![]() Recently I had problem where I had many huge files containing timestamps and I had to separate thous lines into separate files.
Recently I had problem where I had many huge files containing timestamps and I had to separate thous lines into separate files.
Basically group by and save groups to separate files.
First I tried do to it in apache-hive and somehow I reached to the result but I did’t like it. Deep inside I felt there have to be better and cleaner solution for that.
I can’t share the original dataset but lets generate some sample data and play with it. Because problem is the same.
A frame of my example dataset
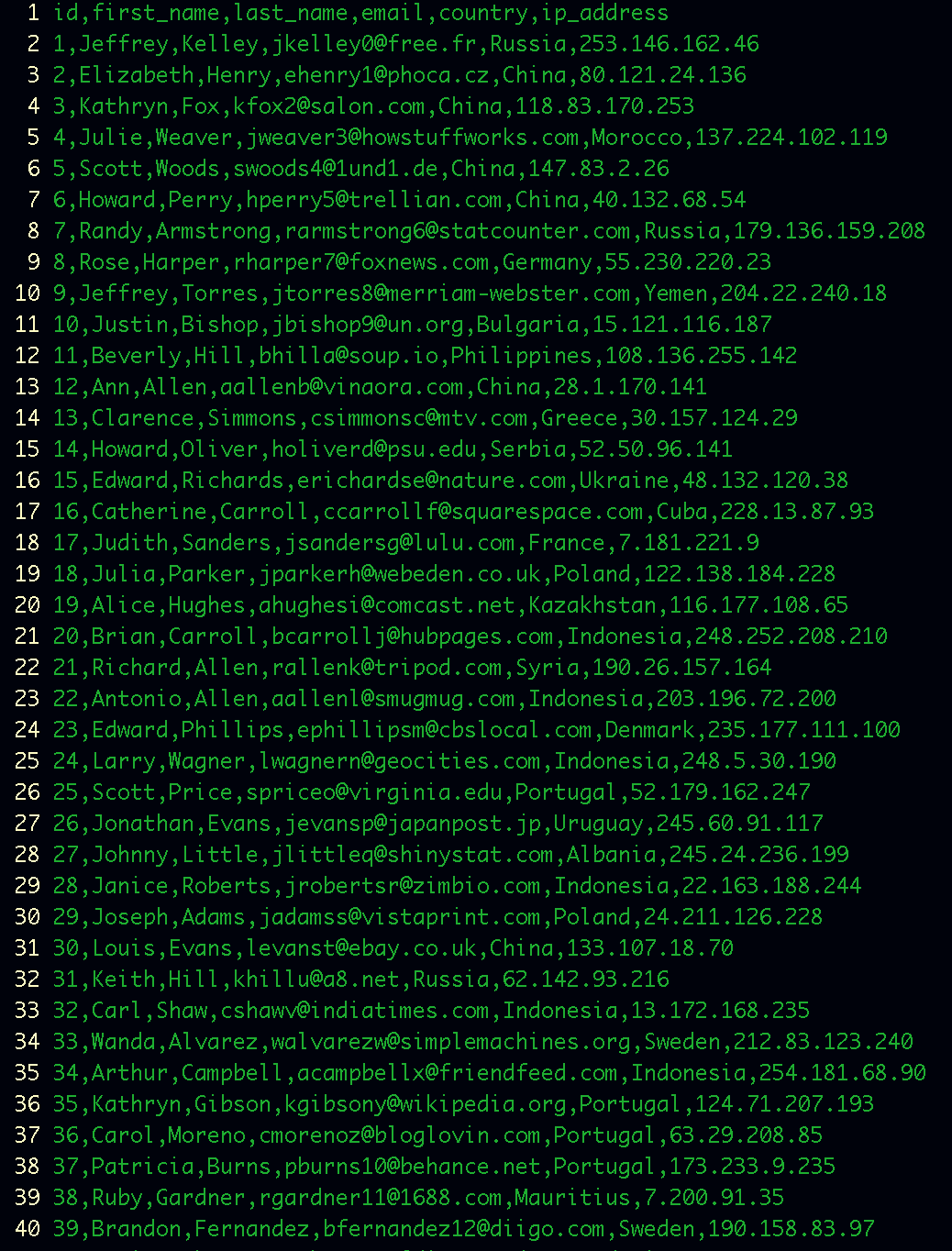
Actually there are 1001 rows including header
So as you can see there is column country. I going to use apache-pig to split rows so that finally I can save them in to different directories in to hadoop HDFS.
First let’s load our data and describe schema. chararray is similar to the string type what is familiar from many different langues to as.
A = LOAD ‘/user/margusja/pig_demo_files/MOCK_DATA.csv’ using PigStorage(‘,’) AS (id: int, first_name: chararray, last_name: chararray, email: chararray, country: chararray,
ip_address: chararray);
so and final PIG sentence will be:
STORE A INTO ‘/user/margusja/pig_demo_out/’ USING org.apache.pig.piggybank.storage.MultiStorage(‘/user/margusja/pig_demo_out’, ‘4’, ‘none’, ‘,’);
Some additional words about line above. Let me explain MultiStorage’s header (‘/user/margusja/pig_demo_out’, ‘4’, ‘none’, ‘,’)
The first argument is path in HDFS. That is the place we are going to find our generated directories containing countries files. It has to be similar we are using after STORE A INTO …
The second argument is column’s index we are going to use as directory name. Third, in our case in none, we can use if we’d like to compress data. The last one is separator between columns.
So let’s run our tiny but very useful pig script
> pig -f demo.pig
It starting map/reduce job in our hadoop cluster. After it finished we can admit the result in our hadoop HDFS.
Some snapshots from the result via HUE
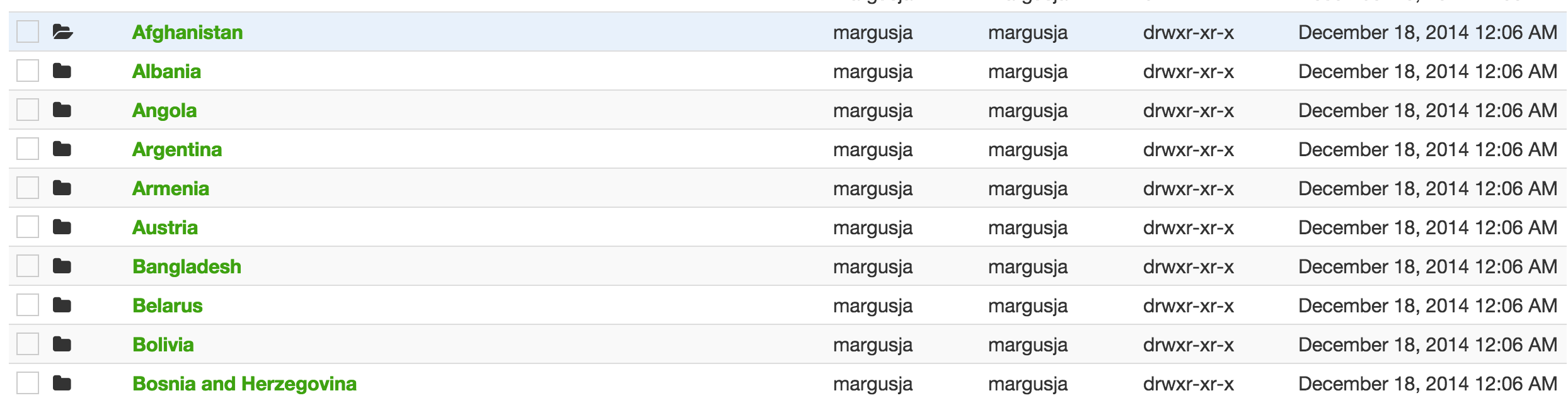
If we look into directory Estonia we can find there is a file contains only rows where country is Estonia
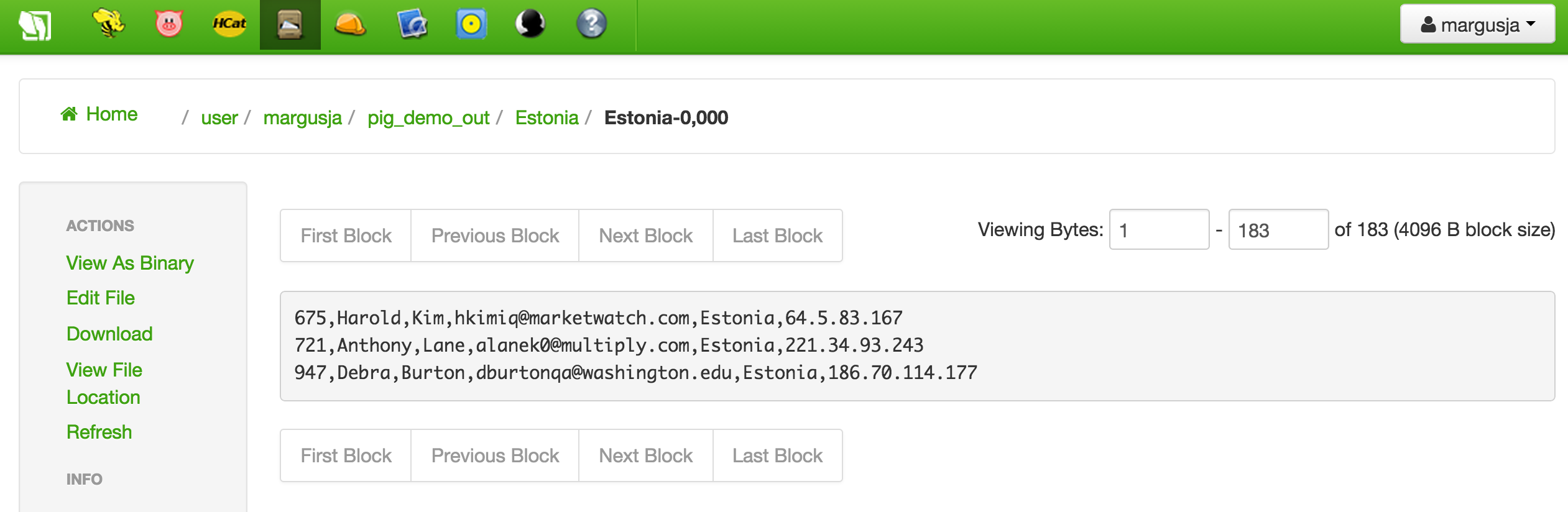
So my opinion is that this is awesome!