Kasutades R keelt ja RStudio rakendust näitan, miks on katseseeria pikkus oluline.
Võtame näidisvektori:
> myFamilyAges
[1] 43 42 12 8 5
Antud vektori elementide keskmine (mean):
> mean(myFamilyAges)
[1] 22
Võtame nüüd sample() käsuga viis korda kõnealusest vektorist viis elemente ja arvutame nende keskmise:
> mean(sample(myFamilyAges, 5, replace = TRUE))
[1] 22.6
> mean(sample(myFamilyAges, 5, replace = TRUE))
[1] 35.8
> mean(sample(myFamilyAges, 5, replace = TRUE))
[1] 21.4
> mean(sample(myFamilyAges, 5, replace = TRUE))
[1] 13.2
> mean(sample(myFamilyAges, 5, replace = TRUE))
[1] 35.4
nagu näeme varieerub tulemus tugevalt:
> sd(c(22.6,35.8,21.4,13.2,35.4))
[1] 9.752538
Võtame nüüd ühe korra 4000 korda samast vektorist elemente ja arvutame nende keskmise:
> mean(sample(myFamilyAges, 4000, replace = TRUE))
[1] 21.8995
Kuvame ka tihedusgraafikud
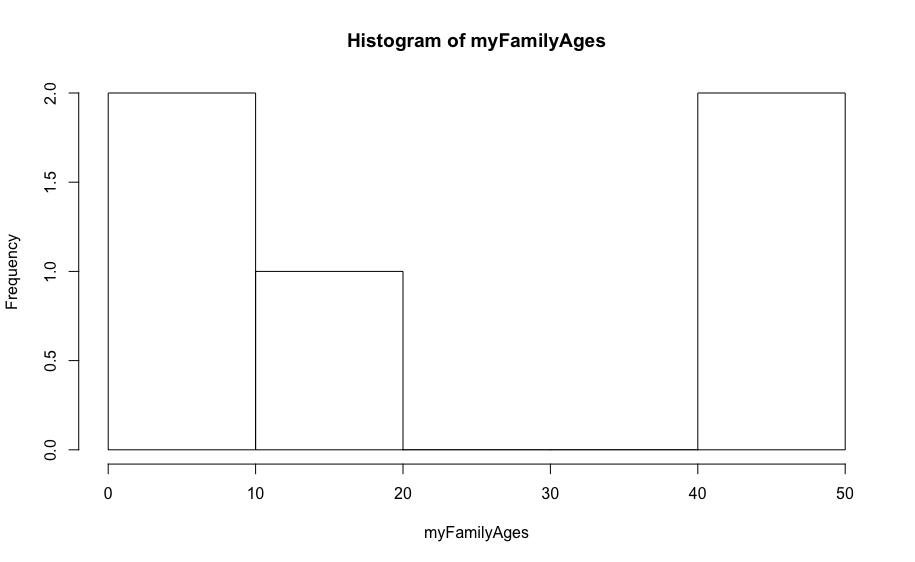
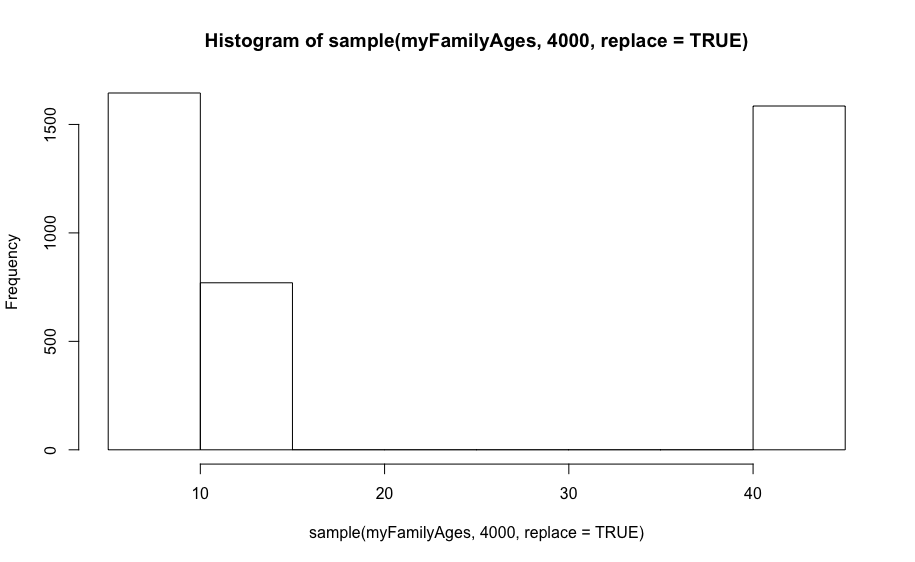
Nagu näha – kohe väga lähedale originaalvektori keskmisele (22).
Seega – suurus on oluline 🙂