I have file containing lines with text. I’d like to count all chars in the text. In case we have small file this is not the problem but what if we have huge text file. In example 1000TB distributed over Hadoop-HDFS.
Apache-Spark is one alternative for that job.
Big picture
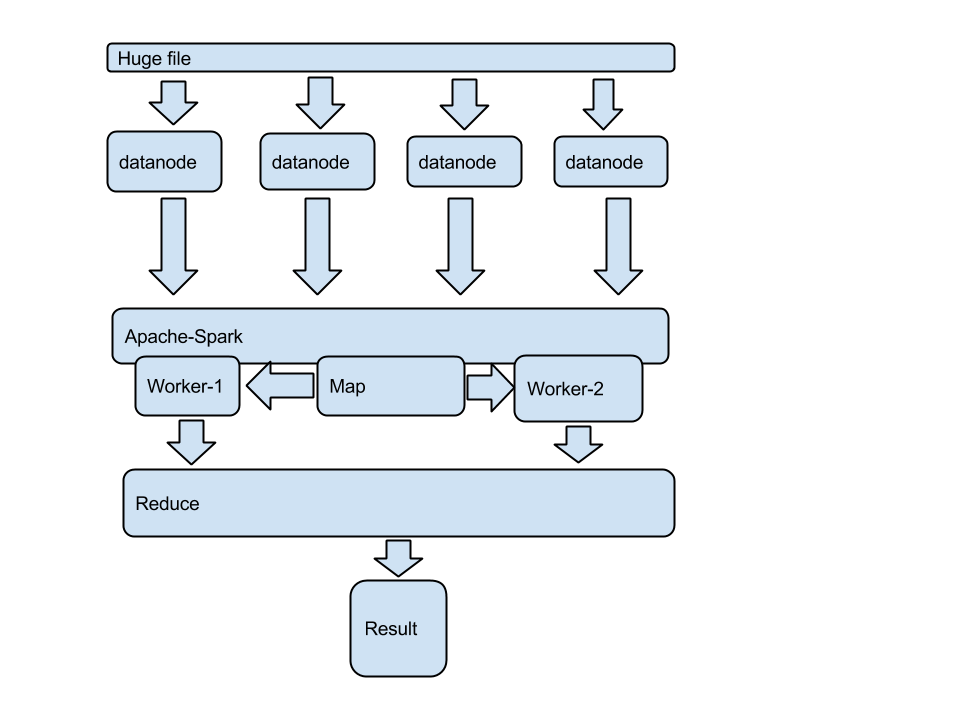
Now let’s dig into details
Apache Spark is a fast and general-purpose cluster computing system.
It provides high-level APIs in Java, Scala and Python,
and an optimized engine that supports general execution graphs.
It also supports a rich set of higher-level tools including Shark (Hive on Spark),
Spark SQL for structured data,
MLlib for machine learning,
GraphX for graph processing, and Spark Streaming.
This is java (spark) code:
String master = "local[3]";
String appName = "SparkReduceDemo";
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD file = sc.textFile(“data.txt”); // this is our text file
// this is map function – splits tasks between workers
JavaRDD lineLengths = file.map(new Function<String, Integer>() {
public Integer call(String s) {
System.out.println(“line: “+s + ” “+ s.length());
return s.length();
}
});
// this is reduce function – collects results from workers for driver programm
int totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) {
System.out.println(“a: “+ a);
System.out.println(“b: “+ b);
return a + b;
}
});
System.out.println(“Lenght: “+ totalLength);
compile and run. Let’s analyse result:
14/06/19 10:34:42 INFO SecurityManager: Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
14/06/19 10:34:42 INFO SecurityManager: Changing view acls to: margusja
14/06/19 10:34:42 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(margusja)
14/06/19 10:34:42 INFO Slf4jLogger: Slf4jLogger started
14/06/19 10:34:42 INFO Remoting: Starting remoting
14/06/19 10:34:43 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://spark@10.10.5.12:52116]
14/06/19 10:34:43 INFO Remoting: Remoting now listens on addresses: [akka.tcp://spark@10.10.5.12:52116]
14/06/19 10:34:43 INFO SparkEnv: Registering MapOutputTracker
14/06/19 10:34:43 INFO SparkEnv: Registering BlockManagerMaster
14/06/19 10:34:43 INFO DiskBlockManager: Created local directory at /var/folders/vm/5pggdh2x3_s_l6z55brtql3h0000gn/T/spark-local-20140619103443-bc5e
14/06/19 10:34:43 INFO MemoryStore: MemoryStore started with capacity 74.4 MB.
14/06/19 10:34:43 INFO ConnectionManager: Bound socket to port 52117 with id = ConnectionManagerId(10.10.5.12,52117)
14/06/19 10:34:43 INFO BlockManagerMaster: Trying to register BlockManager
14/06/19 10:34:43 INFO BlockManagerInfo: Registering block manager 10.10.5.12:52117 with 74.4 MB RAM
14/06/19 10:34:43 INFO BlockManagerMaster: Registered BlockManager
14/06/19 10:34:43 INFO HttpServer: Starting HTTP Server
14/06/19 10:34:43 INFO HttpBroadcast: Broadcast server started at http://10.10.5.12:52118
14/06/19 10:34:43 INFO HttpFileServer: HTTP File server directory is /var/folders/vm/5pggdh2x3_s_l6z55brtql3h0000gn/T/spark-b5c0fd3b-d197-4318-9d1d-7eda2b856b3c
14/06/19 10:34:43 INFO HttpServer: Starting HTTP Server
14/06/19 10:34:43 INFO SparkUI: Started SparkUI at http://10.10.5.12:4040
2014-06-19 10:34:43.751 java[816:1003] Unable to load realm info from SCDynamicStore
14/06/19 10:34:43 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
14/06/19 10:34:44 INFO MemoryStore: ensureFreeSpace(146579) called with curMem=0, maxMem=77974732
14/06/19 10:34:44 INFO MemoryStore: Block broadcast_0 stored as values to memory (estimated size 143.1 KB, free 74.2 MB)
14/06/19 10:34:44 INFO FileInputFormat: Total input paths to process : 1
14/06/19 10:34:44 INFO SparkContext: Starting job: reduce at SparkReduce.java:50
14/06/19 10:34:44 INFO DAGScheduler: Got job 0 (reduce at SparkReduce.java:50) with 2 output partitions (allowLocal=false)
14/06/19 10:34:44 INFO DAGScheduler: Final stage: Stage 0(reduce at SparkReduce.java:50)
14/06/19 10:34:44 INFO DAGScheduler: Parents of final stage: List()
14/06/19 10:34:44 INFO DAGScheduler: Missing parents: List()
14/06/19 10:34:44 INFO DAGScheduler: Submitting Stage 0 (MappedRDD[2] at map at SparkReduce.java:43), which has no missing parents
14/06/19 10:34:44 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (MappedRDD[2] at map at SparkReduce.java:43)
14/06/19 10:34:44 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
14/06/19 10:34:44 INFO TaskSetManager: Starting task 0.0:0 as TID 0 on executor localhost: localhost (PROCESS_LOCAL)
14/06/19 10:34:44 INFO TaskSetManager: Serialized task 0.0:0 as 1993 bytes in 3 ms
14/06/19 10:34:44 INFO TaskSetManager: Starting task 0.0:1 as TID 1 on executor localhost: localhost (PROCESS_LOCAL)
14/06/19 10:34:44 INFO TaskSetManager: Serialized task 0.0:1 as 1993 bytes in 0 ms
14/06/19 10:34:44 INFO Executor: Running task ID 0
14/06/19 10:34:44 INFO Executor: Running task ID 1
14/06/19 10:34:44 INFO BlockManager: Found block broadcast_0 locally
14/06/19 10:34:44 INFO BlockManager: Found block broadcast_0 locally
14/06/19 10:34:44 INFO HadoopRDD: Input split: file:/Users/margusja/Documents/workspace/Spark_1.0.0/data.txt:0+192
14/06/19 10:34:44 INFO HadoopRDD: Input split: file:/Users/margusja/Documents/workspace/Spark_1.0.0/data.txt:192+193
14/06/19 10:34:44 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
14/06/19 10:34:44 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
14/06/19 10:34:44 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
14/06/19 10:34:44 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
14/06/19 10:34:44 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
14/06/19 10:34:44 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
line: Apache Spark is a fast and general-purpose cluster computing system. 69
line: It provides high-level APIs in Java, Scala and Python, 55
a: 69
b: 55
line: and an optimized engine that supports general execution graphs. 64
a: 124
b: 64
line: It also supports a rich set of higher-level tools including Shark (Hive on Spark), 83
a: 188
b: 83
line: Spark SQL for structured data, 31
line: MLlib for machine learning, 28
a: 31
b: 28
line: GraphX for graph processing, and Spark Streaming. 49
a: 59
b: 49
14/06/19 10:34:44 INFO Executor: Serialized size of result for 0 is 675
14/06/19 10:34:44 INFO Executor: Serialized size of result for 1 is 675
14/06/19 10:34:44 INFO Executor: Sending result for 1 directly to driver
14/06/19 10:34:44 INFO Executor: Sending result for 0 directly to driver
14/06/19 10:34:44 INFO Executor: Finished task ID 1
14/06/19 10:34:44 INFO Executor: Finished task ID 0
14/06/19 10:34:44 INFO TaskSetManager: Finished TID 0 in 88 ms on localhost (progress: 1/2)
14/06/19 10:34:44 INFO TaskSetManager: Finished TID 1 in 79 ms on localhost (progress: 2/2)
14/06/19 10:34:44 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
14/06/19 10:34:44 INFO DAGScheduler: Completed ResultTask(0, 0)
14/06/19 10:34:44 INFO DAGScheduler: Completed ResultTask(0, 1)
14/06/19 10:34:44 INFO DAGScheduler: Stage 0 (reduce at SparkReduce.java:50) finished in 0.110 s
a: 271
b: 108
14/06/19 10:34:45 INFO SparkContext: Job finished: reduce at SparkReduce.java:50, took 0.2684 s
Lenght: 379
(r) above a|b means task was reduce.
