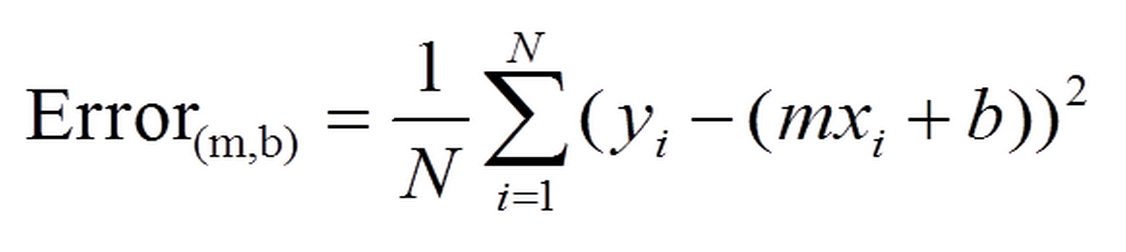a = x1*w1 + x2*w2 + x3*w3 … xn*wn
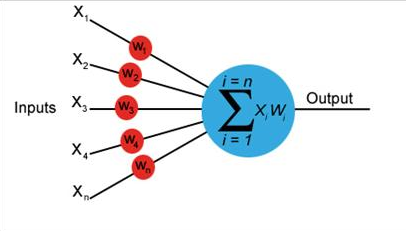
Feedforward newwork

In case we have matrix 8X8 we need 64 input

Threshold
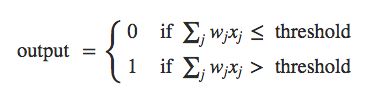
Bias
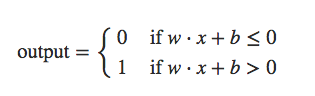
Learning
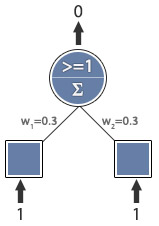
Learning rate = 0.1
Expected output = 1
Actual output = 0
Error = 1
Weight Update:
wi = r E x + wi
w1 = 0.1 x 1 x 1 + w1
�w2 = 0.1 x 1 x 1 + w2
New Weights:
w1 = 0.4
w2 = 0.4
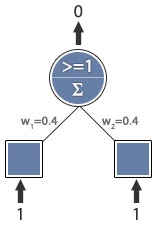
Learning rate = 0.1
Expected output = 1
Actual output = 0
Error = 1
Weight Update:
wi = r E x + wi
w1 = 0.1 x 1 x 1 + w1
�w2 = 0.1 x 1 x 1 + w2
New Weights:
w1 = 0.5
w2 = 0.5
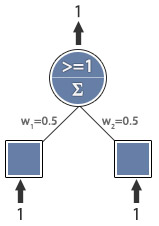
Learning rate = 0.1
Expected output = 1
Actual output = 1
Error = 0
No error,
training complete.
Lets implement it in Java
public class SimpleNN {
private double learning_rate;
private double expected_output;
private double actual_output;
private double error;
public static void main(String[] args) {
// initial
SimpleNN snn = new SimpleNN();
snn.learning_rate = 0.1;
snn.expected_output = 1;
snn.actual_output = 0;
snn.error = 1;
// inputs
int i1 = 1;
int i2 = 1;
// initial weigths
double w1 = 0.3;
double w2 = 0.3;
// loop untill we will get 0 error
while (true) {
System.out.println(“Error: “+ snn.error);
System.out.println(“w1: “+ w1);
System.out.println(“w2: “+ w2);
System.out.println(“actual output: “+ snn.actual_output);
w1 = snn.learning_rate * (snn.expected_output – snn.actual_output) * i1 + w1;
w2 = snn.learning_rate * (snn.expected_output – snn.actual_output) * i2 + w2;
snn.actual_output = w1 + w2;
if (snn.actual_output >= 0.99)
break;
}
System.out.println(“Final weights w1: “+ w1 + ” and w2: “+ w2);
}
}
Run it:
Error: 1.0
w1: 0.3
w2: 0.3
actual output: 0.0
Error: 1.0
w1: 0.4
w2: 0.4
actual output: 0.8
Error: 1.0
w1: 0.42000000000000004
w2: 0.42000000000000004
actual output: 0.8400000000000001
Error: 1.0
w1: 0.43600000000000005
w2: 0.43600000000000005
actual output: 0.8720000000000001
Error: 1.0
w1: 0.44880000000000003
w2: 0.44880000000000003
actual output: 0.8976000000000001
Error: 1.0
w1: 0.45904
w2: 0.45904
actual output: 0.91808
Error: 1.0
w1: 0.467232
w2: 0.467232
actual output: 0.934464
Error: 1.0
w1: 0.4737856
w2: 0.4737856
actual output: 0.9475712
Error: 1.0
w1: 0.47902848
w2: 0.47902848
actual output: 0.95805696
Error: 1.0
w1: 0.48322278399999996
w2: 0.48322278399999996
actual output: 0.9664455679999999
Error: 1.0
w1: 0.4865782272
w2: 0.4865782272
actual output: 0.9731564544
Error: 1.0
w1: 0.48926258176
w2: 0.48926258176
actual output: 0.97852516352
Error: 1.0
w1: 0.491410065408
w2: 0.491410065408
actual output: 0.982820130816
Error: 1.0
w1: 0.4931280523264
w2: 0.4931280523264
actual output: 0.9862561046528
Error: 1.0
w1: 0.49450244186112
w2: 0.49450244186112
actual output: 0.98900488372224
Final weights w1: 0.495601953488896 and w2: 0.495601953488896
So…Christopher CAN LEARN!!!
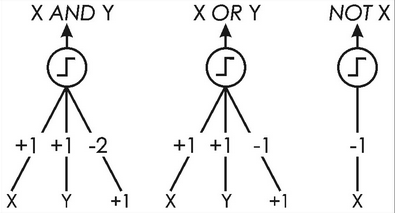
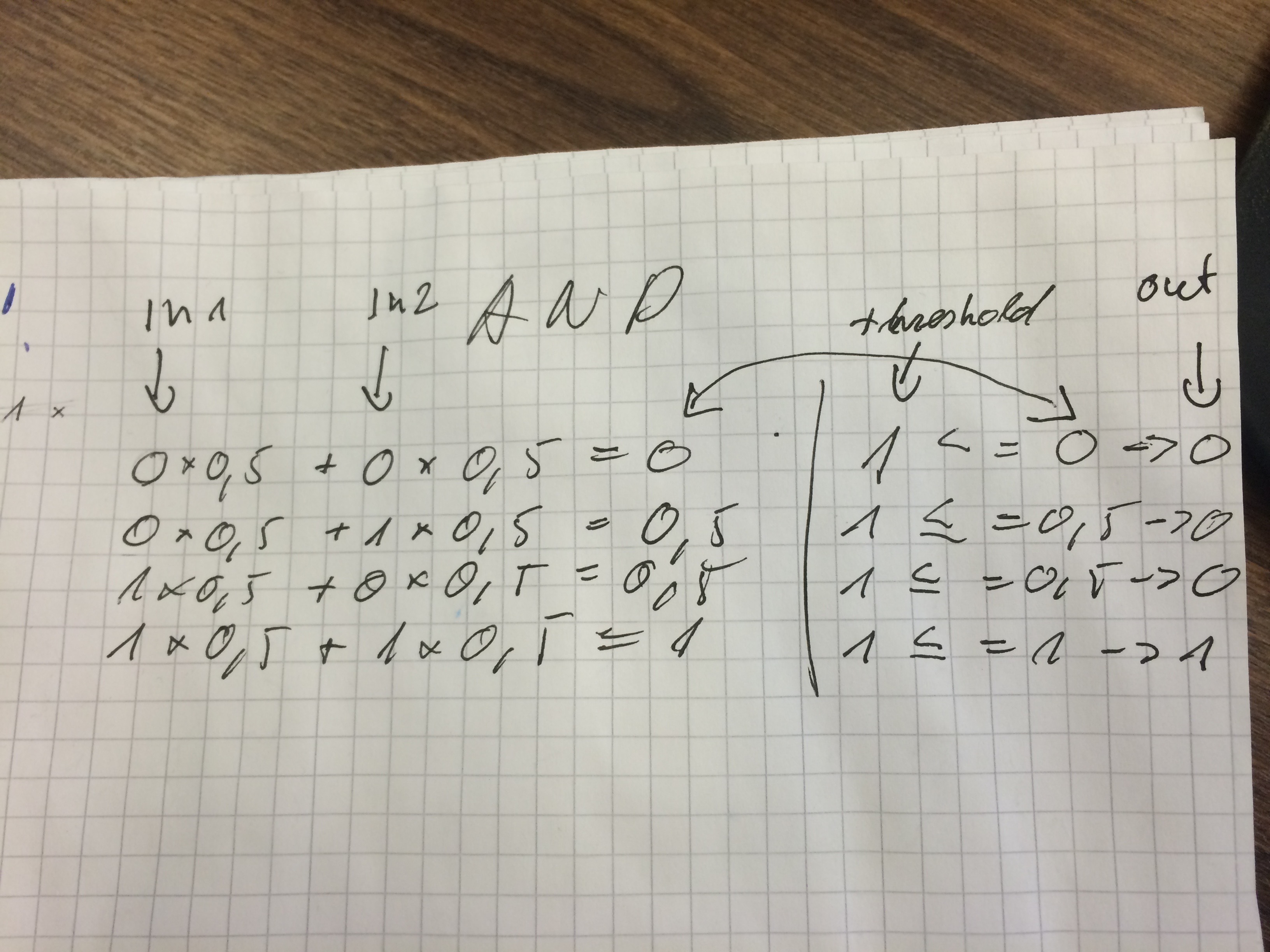
Neural network with AND logic.
0 & 0 = 0
0 & 1 = 0
1 & 0 = 0
1 & 1 = 1
Using neural network you can use only one perceptron
In paper calculated weights and AND logic
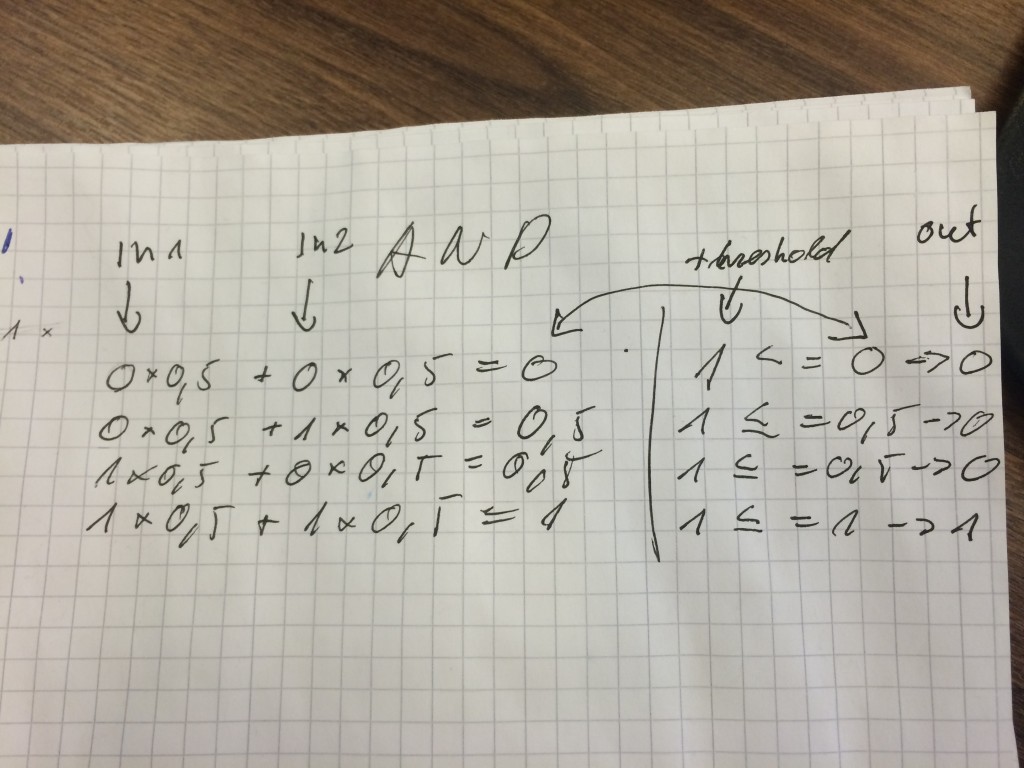
So we need to find weights fulfil conditions:
0 * w1 + 0 * w2 <= 1
0 * w1 + 1 * w2 <= 1
1 * w1 + 0 * w2 <= 1
1 * w1 + 1 * w2 = 1
Java code to implement this:
public class AndNeuronNet {
private double learning_rate;
private double threshold;
public static void main(String[] args) {
// initial
AndNeuronNet snn = new AndNeuronNet();
snn.learning_rate = 0.1;
snn.threshold = 1;
// AND function Training data
int[][][] trainingData = {
{{0, 0}, {0}},
{{0, 1}, {0}},
{{1, 0}, {0}},
{{1, 1}, {1}},
};
// Init weights
double[] weights = {0.0, 0.0};
snn.threshold = 1;
// loop untill we will get 0 error
while (true) {
int errorCount = 0;
for(int i=0; i < trainingData.length; i++){
System.out.println(“Starting weights: ” + Arrays.toString(weights));
System.out.println(“Inputs: ” + Arrays.toString(trainingData[i][0]));
// Calculate weighted input
double weightedSum = 0;
for(int ii=0; ii < trainingData[i][0].length; ii++) {
weightedSum += trainingData[i][0][ii] * weights[ii];
}
System.out.println(“Weightedsum in training: “+ weightedSum);
// Calculate output
int output = 0;
if(snn.threshold <= weightedSum){
output = 1;
}
System.out.println(“Target output: ” + trainingData[i][1][0] + “, ” + “Actual Output: ” + output);
// Calculate error
int error = trainingData[i][1][0] – output;
System.out.println(“Error: “+error);
// Increase error count for incorrect output
if(error != 0){
errorCount++;
}
// Update weights
for(int ii=0; ii < trainingData[i][0].length; ii++) {
weights[ii] += snn.learning_rate * error * trainingData[i][0][ii];
}
System.out.println(“New weights: ” + Arrays.toString(weights));
System.out.println();
}
System.out.println(“ErrorCount: “+ errorCount);
// If there are no errors, stop
if(errorCount == 0){
System.out.println(“Final weights: ” + Arrays.toString(weights));
System.exit(0);
}
}
}
}
Compile and run:
Starting weights: [0.0, 0.0]
Inputs: [0, 0]
Weightedsum in training: 0.0
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.0, 0.0]
Starting weights: [0.0, 0.0]
Inputs: [0, 1]
Weightedsum in training: 0.0
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.0, 0.0]
Starting weights: [0.0, 0.0]
Inputs: [1, 0]
Weightedsum in training: 0.0
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.0, 0.0]
Starting weights: [0.0, 0.0]
Inputs: [1, 1]
Weightedsum in training: 0.0
Target output: 1, Actual Output: 0
Error: 1
New weights: [0.1, 0.1]
ErrorCount: 1
Starting weights: [0.1, 0.1]
Inputs: [0, 0]
Weightedsum in training: 0.0
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.1, 0.1]
Starting weights: [0.1, 0.1]
Inputs: [0, 1]
Weightedsum in training: 0.1
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.1, 0.1]
Starting weights: [0.1, 0.1]
Inputs: [1, 0]
Weightedsum in training: 0.1
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.1, 0.1]
Starting weights: [0.1, 0.1]
Inputs: [1, 1]
Weightedsum in training: 0.2
Target output: 1, Actual Output: 0
Error: 1
New weights: [0.2, 0.2]
ErrorCount: 1
Starting weights: [0.2, 0.2]
Inputs: [0, 0]
Weightedsum in training: 0.0
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.2, 0.2]
Starting weights: [0.2, 0.2]
Inputs: [0, 1]
Weightedsum in training: 0.2
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.2, 0.2]
Starting weights: [0.2, 0.2]
Inputs: [1, 0]
Weightedsum in training: 0.2
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.2, 0.2]
Starting weights: [0.2, 0.2]
Inputs: [1, 1]
Weightedsum in training: 0.4
Target output: 1, Actual Output: 0
Error: 1
New weights: [0.30000000000000004, 0.30000000000000004]
ErrorCount: 1
Starting weights: [0.30000000000000004, 0.30000000000000004]
Inputs: [0, 0]
Weightedsum in training: 0.0
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.30000000000000004, 0.30000000000000004]
Starting weights: [0.30000000000000004, 0.30000000000000004]
Inputs: [0, 1]
Weightedsum in training: 0.30000000000000004
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.30000000000000004, 0.30000000000000004]
Starting weights: [0.30000000000000004, 0.30000000000000004]
Inputs: [1, 0]
Weightedsum in training: 0.30000000000000004
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.30000000000000004, 0.30000000000000004]
Starting weights: [0.30000000000000004, 0.30000000000000004]
Inputs: [1, 1]
Weightedsum in training: 0.6000000000000001
Target output: 1, Actual Output: 0
Error: 1
New weights: [0.4, 0.4]
ErrorCount: 1
Starting weights: [0.4, 0.4]
Inputs: [0, 0]
Weightedsum in training: 0.0
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.4, 0.4]
Starting weights: [0.4, 0.4]
Inputs: [0, 1]
Weightedsum in training: 0.4
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.4, 0.4]
Starting weights: [0.4, 0.4]
Inputs: [1, 0]
Weightedsum in training: 0.4
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.4, 0.4]
Starting weights: [0.4, 0.4]
Inputs: [1, 1]
Weightedsum in training: 0.8
Target output: 1, Actual Output: 0
Error: 1
New weights: [0.5, 0.5]
ErrorCount: 1
Starting weights: [0.5, 0.5]
Inputs: [0, 0]
Weightedsum in training: 0.0
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.5, 0.5]
Starting weights: [0.5, 0.5]
Inputs: [0, 1]
Weightedsum in training: 0.5
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.5, 0.5]
Starting weights: [0.5, 0.5]
Inputs: [1, 0]
Weightedsum in training: 0.5
Target output: 0, Actual Output: 0
Error: 0
New weights: [0.5, 0.5]
Starting weights: [0.5, 0.5]
Inputs: [1, 1]
Weightedsum in training: 1.0
Target output: 1, Actual Output: 1
Error: 0
New weights: [0.5, 0.5]
ErrorCount: 0
Final weights: [0.5, 0.5]
So what we did?
Basically we iterated over the training set until we found good weights to fulfil condition for all records in training set:
if (threshold <= input1[i] * weight1 + input2[i] * weight2) then (if 0 == target[1] done else error and loop again) else (if 1 == target[i] done else error and loop again)
With one perceptor we can solve boolean problems. In picture below you can see weights. Neural network can find them.