http://hive.apache.org/
The Apache Hive ™ data warehouse software facilitates querying and managing large datasets residing in distributed storage. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.
[root@vm24 ~]# yum install hive
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: ftp.hosteurope.de
* epel: ftp.lysator.liu.se
* extras: ftp.hosteurope.de
* rpmforge: mirror.bacloud.com
* updates: ftp.hosteurope.de
Setting up Install Process
Resolving Dependencies
--> Running transaction check
---> Package hive.noarch 0:0.12.0.2.0.6.1-101.el6 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
================================================================================================================================================================================================================================================================================
Package Arch Version Repository Size
================================================================================================================================================================================================================================================================================
Installing:
hive noarch 0.12.0.2.0.6.1-101.el6 HDP-2.0.6 44 M
Transaction Summary
================================================================================================================================================================================================================================================================================
Install 1 Package(s)
Total download size: 44 M
Installed size: 207 M
Is this ok [y/N]: y
Downloading Packages:
hive-0.12.0.2.0.6.1-101.el6.noarch.rpm | 44 MB 00:19
Running rpm_check_debug
Running Transaction Test
Transaction Test Succeeded
Running Transaction
Installing : hive-0.12.0.2.0.6.1-101.el6.noarch 1/1
Verifying : hive-0.12.0.2.0.6.1-101.el6.noarch 1/1
Installed:
hive.noarch 0:0.12.0.2.0.6.1-101.el6
Complete!
[root@vm24 ~]#
Olulisemad kataloogid, mis tekkisid (rpm -ql hive)
/usr/lib/hive/ – see peaks olema hive home
/var/lib/hive
/var/lib/hive/metastore
/var/log/hive
/var/run/hive
[root@vm24 ~]# su – hive
[hive@vm24 ~]$ export HIVE_HOME=/usr/lib/hive
[hive@vm24 ~]$ export HADOOP_HOME=/usr/lib/hadoop
[hdfs@vm24 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -mkdir /user/hive
[hdfs@vm24 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -mkdir /user/hive/warehouse
[hdfs@vm24 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -chmod g+w /tmp
[hdfs@vm24 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -chmod g+w /user/hive/warehouse
[hdfs@vm24 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -chown -R hive /user/hive/
[hdfs@vm24 ~]$
[hive@vm24 ~]$ /usr/lib/hive/bin/hive
Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path
[hive@vm24 ~]$
Ilmselt olen segamine ajanud hadoop ja hadoop-hdfs
[hive@vm24 ~]$ export HADOOP_HOME=/usr/lib/hadoop
[hive@vm24 ~]$ /usr/lib/hive/bin/hive
Error: JAVA_HOME is not set and could not be found.
Unable to determine Hadoop version information.
'hadoop version' returned:
Error: JAVA_HOME is not set and could not be found.
[hive@vm24 ~]$
[hive@vm24 ~]$ export JAVA_HOME=/usr
[hive@vm24 ~]$ /usr/lib/hive/bin/hive
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
Logging initialized using configuration in jar:file:/usr/lib/hive/lib/hive-common-0.12.0.2.0.6.1-101.jar!/hive-log4j.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/lib/hadoop/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/hive/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive>
Session on hive:
[hive@vm24 ~]$ wget https://hadoop-clusternet.googlecode.com/svn-history/r20/trunk/clusternet/thirdparty/data/ml-data.tar__0.gz
–2014-03-07 11:53:56– https://hadoop-clusternet.googlecode.com/svn-history/r20/trunk/clusternet/thirdparty/data/ml-data.tar__0.gz
Resolving hadoop-clusternet.googlecode.com… 2a00:1450:4001:c02::52, 173.194.70.82
Connecting to hadoop-clusternet.googlecode.com|2a00:1450:4001:c02::52|:443… connected.
HTTP request sent, awaiting response… 200 OK
Length: 4948405 (4.7M) [application/octet-stream]
Saving to: “ml-data.tar__0.gz”
100%[======================================================================================================================================================================================================================================>] 4,948,405 609K/s in 7.1s
2014-03-07 11:54:03 (681 KB/s) – “ml-data.tar__0.gz” saved [4948405/4948405]
[hive@vm24 ~]$
[hive@vm24 ~]$ tar zxvf ml-data.tar__0.gz
ml-data/
ml-data/README
ml-data/allbut.pl
ml-data/mku.sh
ml-data/u.data
ml-data/u.genre
ml-data/u.info
ml-data/u.item
ml-data/u.occupation
ml-data/u.user
ml-data/ub.test
ml-data/u1.test
ml-data/u1.base
ml-data/u2.test
ml-data/u2.base
ml-data/u3.test
ml-data/u3.base
ml-data/u4.test
ml-data/u4.base
ml-data/u5.test
ml-data/u5.base
ml-data/ua.test
ml-data/ua.base
ml-data/ub.base
[hive@vm24 ~]$
hive> CREATE TABLE u_data (
> userid INT,
> movieid INT,
> rating INT,
> unixtime STRING)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ‘\t’
> STORED AS TEXTFILE;
hive> LOAD DATA LOCAL INPATH ‘ml-data/u.data’
> OVERWRITE INTO TABLE u_data;
Copying data from file:/home/hive/ml-data/u.data
Copying file: file:/home/hive/ml-data/u.data
Loading data to table default.u_data
Table default.u_data stats: [num_partitions: 0, num_files: 1, num_rows: 0, total_size: 1979173, raw_data_size: 0]
OK
Time taken: 3.0 seconds
hive>
hive> SELECT COUNT(*) FROM u_data;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapred.reduce.tasks=
Starting Job = job_1394027471317_0016, Tracking URL = http://vm38:8088/proxy/application_1394027471317_0016/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1394027471317_0016
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2014-03-07 11:59:47,212 Stage-1 map = 0%, reduce = 0%
2014-03-07 11:59:57,933 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 11:59:58,998 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:00,094 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:01,157 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:02,212 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:03,268 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:04,323 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:05,378 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:06,434 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:07,489 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:08,573 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:09,630 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:10,697 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.14 sec
2014-03-07 12:00:11,745 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.14 sec
MapReduce Total cumulative CPU time: 5 seconds 140 msec
Ended Job = job_1394027471317_0016
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 5.14 sec HDFS Read: 1979386 HDFS Write: 7 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 140 msec
OK
100000
Time taken: 67.285 seconds, Fetched: 1 row(s)
hive>
Siin on ka näha, et hadoop arvutusosa tegeleb antud tööga(1394027471317_0016):
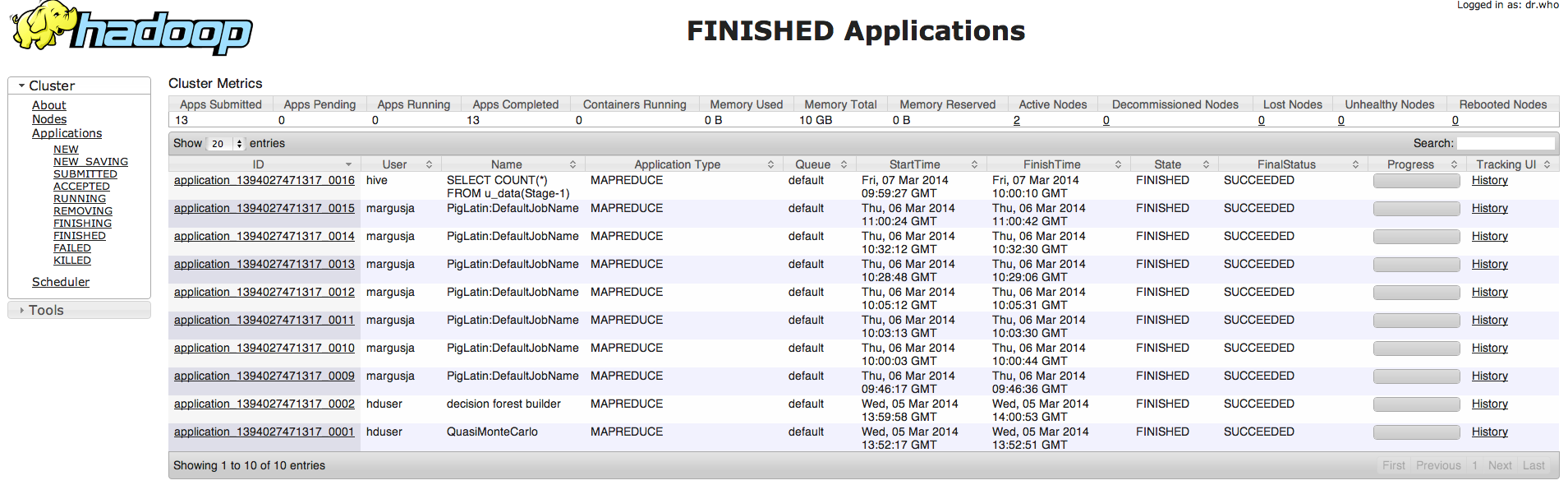
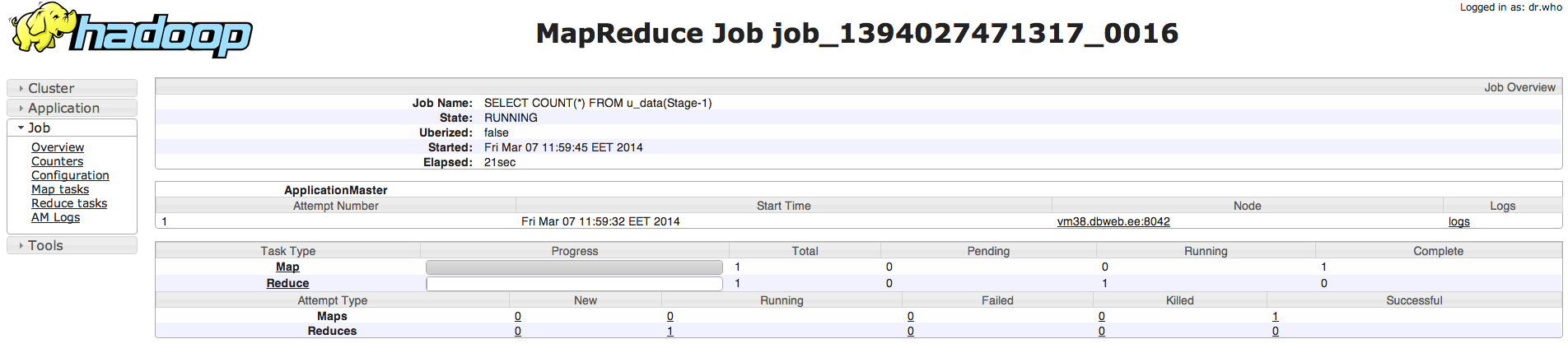
[hive@vm24 ~]$ hive –service hiveserver
Starting Hive Thrift Server
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/lib/hadoop/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/hive/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
…
Start Web UI
/etc/hive/conf/hive-site.xml
[hive@vm24 ~]$ hive –service hwi
14/03/11 15:14:57 INFO hwi.HWIServer: HWI is starting up
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/lib/hadoop/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/hive/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
14/03/11 15:14:59 INFO mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog
14/03/11 15:14:59 INFO mortbay.log: jetty-6.1.26
14/03/11 15:14:59 INFO mortbay.log: Extract /usr/lib/hive/lib/hive-hwi-0.12.0.2.0.6.1-101.war to /tmp/Jetty_0_0_0_0_9999_hive.hwi.0.12.0.2.0.6.1.101.war__hwi__4ykn6s/webapp
14/03/11 15:15:00 INFO mortbay.log: Started SocketConnector@0.0.0.0:9999
http://vm24:9999/hwi/
[hive@vm24 ~]$ hive –service metastore -p 10000
Starting Hive Metastore Server
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/lib/hadoop/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/hive/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
…
Eelnevalt teised hive teenused sulgeda, kuna praeguse seadistusega lukustatakse Derby andmebaas
Metastore