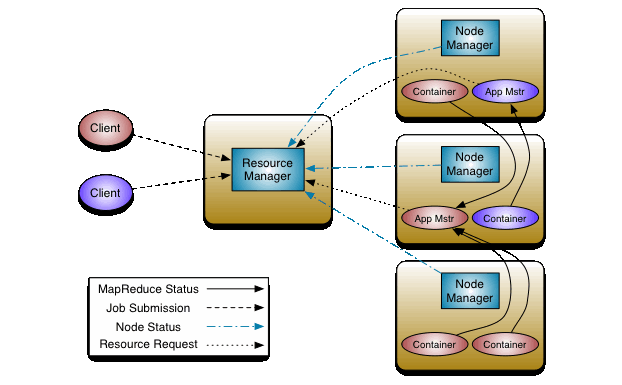
Since hadoop MRv1 and MRv2 are different I found good starting point from http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1-latest/bk_using-apache-hadoop/content/running_mapreduce_examples_on_yarn.html.
[root@vm37 hadoop-yarn]# yarn jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples-2.2.0.2.0.6.0-101.jar
An example program must be given as the first argument.
Valid program names are:
aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
dbcount: An example job that count the pageview counts from a database.
distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
grep: A map/reduce program that counts the matches of a regex in the input.
join: A job that effects a join over sorted, equally partitioned datasets
multifilewc: A job that counts words from several files.
pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
randomwriter: A map/reduce program that writes 10GB of random data per node.
secondarysort: An example defining a secondary sort to the reduce.
sort: A map/reduce program that sorts the data written by the random writer.
sudoku: A sudoku solver.
teragen: Generate data for the terasort
terasort: Run the terasort
teravalidate: Checking results of terasort
wordcount: A map/reduce program that counts the words in the input files.
wordmean: A map/reduce program that counts the average length of the words in the input files.
wordmedian: A map/reduce program that counts the median length of the words in the input files.
wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
Now lets take wordcount example. I have downloaded example dataset and put it into hadoop fs
[root@vm37 hadoop-mapreduce]# hfds dfs -put wc.txt /user/margusja/wc/input/
Now execute mapreduce job
[root@vm37 hadoop-mapreduce]# yarn jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples-2.2.0.2.0.6.0-101.jar wordcount /user/margusja/wc/input /user/margusja/wc/output
14/08/13 12:34:59 INFO client.RMProxy: Connecting to ResourceManager at vm38.dbweb.ee/192.168.1.72:8032
14/08/13 12:35:00 INFO input.FileInputFormat: Total input paths to process : 1
14/08/13 12:35:01 INFO mapreduce.JobSubmitter: number of splits:1
14/08/13 12:35:01 INFO Configuration.deprecation: user.name is deprecated. Instead, use mapreduce.job.user.name
14/08/13 12:35:01 INFO Configuration.deprecation: mapred.jar is deprecated. Instead, use mapreduce.job.jar
14/08/13 12:35:01 INFO Configuration.deprecation: mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
14/08/13 12:35:01 INFO Configuration.deprecation: mapreduce.combine.class is deprecated. Instead, use mapreduce.job.combine.class
14/08/13 12:35:01 INFO Configuration.deprecation: mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
14/08/13 12:35:01 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
14/08/13 12:35:01 INFO Configuration.deprecation: mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class
14/08/13 12:35:01 INFO Configuration.deprecation: mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
14/08/13 12:35:01 INFO Configuration.deprecation: mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
14/08/13 12:35:01 INFO Configuration.deprecation: mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
14/08/13 12:35:01 INFO Configuration.deprecation: mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
14/08/13 12:35:01 INFO Configuration.deprecation: mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
14/08/13 12:35:01 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1407837551751_0037
14/08/13 12:35:01 INFO impl.YarnClientImpl: Submitted application application_1407837551751_0037 to ResourceManager at vm38.dbweb.ee/192.168.1.72:8032
14/08/13 12:35:02 INFO mapreduce.Job: The url to track the job: http://vm38.dbweb.ee:8088/proxy/application_1407837551751_0037/
14/08/13 12:35:02 INFO mapreduce.Job: Running job: job_1407837551751_0037
14/08/13 12:35:11 INFO mapreduce.Job: Job job_1407837551751_0037 running in uber mode : false
14/08/13 12:35:11 INFO mapreduce.Job: map 0% reduce 0%
14/08/13 12:35:21 INFO mapreduce.Job: map 100% reduce 0%
14/08/13 12:35:31 INFO mapreduce.Job: map 100% reduce 100%
14/08/13 12:35:31 INFO mapreduce.Job: Job job_1407837551751_0037 completed successfully
14/08/13 12:35:31 INFO mapreduce.Job: Counters: 43
File System Counters
FILE: Number of bytes read=167524
FILE: Number of bytes written=493257
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=384341
HDFS: Number of bytes written=120766
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=8033
Total time spent by all reduces in occupied slots (ms)=7119
Map-Reduce Framework
Map input records=9488
Map output records=67825
Map output bytes=643386
Map output materialized bytes=167524
Input split bytes=134
Combine input records=67825
Combine output records=11900
Reduce input groups=11900
Reduce shuffle bytes=167524
Reduce input records=11900
Reduce output records=11900
Spilled Records=23800
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=172
CPU time spent (ms)=5880
Physical memory (bytes) snapshot=443211776
Virtual memory (bytes) snapshot=1953267712
Total committed heap usage (bytes)=317194240
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=384207
File Output Format Counters
Bytes Written=120766
…
And in my cluster UI I can see my submitted job

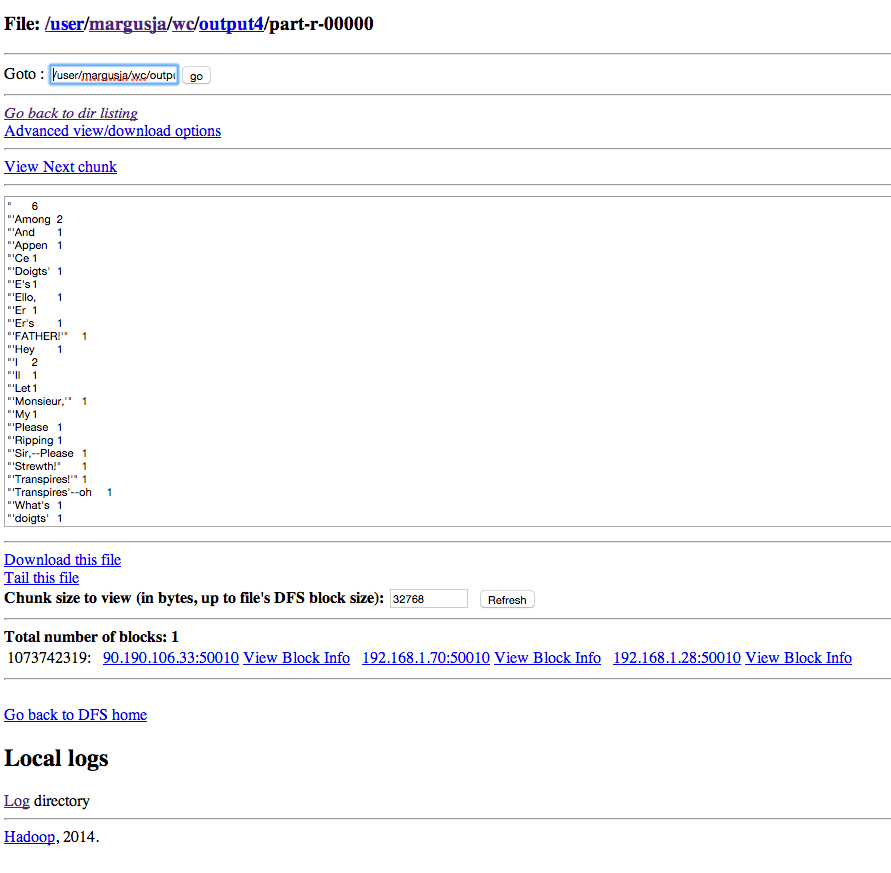
After job is finished you can explore result via HDFS UI
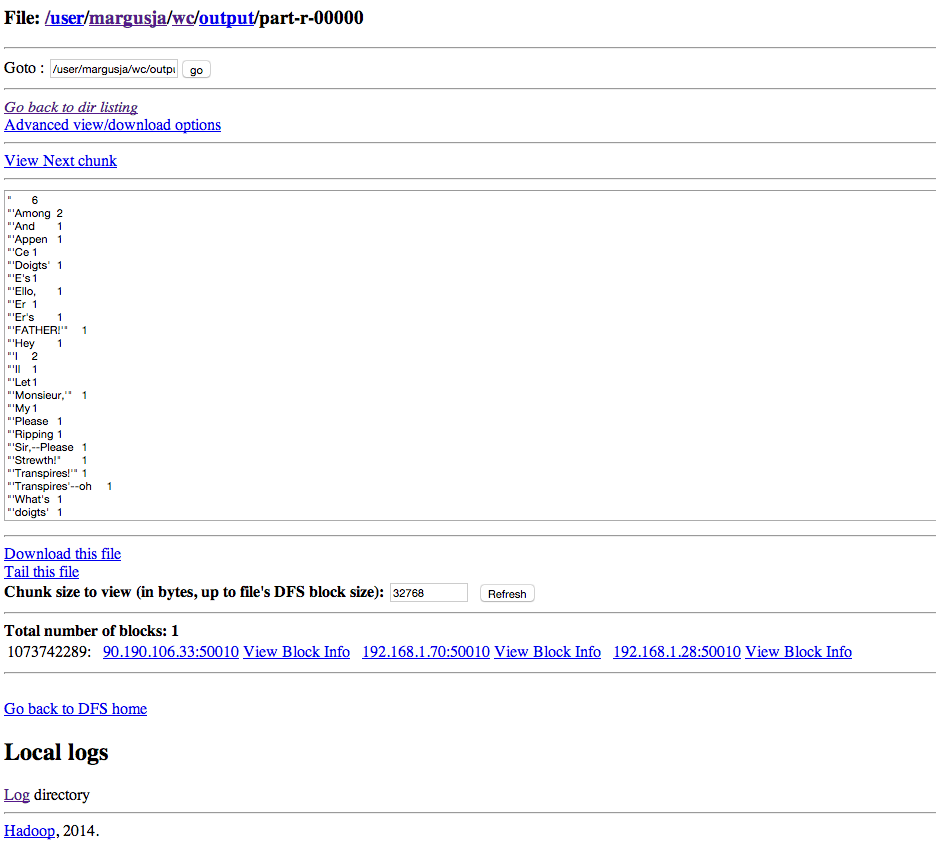
or you can move it to your local dir using hdfs command line command
[root@vm37 hadoop-mapreduce]# hdfs dfs -get /user/margusja/wc/output/part-r-00000
[root@vm37 hadoop-mapreduce]# head part-r-00000
” 6
“‘Among 2
“‘And 1
“‘Appen 1
“‘Ce 1
“‘Doigts’ 1
“‘E’s 1
“‘Ello, 1
“‘Er 1
“‘Er’s 1
Next step might by digging into source code
http://svn.apache.org/viewvc/hadoop/common/trunk/hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/
I am lazy person so I use maven to manage my java class dependencies
[margusja@vm37 ~]$ mvn archetype:generate -DgroupId=com.deciderlab.wordcount -DartifactId=wordcount -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
[INFO] Scanning for projects…
[INFO]
[INFO] ————————————————————————
[INFO] Building Maven Stub Project (No POM) 1
[INFO] ————————————————————————
[INFO]
[INFO] >>> maven-archetype-plugin:2.2:generate (default-cli) @ standalone-pom >>>
[INFO]
[INFO] <<< maven-archetype-plugin:2.2:generate (default-cli) @ standalone-pom <<<
[INFO]
[INFO] — maven-archetype-plugin:2.2:generate (default-cli) @ standalone-pom —
[INFO] Generating project in Batch mode
[INFO] —————————————————————————-
[INFO] Using following parameters for creating project from Old (1.x) Archetype: maven-archetype-quickstart:1.0
[INFO] —————————————————————————-
[INFO] Parameter: groupId, Value: com.deciderlab.wordcount
[INFO] Parameter: packageName, Value: com.deciderlab.wordcount
[INFO] Parameter: package, Value: com.deciderlab.wordcount
[INFO] Parameter: artifactId, Value: wordcount
[INFO] Parameter: basedir, Value: /var/www/html/margusja
[INFO] Parameter: version, Value: 1.0-SNAPSHOT
[INFO] project created from Old (1.x) Archetype in dir: /var/www/html/margusja/wordcount
[INFO] ————————————————————————
[INFO] BUILD SUCCESS
[INFO] ————————————————————————
[INFO] Total time: 6.382s
[INFO] Finished at: Wed Aug 13 13:08:59 EEST 2014
[INFO] Final Memory: 14M/105M
[INFO] ————————————————————————
Now you can move WordCount.java source to your src/main/…[whar ever is your dir]
I made some changes in Wordcount.java
…
package com.deciderlab.wordcount;
…
Job job = new Job(conf, “Margusja’s word count demo”);
…
in pom.xml I added some dependencies
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
now build your jar
[margusja@vm37 wordcount]$ mvn package
[INFO] Scanning for projects…
[INFO]
[INFO] ————————————————————————
[INFO] Building wordcount 1.0-SNAPSHOT
[INFO] ————————————————————————
[INFO]
[INFO] — maven-resources-plugin:2.5:resources (default-resources) @ WordCount —
[debug] execute contextualize
[WARNING] Using platform encoding (UTF-8 actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] skip non existing resourceDirectory /var/www/html/margusja/wordcount/src/main/resources
[INFO]
[INFO] — maven-compiler-plugin:2.3.2:compile (default-compile) @ WordCount —
[INFO] Nothing to compile – all classes are up to date
[INFO]
[INFO] — maven-resources-plugin:2.5:testResources (default-testResources) @ WordCount —
[debug] execute contextualize
[WARNING] Using platform encoding (UTF-8 actually) to copy filtered resources, i.e. build is platform dependent!
[INFO] skip non existing resourceDirectory /var/www/html/margusja/wordcount/src/test/resources
[INFO]
[INFO] — maven-compiler-plugin:2.3.2:testCompile (default-testCompile) @ WordCount —
[INFO] Nothing to compile – all classes are up to date
[INFO]
[INFO] — maven-surefire-plugin:2.10:test (default-test) @ WordCount —
[INFO] Surefire report directory: /var/www/html/margusja/wordcount/target/surefire-reports
——————————————————-
T E S T S
——————————————————-
Running com.deciderlab.wordcount.AppTest
Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 0.052 sec
Results :
Tests run: 1, Failures: 0, Errors: 0, Skipped: 0
[INFO]
[INFO] — maven-jar-plugin:2.3.2:jar (default-jar) @ WordCount —
[INFO] ————————————————————————
[INFO] BUILD SUCCESS
[INFO] ————————————————————————
[INFO] Total time: 4.552s
[INFO] Finished at: Wed Aug 13 13:58:08 EEST 2014
[INFO] Final Memory: 12M/171M
[INFO] ————————————————————————
[margusja@vm37 wordcount]$
Now you are ready to lunch your first hadoop MRv2 job
[margusja@vm37 wordcount]$ hadoop jar /var/www/html/margusja/wordcount/target/WordCount-1.0-SNAPSHOT.jar com.deciderlab.wordcount.WordCount /user/margusja/wc/input /user/margusja/wc/output4
…
14/08/13 14:01:38 INFO mapreduce.Job: Running job: job_1407837551751_0040
14/08/13 14:01:47 INFO mapreduce.Job: Job job_1407837551751_0040 running in uber mode : false
14/08/13 14:01:47 INFO mapreduce.Job: map 0% reduce 0%
14/08/13 14:01:58 INFO mapreduce.Job: map 100% reduce 0%
14/08/13 14:02:07 INFO mapreduce.Job: map 100% reduce 100%
14/08/13 14:02:08 INFO mapreduce.Job: Job job_1407837551751_0040 completed successfully
14/08/13 14:02:08 INFO mapreduce.Job: Counters: 43
File System Counters
FILE: Number of bytes read=167524
FILE: Number of bytes written=493091
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=384341
HDFS: Number of bytes written=120766
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=7749
Total time spent by all reduces in occupied slots (ms)=6591
Map-Reduce Framework
Map input records=9488
Map output records=67825
Map output bytes=643386
Map output materialized bytes=167524
Input split bytes=134
Combine input records=67825
Combine output records=11900
Reduce input groups=11900
Reduce shuffle bytes=167524
Reduce input records=11900
Reduce output records=11900
Spilled Records=23800
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=114
CPU time spent (ms)=6020
Physical memory (bytes) snapshot=430088192
Virtual memory (bytes) snapshot=1945890816
Total committed heap usage (bytes)=317194240
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=384207
File Output Format Counters
Bytes Written=120766
You can examine your running jobs
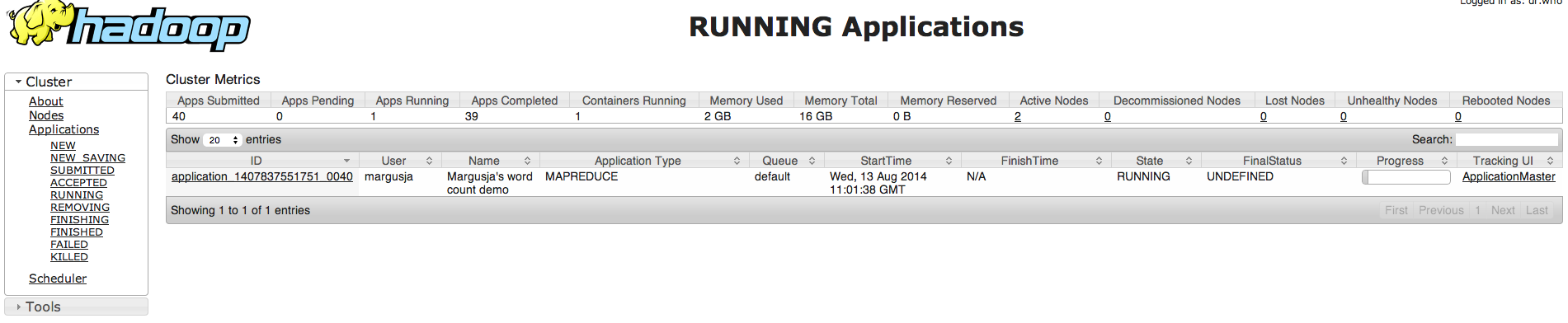
And result in HDFS UI