There is apache-spark. I installed it examined examples and run them. Worked. Now what?
One way is to go to linkedin and mark yourself now as the expert of spark and forget the topic.
Another way is to create a interesting problem and try to solve it. After that you may go to the linkedin and mark yourself as a expert 😉
So here is my prolem
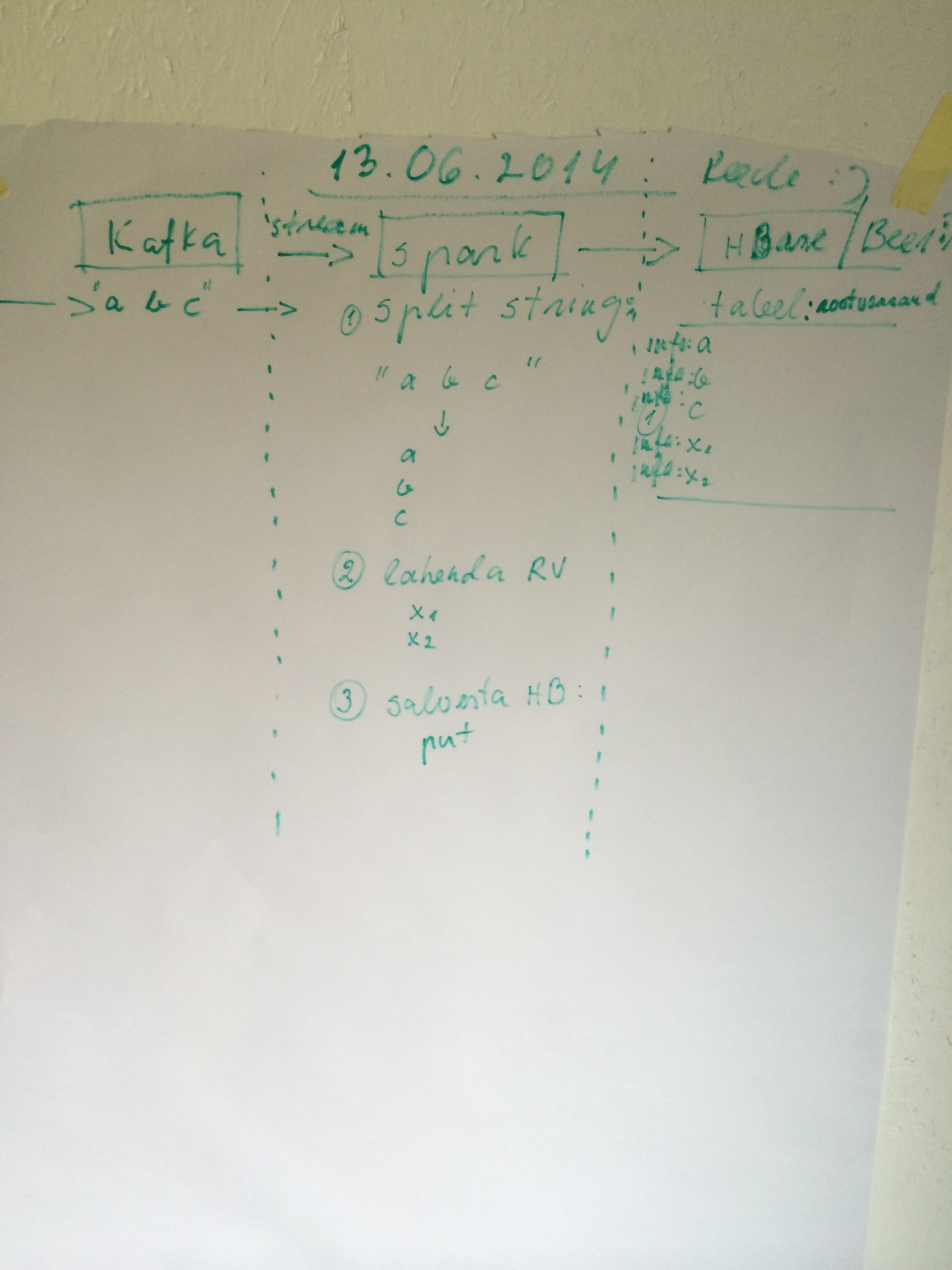
What do I have here. From the left to right. Apache-kafka is receives stream like string “a b c” thous are quadratic equation‘s (ax2 + bx + c = 0) input.
Apache-Spark is going to resolve quadratic equation and saves input parameters and results x1 and x2 to hbase.
The big picture

As you see now the day is much more interesting 🙂
On let’s jump into technology.
First I am going to create HBase table with one column family:
hbase(main):027:0> create ‘rootvorrand’, ‘info’
hbase(main):043:0> describe ‘rootvorrand’
DESCRIPTION ENABLED
‘rootvorrand’, {NAME => ‘info’, DATA_BLOCK_ENCODING => ‘NONE’, BLOOMFILTER => ‘ROW’, REPLICATION_SCOPE => ‘0’, VERSIONS => ‘1’, COMPRESSION => ‘NONE’, MIN_VERSIONS => ‘0’, TT true
L => ‘2147483647’, KEEP_DELETED_CELLS => ‘false’, BLOCKSIZE => ‘65536’, IN_MEMORY => ‘false’, BLOCKCACHE => ‘true’}
1 row(s) in 0.0330 seconds
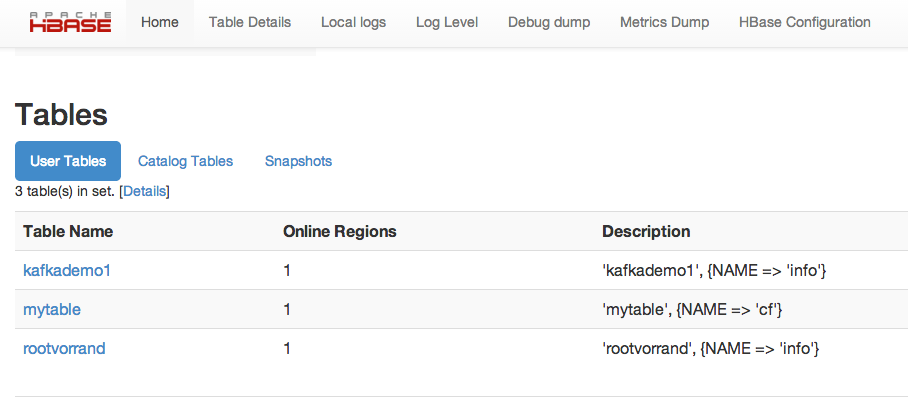
I can see my new table in UI too
Now I going to create apache-kafka topic with 3 replica and 1 partition
margusja@IRack:~/kafka_2.9.1-0.8.1.1$ bin/kafka-topics.sh –create –topic rootvorrand –partitions 1 –replication-factor 3 –zookeeper vm24:2181
margusja@IRack:~/kafka_2.9.1-0.8.1.1$ bin/kafka-topics.sh –describe –topic rootvorrand –zookeeper vm24.dbweb.ee:2181
Topic:rootvorrand PartitionCount:1 ReplicationFactor:3 Configs:
Topic: rootvorrand Partition: 0 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
Add some input data

Now lets set up development environment in Eclipse. I need some external jars. As you can see I am using the latest apache-spark 1.0.0 released about week ago.
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.UUID;
import java.util.regex.Pattern;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.*;
import scala.Tuple2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.HTablePool;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
public class KafkaSparkHbase {
private static final Pattern SPACE = Pattern.compile(” “);
private static HTable table;
public static void main(String[] args) {
String topic = “rootvorrand”;
int numThreads = 1;
String zkQuorum = “vm38:2181,vm37:2181,vm24:2181”;
String KafkaConsumerGroup = “sparkScript”;
String master = “spark://dlvm2:7077”;
// HBase config
Configuration conf = HBaseConfiguration.create();
conf.set(“hbase.defaults.for.version”,”0.96.0.2.0.6.0-76-hadoop2″);
conf.set(“hbase.defaults.for.version.skip”,”true”);
conf.set(“hbase.zookeeper.quorum”, “vm24,vm38,vm37”);
conf.set(“hbase.zookeeper.property.clientPort”, “2181”);
conf.set(“hbase.rootdir”, “hdfs://vm38:8020/user/hbase/data”);
try {
table = new HTable(conf, “rootvorrand”);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//SparkConf sparkConf = new SparkConf().setAppName(“KafkaSparkHbase”).setMaster(master).setJars(jars);
JavaStreamingContext jssc = new JavaStreamingContext(master, “KafkaWordCount”,
new Duration(2000), System.getenv(“SPARK_HOME”),
JavaStreamingContext.jarOfClass(KafkaSparkHbase.class));
//JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, new Duration(2000));
Map<String, Integer> topicMap = new HashMap<String, Integer>();
topicMap.put(topic, numThreads);
JavaPairReceiverInputDStream<String, String> messages = KafkaUtils.createStream(jssc, zkQuorum, KafkaConsumerGroup, topicMap);
JavaDStream lines = messages.map(new Function<Tuple2<String, String>, String>() {
@Override
public String call(Tuple2<String, String> tuple2) {
return tuple2._2();
}
});
// resolve quadratic equation
JavaDStream result = lines.map(
new Function<String, String>()
{
@Override
public String call(String x) throws Exception {
//System.out.println(“Input is: “+ x);
Integer a,b,c,y, d;
String[] splitResult = null;
Integer x1 = null;
Integer x2 = null;
splitResult = SPACE.split(x);
//System.out.println(“Split: “+ splitResult.length);
if (splitResult.length == 3)
{
a = Integer.valueOf(splitResult[0]);
b = Integer.valueOf(splitResult[1]);
c = Integer.valueOf(splitResult[2]);
y=(b*b)-(4*a*c);
d=(int) Math.sqrt(y);
//System.out.println(“discriminant: “+ d);
if (d > 0)
{
x1=(-b+d)/(2*a);
x2=(-b-d)/(2*a);
}
}
return x + ” “+ x1 + ” “+ x2;
}
}
);
result.foreachRDD(
new Function<JavaRDD, Void>() {
@Override
public Void call(final JavaRDD x) throws Exception {
System.out.println(x.count());
List arr = x.toArray();
for (String entry : arr) {
//System.out.println(entry);
Put p = new Put(Bytes.toBytes(UUID.randomUUID().toString()));
p.add(Bytes.toBytes(“info”), Bytes.toBytes(“record”), Bytes.toBytes(entry));
table.put(p);
}
table.flushCommits();
return null;
}
}
);
//result.print();
jssc.start();
jssc.awaitTermination();
}
}
pack it and run it:
[root@dlvm2 ~]java -cp kafkasparkhbase-0.1.jar KafkaSparkHbase
…
14/06/17 12:14:48 INFO JobScheduler: Finished job streaming job 1402996488000 ms.0 from job set of time 1402996488000 ms
14/06/17 12:14:48 INFO JobScheduler: Total delay: 0.052 s for time 1402996488000 ms (execution: 0.047 s)
14/06/17 12:14:48 INFO MappedRDD: Removing RDD 134 from persistence list
14/06/17 12:14:48 INFO BlockManager: Removing RDD 134
14/06/17 12:14:48 INFO MappedRDD: Removing RDD 133 from persistence list
14/06/17 12:14:48 INFO BlockManager: Removing RDD 133
14/06/17 12:14:48 INFO BlockRDD: Removing RDD 132 from persistence list
14/06/17 12:14:48 INFO BlockManager: Removing RDD 132
14/06/17 12:14:48 INFO KafkaInputDStream: Removing blocks of RDD BlockRDD[132] at BlockRDD at ReceiverInputDStream.scala:69 of time 1402996488000 ms
14/06/17 12:14:48 INFO BlockManagerInfo: Added input-0-1402996488400 in memory on dlvm2:33264 (size: 78.0 B, free: 294.9 MB)
14/06/17 12:14:48 INFO BlockManagerInfo: Added input-0-1402996488400 in memory on dlvm1:41044 (size: 78.0 B, free: 294.9 MB)
14/06/17 12:14:50 INFO ReceiverTracker: Stream 0 received 1 blocks
14/06/17 12:14:50 INFO JobScheduler: Starting job streaming job 1402996490000 ms.0 from job set of time 1402996490000 ms
14/06/17 12:14:50 INFO JobScheduler: Added jobs for time 1402996490000 ms
14/06/17 12:14:50 INFO SparkContext: Starting job: take at DStream.scala:593
14/06/17 12:14:50 INFO DAGScheduler: Got job 5 (take at DStream.scala:593) with 1 output partitions (allowLocal=true)
14/06/17 12:14:50 INFO DAGScheduler: Final stage: Stage 6(take at DStream.scala:593)
14/06/17 12:14:50 INFO DAGScheduler: Parents of final stage: List()
14/06/17 12:14:50 INFO DAGScheduler: Missing parents: List()
14/06/17 12:14:50 INFO DAGScheduler: Computing the requested partition locally
14/06/17 12:14:50 INFO BlockManager: Found block input-0-1402996488400 remotely
Input is: 1 4 3
Split: 3
discriminant: 2
x1: -1 x2: -3
14/06/17 12:14:50 INFO SparkContext: Job finished: take at DStream.scala:593, took 0.011823803 s
——————————————-
Time: 1402996490000 ms
——————————————-
1 4 3 -1 -3
As we can see. Input data from kafka is 1 4 3 and spark output line is 1 4 3 -1 -3 where -1 -3 are roots.
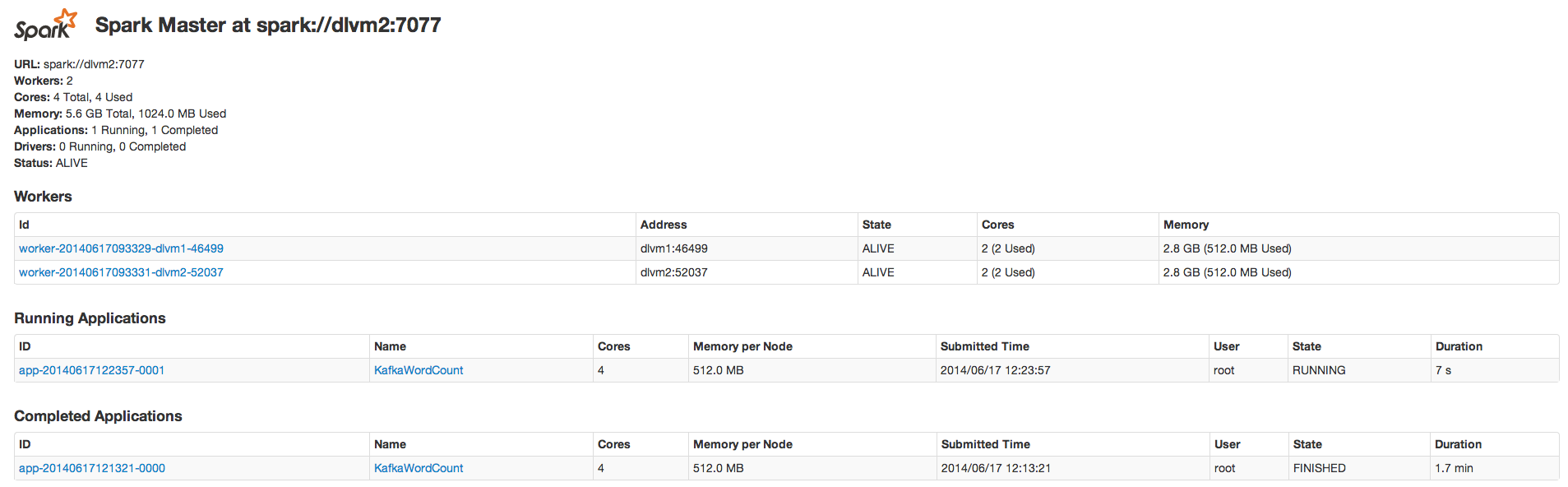
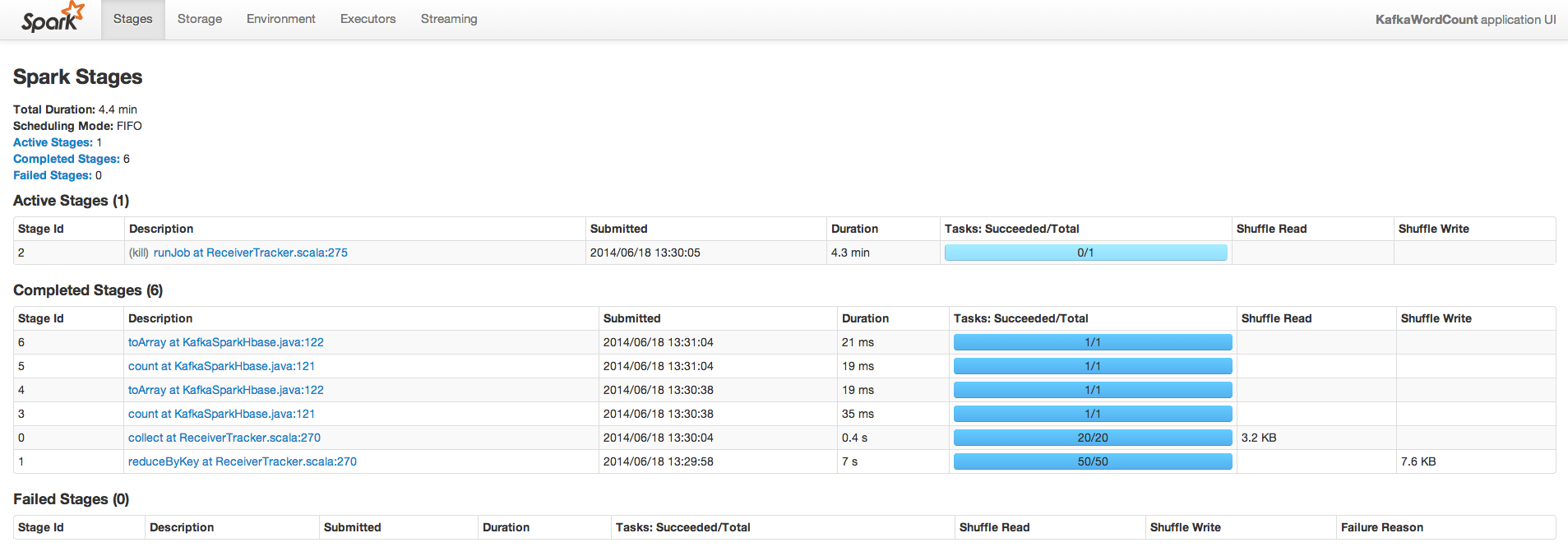
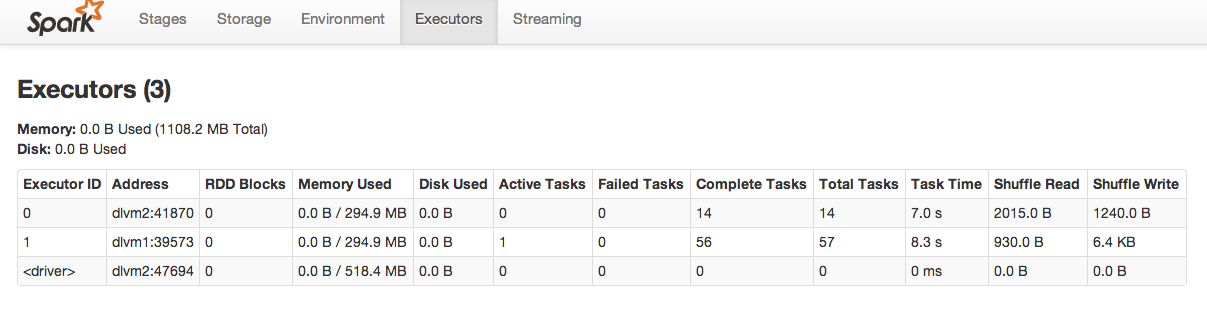
We can also see that there no lag in kafka queue. Spark worker is consumed all data from the queue
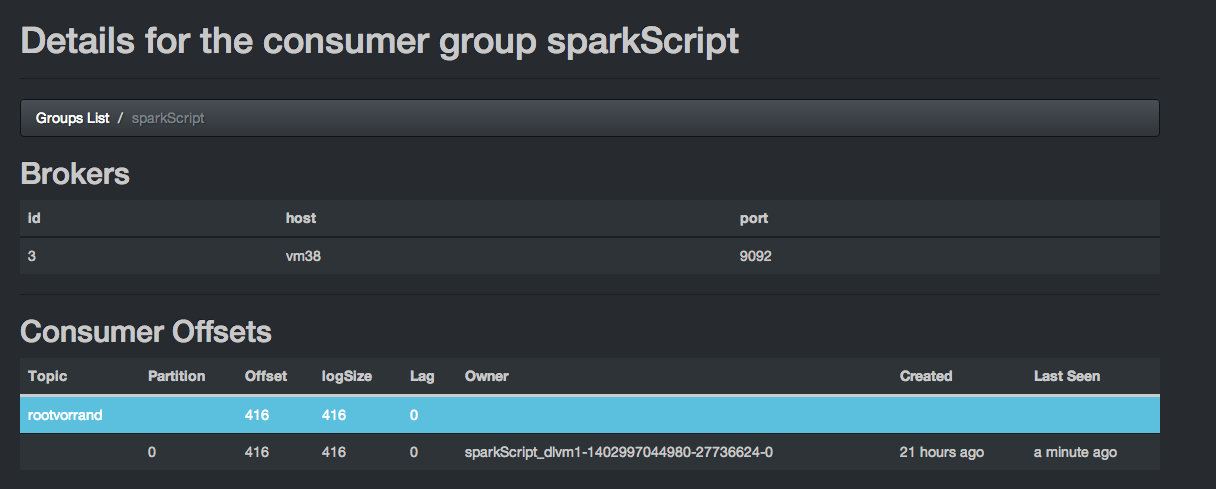
Let’s empty our HBase table:
put some input variables to kafka queue
-2 -3 10
2 -4 -10
And scan HBase table rootvorrand

As you can see. There are our input variables and roots.