evaluator: org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator = mcEval_a147352f3495
precision: Double = 0.9735973597359736
confusionMatrix: org.apache.spark.sql.DataFrame = [label: double, 0.0: bigint, 1.0: bigint, 2.0: bigint, 3.0: bigint, 4.0: bigint, 5.0: bigint, 6.0: bigint, 7.0: bigint, 8.0: bigint, 9.0: bigint]
Confusion Matrix (Vertical: Actual, Horizontal: Predicted):
+-----+---+----+----+---+---+---+---+---+---+---+
|label|0.0| 1.0| 2.0|3.0|4.0|5.0|6.0|7.0|8.0|9.0|
+-----+---+----+----+---+---+---+---+---+---+---+
| 0.0|961| 0| 3| 2| 1| 4| 5| 2| 1| 1|
| 1.0| 0|1125| 4| 0| 0| 1| 1| 2| 2| 0|
| 2.0| 3| 2|1005| 5| 1| 1| 2| 4| 9| 0|
| 3.0| 0| 0| 3|992| 0| 1| 0| 4| 6| 4|
| 4.0| 2| 0| 4| 1|953| 1| 3| 3| 2| 13|
| 5.0| 6| 0| 0| 15| 1|858| 5| 1| 4| 2|
| 6.0| 4| 2| 3| 0| 5| 8|936| 0| 0| 0|
| 7.0| 0| 5| 9| 3| 1| 0| 0|992| 1| 16|
| 8.0| 3| 0| 4| 6| 2| 6| 3| 5|944| 1|
| 9.0| 2| 2| 2| 10| 11| 2| 2| 6| 3|969|
+-----+---+----+----+---+---+---+---+---+---+---+
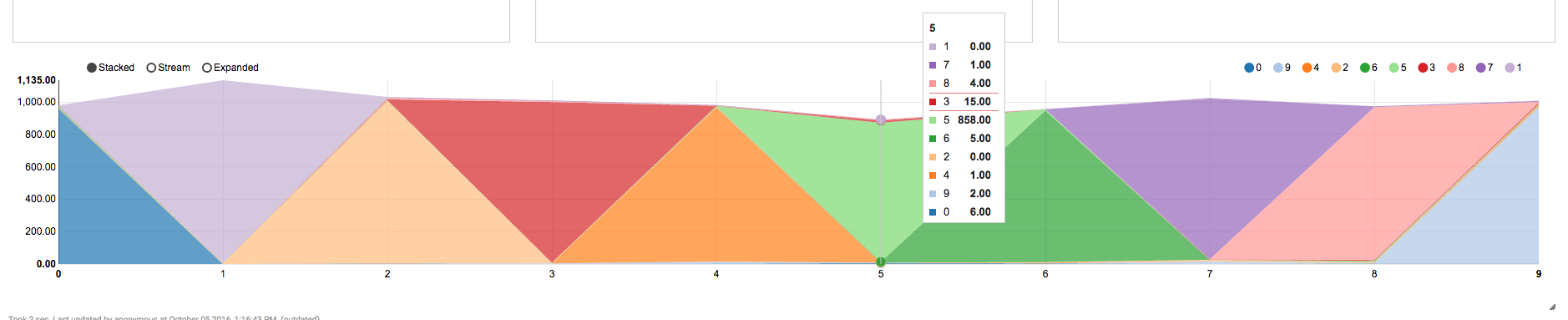
About visualization. One way to present results is above. But much more nicer is in example graph from apache-zeppelin sql node:

What we can see from picture. In example we are on number zero and we can see that number of correct predictions is 961. Also there is a list of wrongly predicted numbers.
In the next picture when we hover over 5 we can see there is red area top of it. As you can see red in this picture means number 5. So there are 15 wrongly predicted numbers as number 3. And it is expected because numbers 5 and 3 are quite similar for machine.