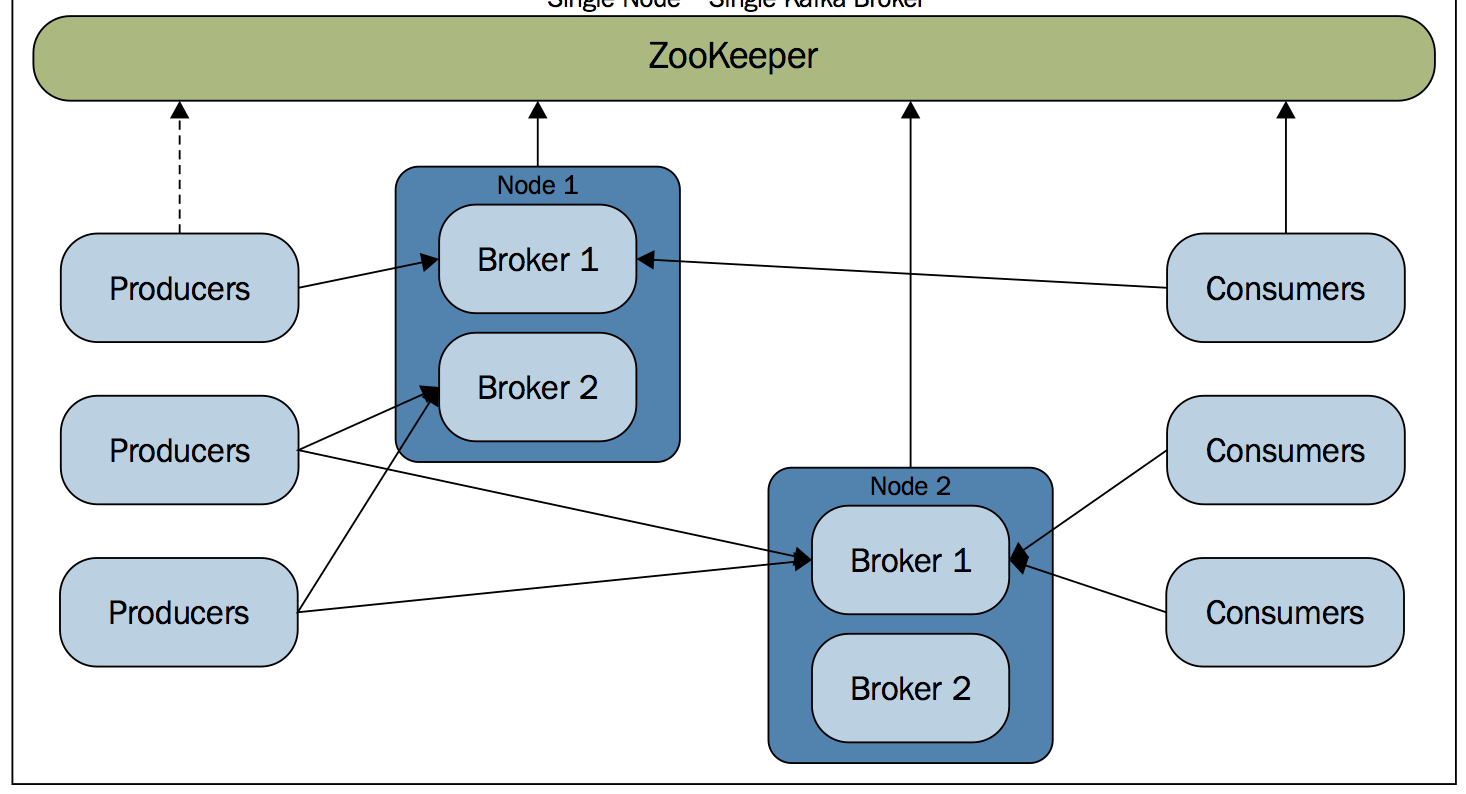
Toodangusüsteemides on soovitatav jaotada storm komponendid nii, et nimbus, ui ja üks zookeeper server on ühes masinas ja teistes asuvad zookeeper server ja storm-supervisor. Komplekte zookeeper-server ja storm-supervusor võib dünaamiliselt hiljem lisada.
Vahemärkusena, et tegelikult ei pea storm-supervisor ja zookeeper ühes füüsilises serveris asuma. Piisab, kui storm-supervisor teab, kus asub zookeeper server, et sinna oma staatus teatada.
Kui mingil põhjusel peaks üks storm-supervusor kättesaamatuks muutuma, siis nimbus saab sellest teada ja organiseerib topoloogia niimoodi, et voog oleks täielik.
Kui mingil põhjusel peaks muutuma mittekättesaadavaks nimbus, siis topoloogia on terviklik ja vood täätavad edasi.
Kui mingil põhjusel peaks muutuma korraga mittekättesaadavaks nimbus ja mõni hetkel topoloogias aktiivselt osalev storm-supervisor, siis tekib esimene reaalne probleem. Samas ka siin ei kao voos liikuvad andmed vaid õige seadistuse puhul iga topoloogias olev Spout registreerib voos olevate sõnumite mittekohalejõudmise ja kui nüüd taastatakse nimbus ja/või storm-supervisor, siis Spout saadab sõnumi uuesti.
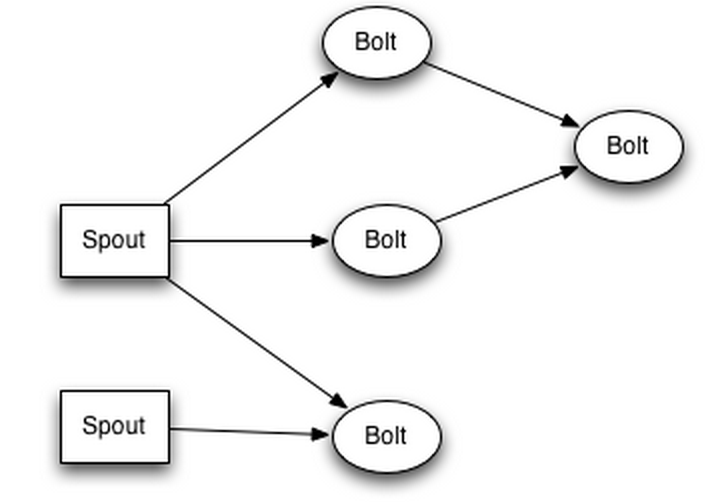
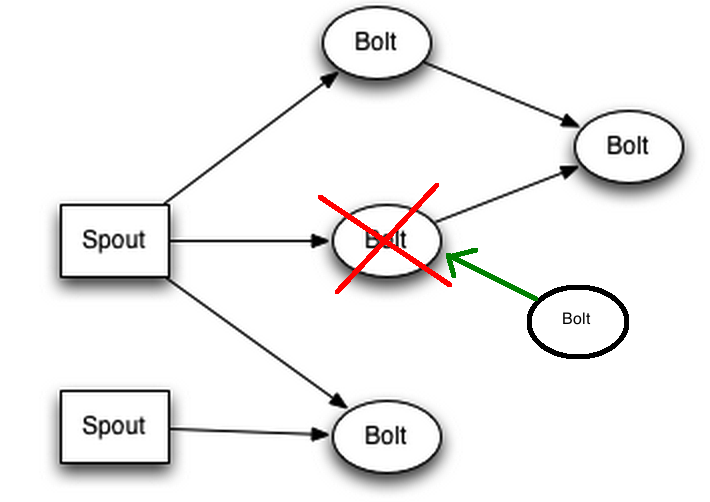
Kujutame ette, et meil on allpool toodud topoloogia
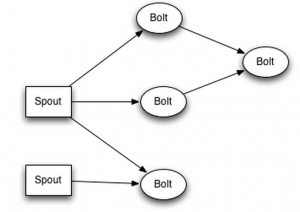
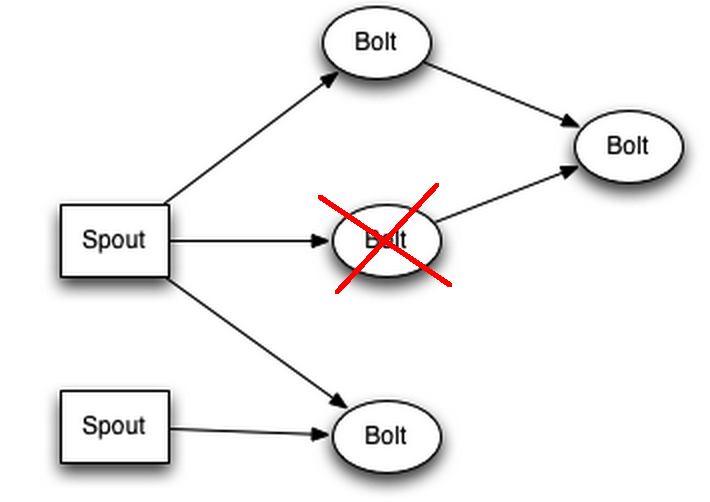
Kõik Bolt’d ja Spout’d asuvad eraldi masinates ehk on srorm-supervusor + zookeeper komplektid, siis juhul, kui peaks tekkima selline olukord
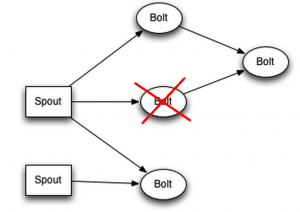
Siis nimbus saab sellest teada, sest zookeeperisse enam heartbeate ei tule ja nimbus üritab leida zookeeperi kaudu mõnda vaba serverit, kus on storm-supervisor.
Kui nüüd on olemas zookeeperi kaudu nimbusele teada mõni vaba storm-supervisor, siis topoloogia taastatakse. Kui mõnii sõnum ei jõudnud vahepeal kohale, kuna topoloogia ei olnud täielik, siis Spout on sellest teadlik ja saadab sõnumi uuesti.
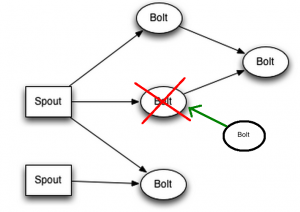
jätkub…