![]()
Spark on hadoop-mapreduc’e kõrval väga võimekas alternatiiv paralleelarvutuste teostamiseks.
Alljärgnevalt mõned sammud, kuidas seadistada spark standalone klasterit.
Mina kasutan hetkel kõige uuemat binary pakki, kus on ka hadoop2 mapreduce tugi. Nimelt on spark’l MapReduce2 tugi olemas, aga hetkel jääme sparki enda standalone lahenduse juurde.
Mul on kasutada kolm füüsilist serverit – vm37, vm38, vm24. vm37 valin ma nn master serveriks, mida kutsutakse spark kontekstis ka driver’ks.
Laen alla hetkel viimase versiooni – http://d3kbcqa49mib13.cloudfront.net/spark-0.9.1-bin-hadoop2.tgz vm37 /opt/ kataloogi ja pakin laht.
Sama kordan ka kõigis slave serverites – laen sama paketi ja pakin lahti samasse kohta – /opt
Master (vm37) peab omama ilma paroolita ssh ligipääsu slave serveritesse. Siinkohal on abiks ssh võtmetega ligipääsud.
cd /opt/spark-0.9.1-bin-hadoop2
Seadistan nn slaved: vim conf/slaves – lisan iga slave eraldi reale.
Käivitan klastri: ./sbin/start-all.sh
Kui nüüd kõik kenasti õnnestus, siis peaks tekkima master serverisse veebiliides vm37:8081

Kasutades spark-shell käsurida, teeme lihtsa arvutussessiooni:

GUI kaudu peaks ilmuma samuti sessiooni informatsioon:

Detailsem vaade:

Laadime ühe faili ja loeme kui palju on sõnu selles failis:

On näha, et tööks kasutati kahte serverit vm24 ja vm38. Antud töö kohta on ka GUI kaudu informatsioon olemas:


Antud juhul oli tegu väga triviaalse näitega. Spark omab matemaatiliste ja masin-õppivate arvutuste tuge MLib
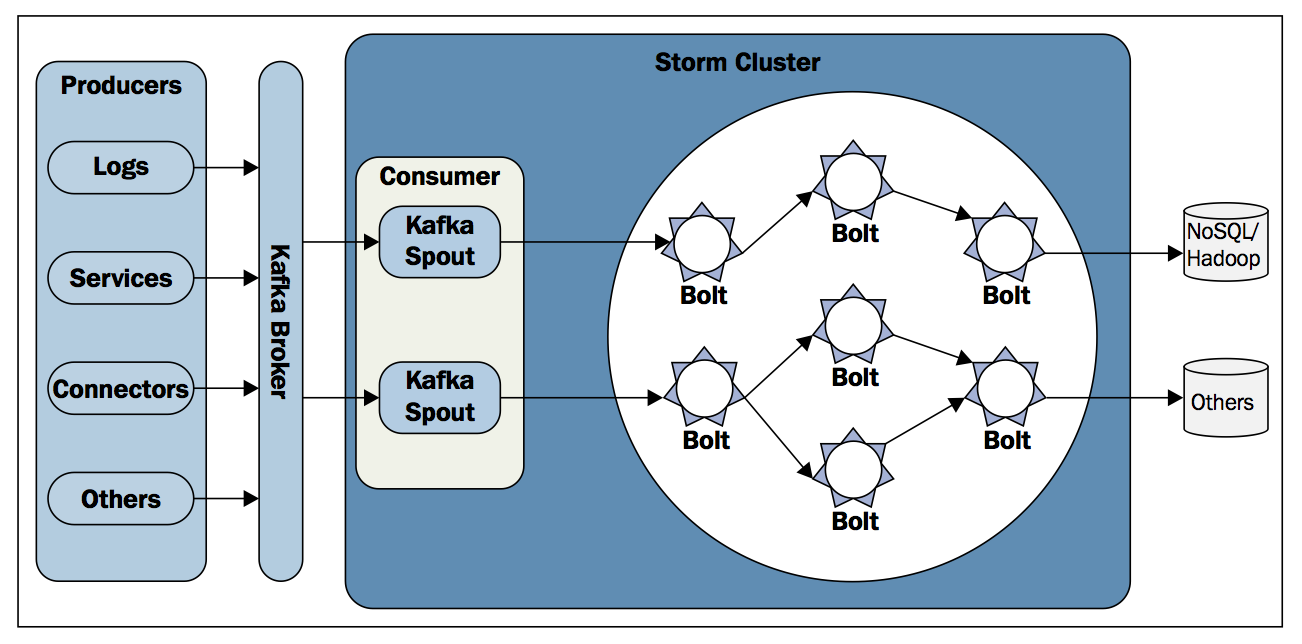
Andmete reaalajas arvutamiseks on võimalik kasutada Spark Streaming tuge. Näiteks lugeda mõnest järjekorrasüsteemis nagu Apache-Kafka või Apache-Flume väljund voogusid, neid analüüsida ja tulemused salvestada HDFS andmebaasi HBase.