[margusja@sandbox storm_to_file]$ find libs/hbase-0.96.2-hadoop2/lib/ -name ‘*.jar’ -exec grep -Hls HBaseConfiguration {} \;
Hadoop and how to read via webhdfs
Create a local demo file – demo.txt and put some content into it
Upload to hdfs:
margusja@IRack:~/hadoop-2.4.0$ bin/hdfs dfs -put demo.txt hdfs://127.0.0.1/user/margusja/
Open and read via webhdfs:
margusja@IRack:~/hadoop-2.4.0$ curl -i -L “http://localhost:50070/webhdfs/v1/user/margusja/demo.txt?op=OPEN”
HTTP/1.1 307 TEMPORARY_REDIRECT
Cache-Control: no-cache
Expires: Fri, 25 Apr 2014 09:34:46 GMT
Date: Fri, 25 Apr 2014 09:34:46 GMT
Pragma: no-cache
Expires: Fri, 25 Apr 2014 09:34:46 GMT
Date: Fri, 25 Apr 2014 09:34:46 GMT
Pragma: no-cache
Location: http://sandbox.hortonworks.com:50075/webhdfs/v1/user/margusja/demo.txt?op=OPEN&namenoderpcaddress=sandbox.hortonworks.com:8020&offset=0
Content-Type: application/octet-stream
Content-Length: 0
Server: Jetty(6.1.26)
HTTP/1.1 200 OK
Cache-Control: no-cache
Expires: Fri, 25 Apr 2014 09:34:46 GMT
Date: Fri, 25 Apr 2014 09:34:46 GMT
Pragma: no-cache
Expires: Fri, 25 Apr 2014 09:34:46 GMT
Date: Fri, 25 Apr 2014 09:34:46 GMT
Pragma: no-cache
Content-Length: 93
Content-Type: application/octet-stream
Server: Jetty(6.1.26)
Hello, this is a demo file by Margusja@deciderlab.com
This is demo how to use hadoop webhdfs
margusja@IRack:~/hadoop-2.4.0$
Apache-storm
Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate
Apache-zookeeper http://zookeeper.apache.org/doc/trunk/index.html
zookeeper on mõeldud hoidma teenuste seadistusi ja staatusi. Näiteks antud juhul on zookeeper serverites talletatud informatsioon, millised storm’i workerid on olemas.
Zookeeper teenus võib olla jaotunud eraldi serverite vahel, mis tagab kõrge veakindluse
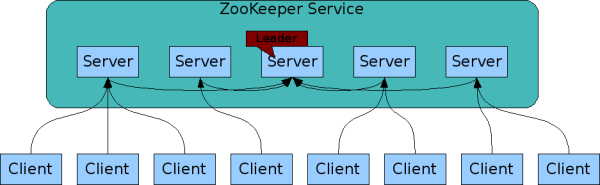
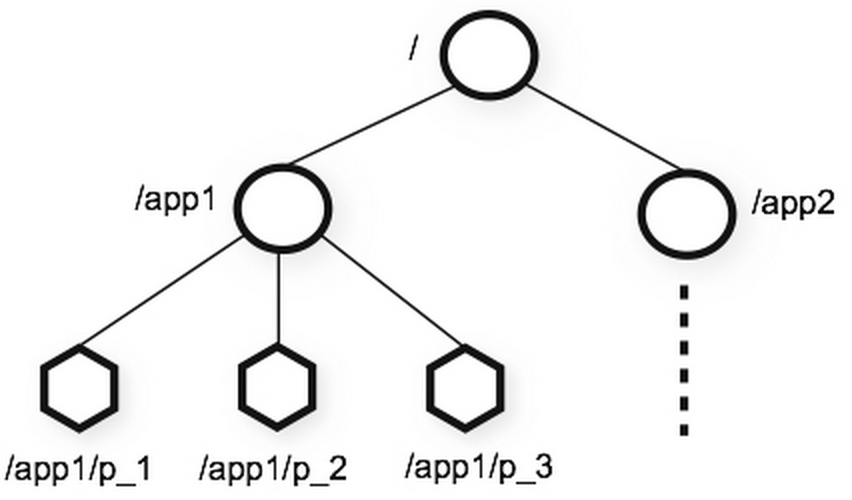
Zookeeper hoiab seadistusi hierarhias
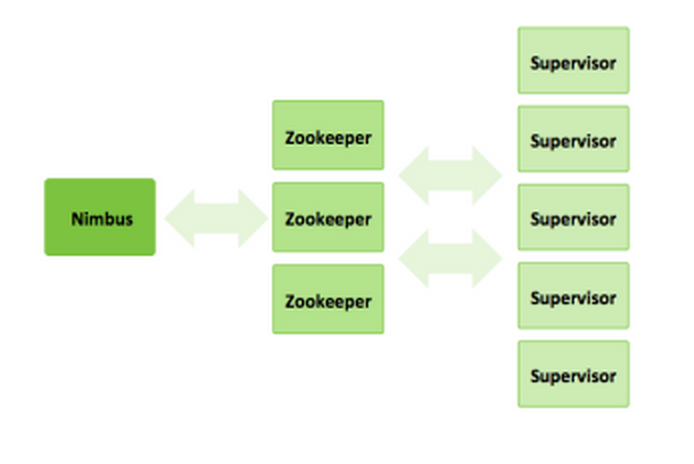
Näiteks minu testkeskkonnas on üks storm supervisor e worker ja hetkel on üks topoloogia, see kajastub zookeeperis:
[root@sandbox ~]# /usr/lib/zookeeper/bin/zkCli.sh -server 127.0.0.1:2181
Connecting to 127.0.0.1:2181
…
[zk: 127.0.0.1:2181(CONNECTED) 1] ls /storm
[workerbeats, errors, supervisors, storms, assignments]
[zk: 127.0.0.1:2181(CONNECTED) 2] ls /storm/storms
[engineMessages5-2-1398208863]
[zk: 127.0.0.1:2181(CONNECTED) 3]
Zookeeper võimaldab stormi workereid dünaamiliselt juurde lisada. Storm master e nimbus oskab zookeeper serverist saadud info kohaselt workereid kasutada. Näiteks, kui mõni worker mingil põhjusel ei ole enam kättesaadav, siis zookeeper saab sellest teada, kuna heardbeate enam ei tule ja nimbus organiseerib voogude teekonnad ringi tekitades kadunud workeri asemel uue, eeldusel, et on kuhugile tekitada ehk on veel vabu supervisoreid.
Storm
Storm has many use cases: realtime analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Storm is fast: a benchmark clocked it at over a million tuples processed per second per node. It is scalable, fault-tolerant, guarantees your data will be processed, and is easy to set up and operate.
Nimbus
On master topoloogias, kes kordineerib, kasutades zookeeper-klastris olevat informatsiooni, storm-supervisorite töid ehk tagab voogude läbimise topoloogiast.
Storm-supervisor ehk worker
Spout(id) ja/või Bolt(id), kes kuuluvad mingisse topoloogiasse. Võivad asuda ühes füüsilises serveris või jaotatud erinevate füüsiliste serverite vahel. Zookeeperi abil annavad nimbusele teada oma olemasolust.
Storm-supervisor versus supervisor (http://supervisord.org/)
Etteruttavalt selgitan, et antud juhul on kasutusel kaks supervisor teenust, mis on erinevad ja mida on vaja lahti seletada.
storm-supervisor – strom worker
supervisor – Process Control System.
On kasutusel, tagamaks, et teenused – nimbus, zookeeper, storm_supervisor (worker) oleksid kiirelt taastatud, kui mõni neist peaks mingil põhjusel seiskuma.
Näide:
Hetkel on minu testkeskkonnas supervisor (mitte storm-supervisor) kontrolli all vajalikud storm teenused
[root@sandbox ~]# supervisorctl
storm-supervisor RUNNING pid 3483, uptime 2:14:55
storm_nimbus RUNNING pid 3765, uptime 1:44:23
storm_ui RUNNING pid 3672, uptime 2:13:09
zookeeper RUNNING pid 3484, uptime 2:14:55
supervisor>
Peatades näiteks storm_nimbus protsessi 3765
[root@sandbox ~]# kill -9 3765
supervisord logis:
2014-04-22 17:53:20,884 INFO exited: storm_nimbus (terminated by SIGKILL; not expected)
2014-04-22 17:53:20,884 INFO received SIGCLD indicating a child quit
2014-04-22 17:53:21,894 INFO spawned: ‘storm_nimbus’ with pid 4604
2014-04-22 17:53:22,898 INFO success: storm_nimbus entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
Kontrollime supervusord statust
supervisor> status
storm-supervisor RUNNING pid 3483, uptime 2:30:50
storm_nimbus RUNNING pid 4604, uptime 0:00:38
storm_ui RUNNING pid 3672, uptime 2:29:04
zookeeper RUNNING pid 3484, uptime 2:30:50
On näha, et just on uus protsess käivitatud.
Toodangusüsteemides on soovitatav jaotada storm komponendid nii, et nimbus, ui ja üks zookeeper server on ühes masinas ja teistes asuvad zookeeper server ja storm-supervisor. Komplekte zookeeper-server ja storm-supervusor võib dünaamiliselt hiljem lisada.
Vahemärkusena, et tegelikult ei pea storm-supervisor ja zookeeper ühes füüsilises serveris asuma. Piisab, kui storm-supervisor teab, kus asub zookeeper server, et sinna oma staatus teatada.
Kui mingil põhjusel peaks üks storm-supervusor kättesaamatuks muutuma, siis nimbus saab sellest teada ja organiseerib topoloogia niimoodi, et voog oleks täielik.
Kui mingil põhjusel peaks muutuma mittekättesaadavaks nimbus, siis topoloogia on terviklik ja vood täätavad edasi.
Kui mingil põhjusel peaks muutuma korraga mittekättesaadavaks nimbus ja mõni hetkel topoloogias aktiivselt osalev storm-supervisor, siis tekib esimene reaalne probleem. Samas ka siin ei kao voos liikuvad andmed vaid õige seadistuse puhul iga topoloogias olev Spout registreerib voos olevate sõnumite mittekohalejõudmise ja kui nüüd taastatakse nimbus ja/või storm-supervisor, siis Spout saadab sõnumi uuesti.
Kujutame ette, et meil on allpool toodud topoloogia
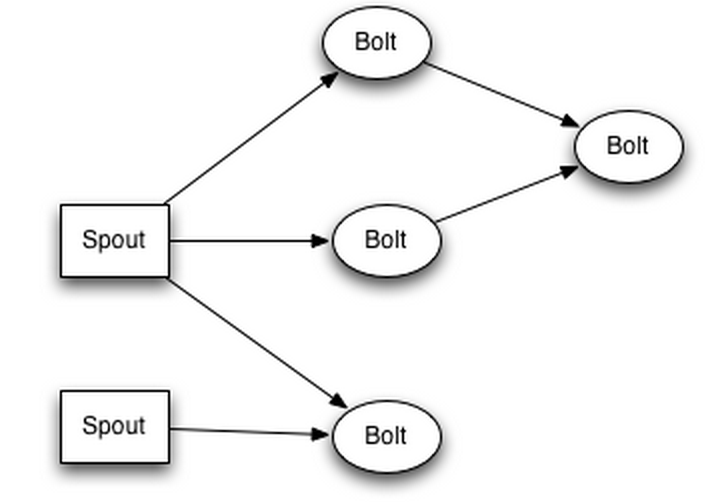
Kõik Bolt’d ja Spout’d asuvad eraldi masinates ehk on srorm-supervusor + zookeeper komplektid, siis juhul, kui peaks tekkima selline olukord
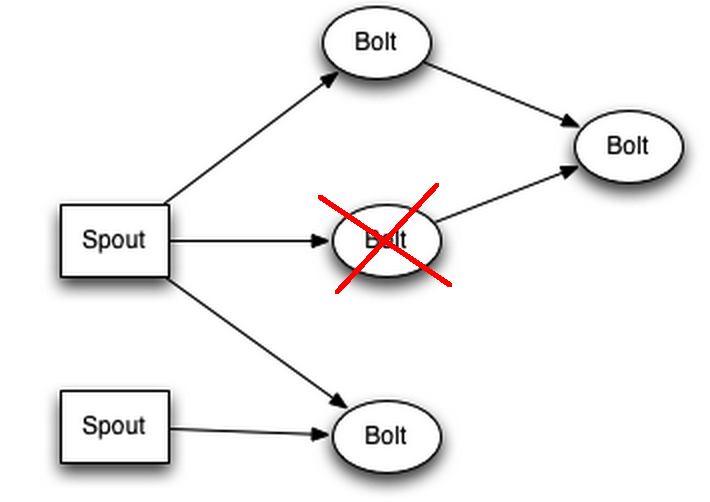
Siis nimbus saab sellest teada, sest zookeeperisse enam heartbeate ei tule ja nimbus üritab leida zookeeperi kaudu mõnda vaba serverit, kus on storm-supervisor.
Kui nüüd on olemas zookeeperi kaudu nimbusele teada mõni vaba storm-supervisor, siis topoloogia taastatakse. Kui mõnii sõnum ei jõudnud vahepeal kohale, kuna topoloogia ei olnud täielik, siis Spout on sellest teadlik ja saadab sõnumi uuesti.
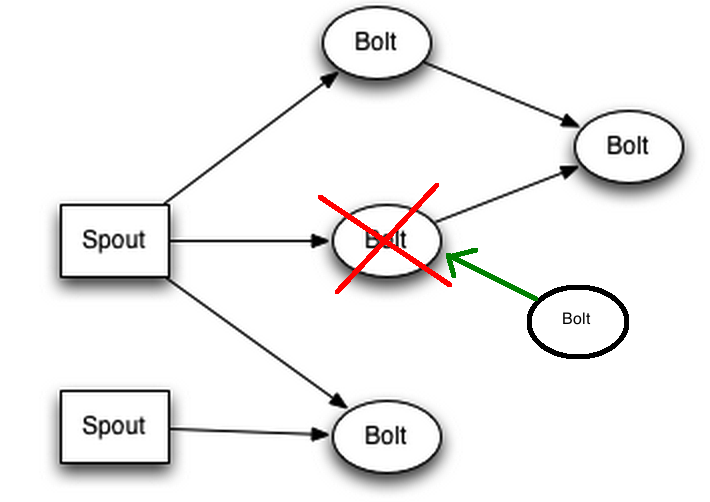
jätkub…
Pentaho and Saiku
Some screenshot may help me in future
Add a new datasource
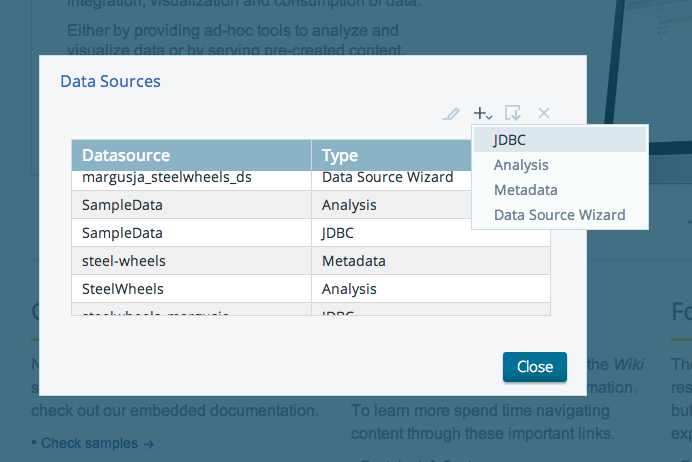
configure new mysql connection

Add a new datasource wizard
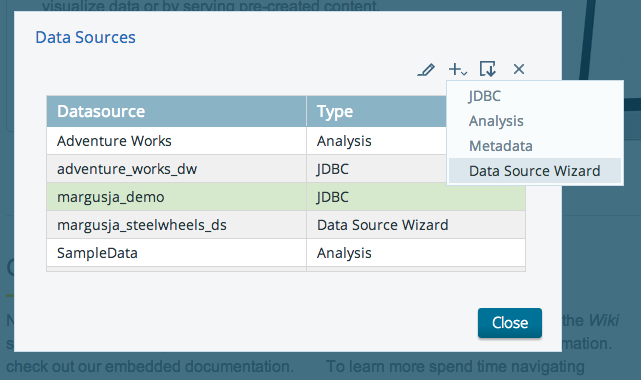
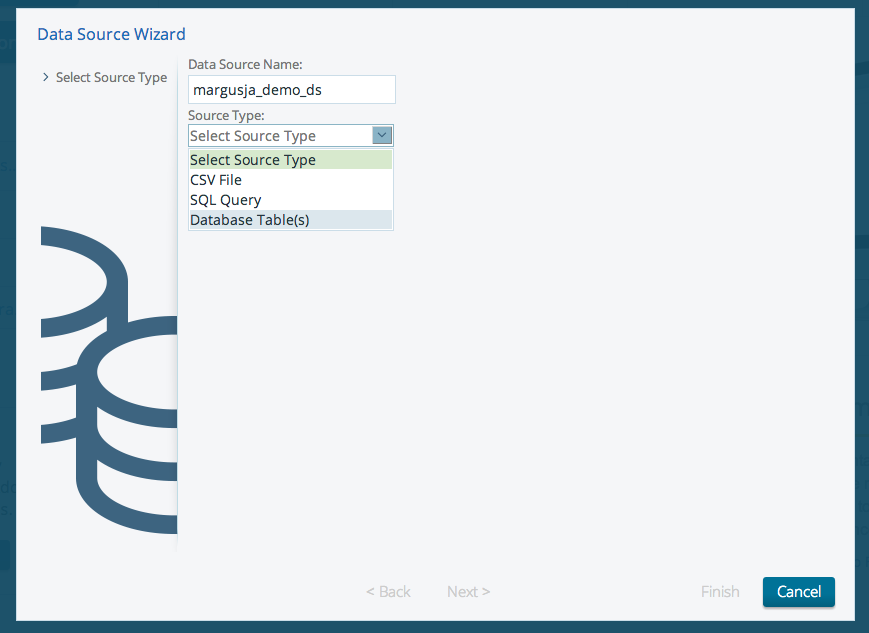
Select your external DB
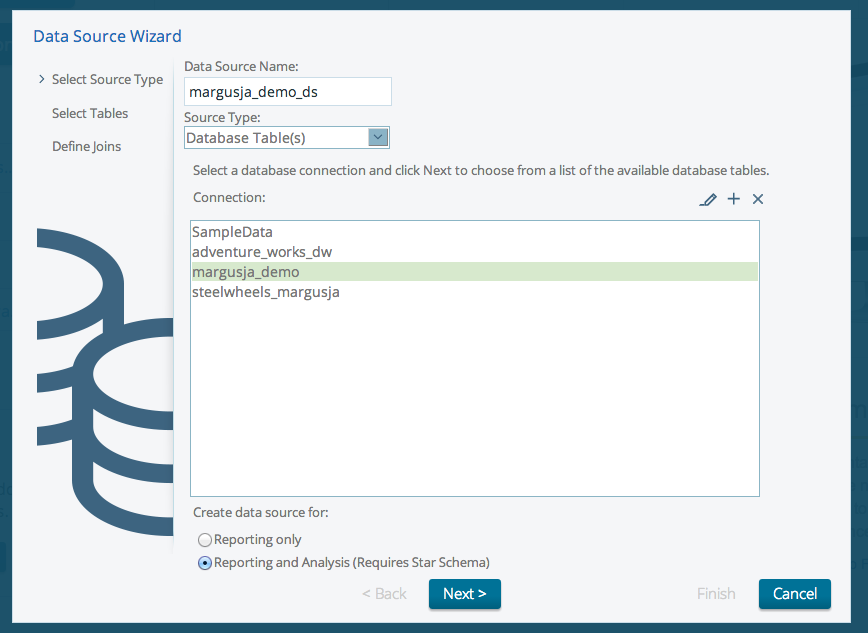
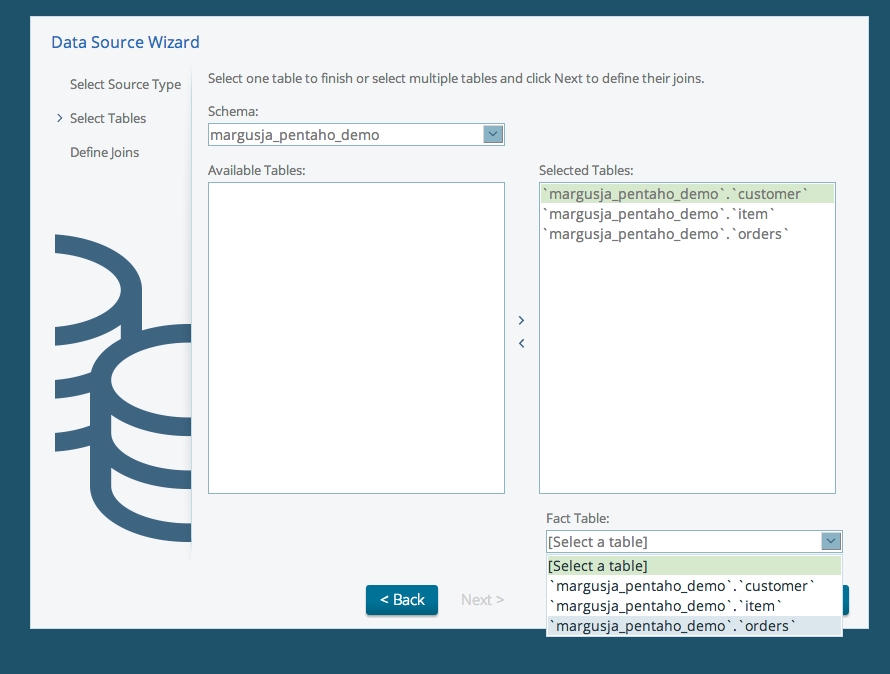
Select fact table as Mondrian star structure requires (Basically you will build Mondrian schema)
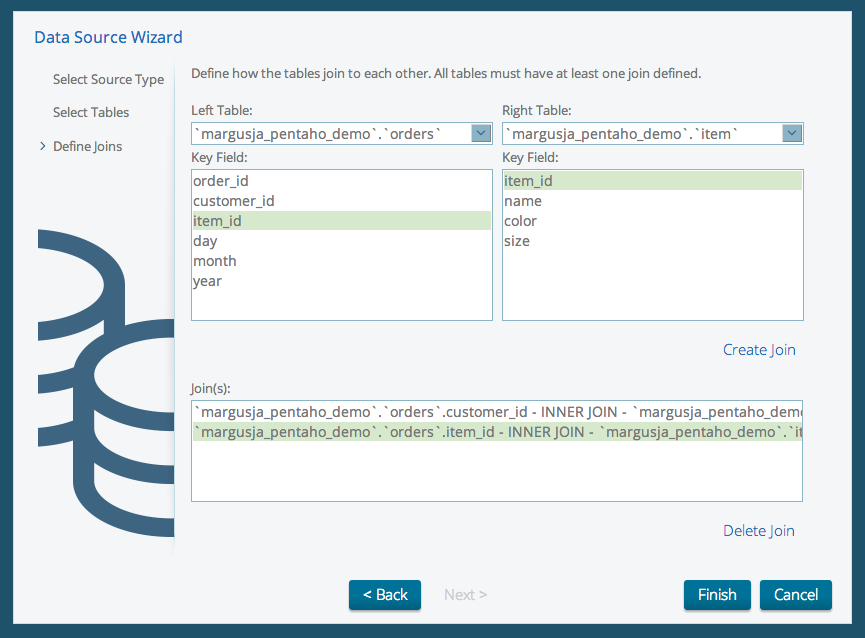
Map facts table to dimension tables
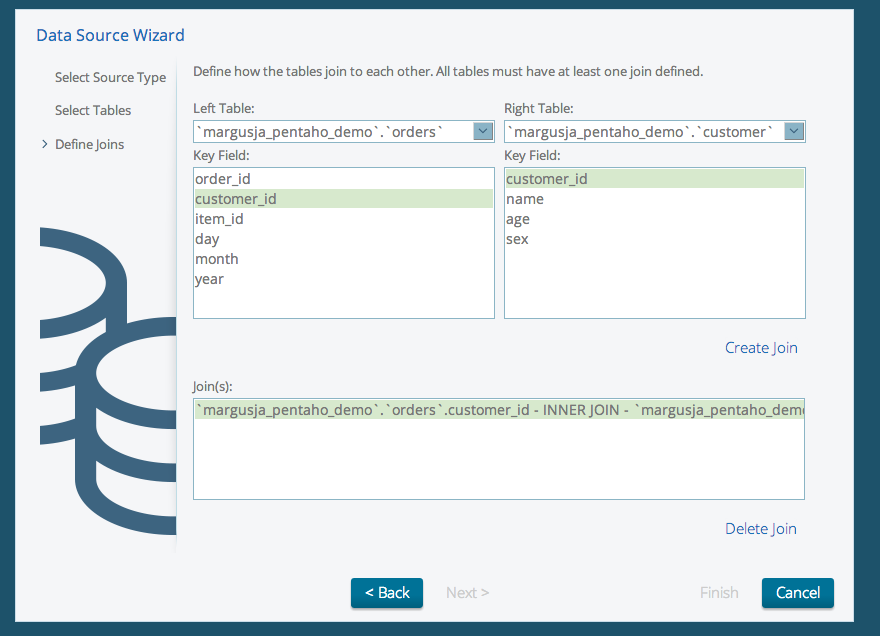
Save it
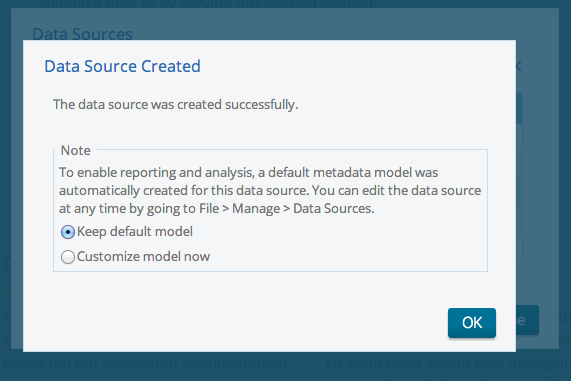
If you want edit mode then choose “Customize model now”
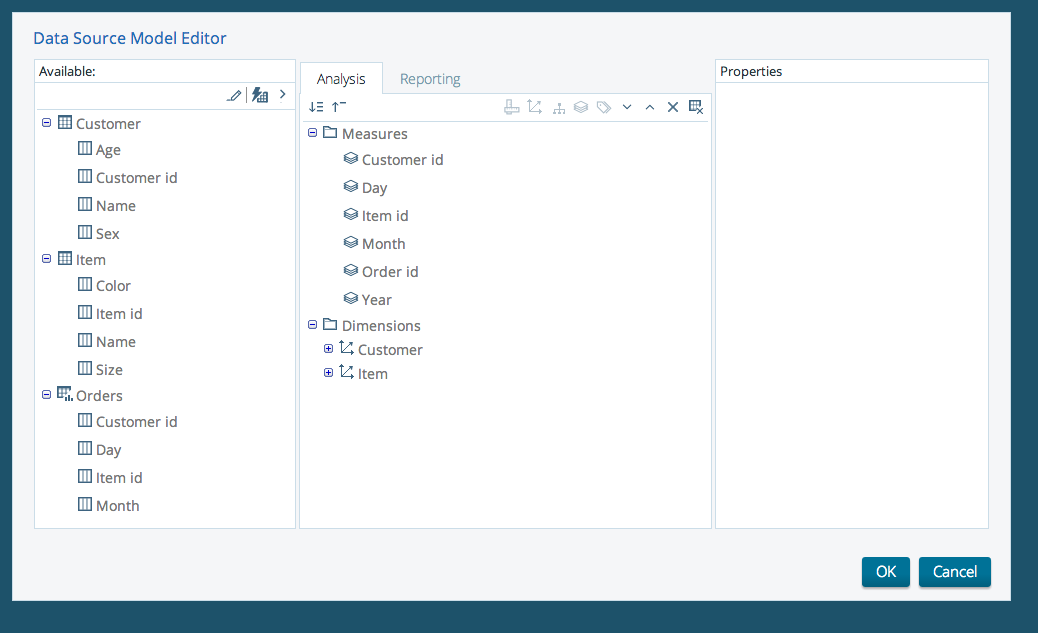
Go and create a new Saiku Analytics
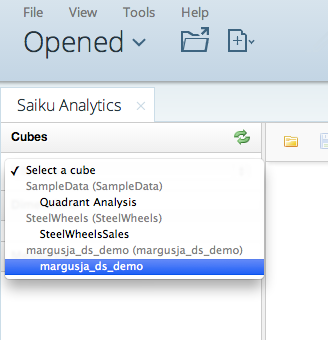
Set columns and rows
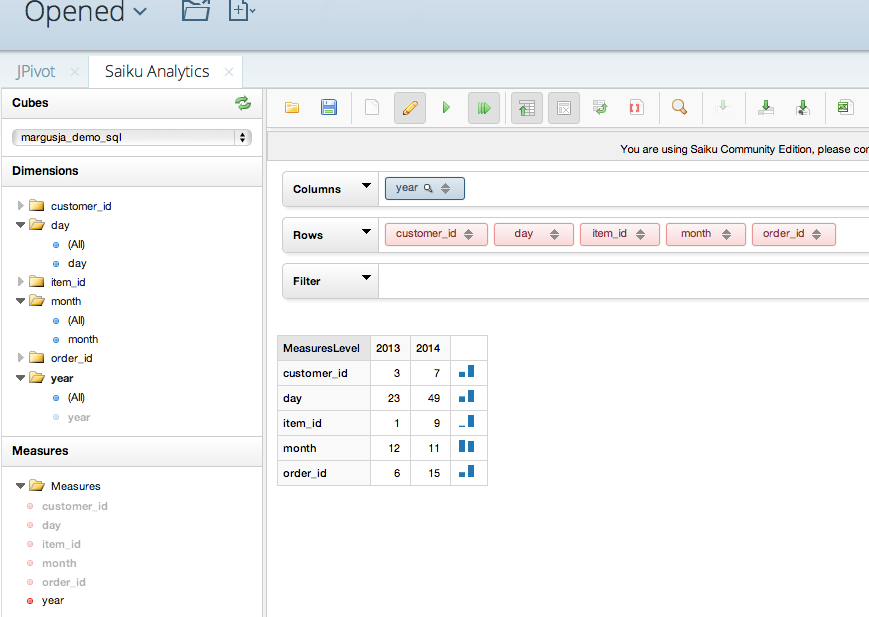
Now you can enjoy your nice graphs
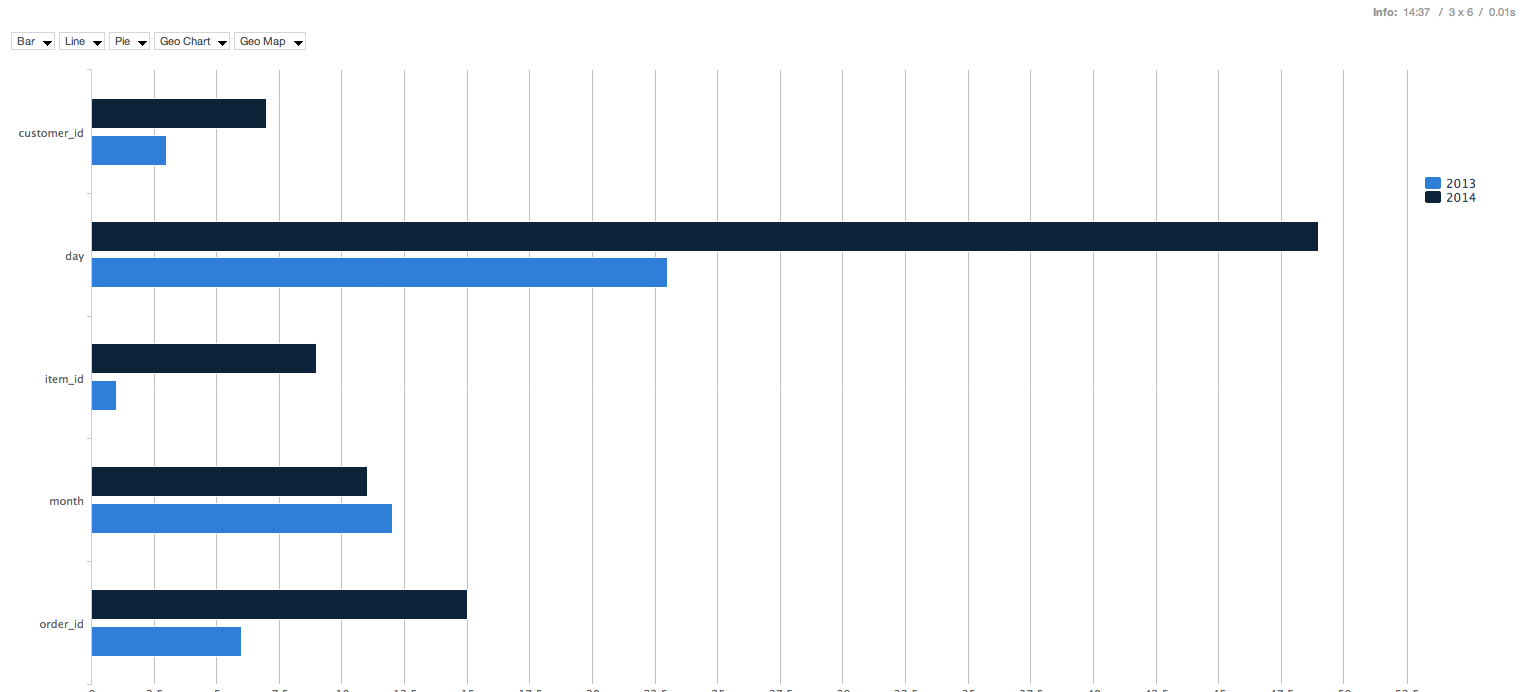
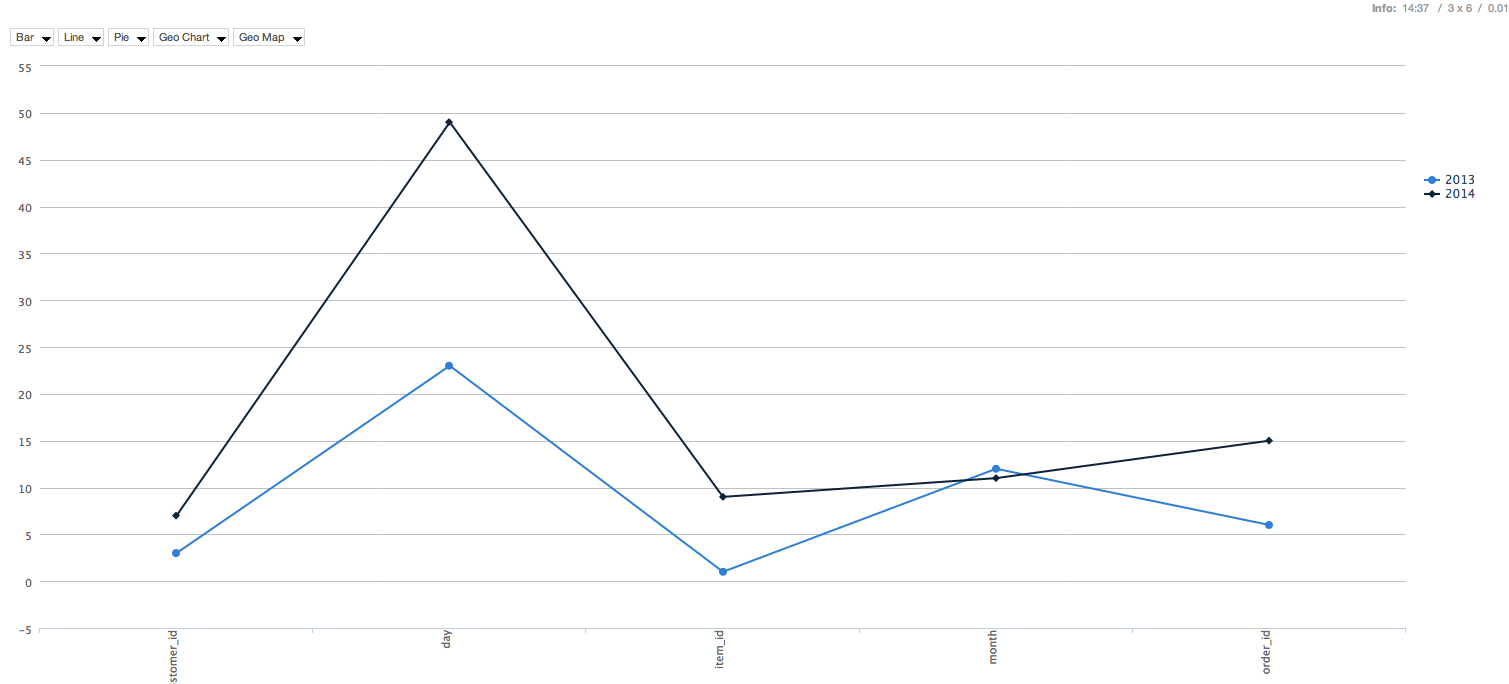
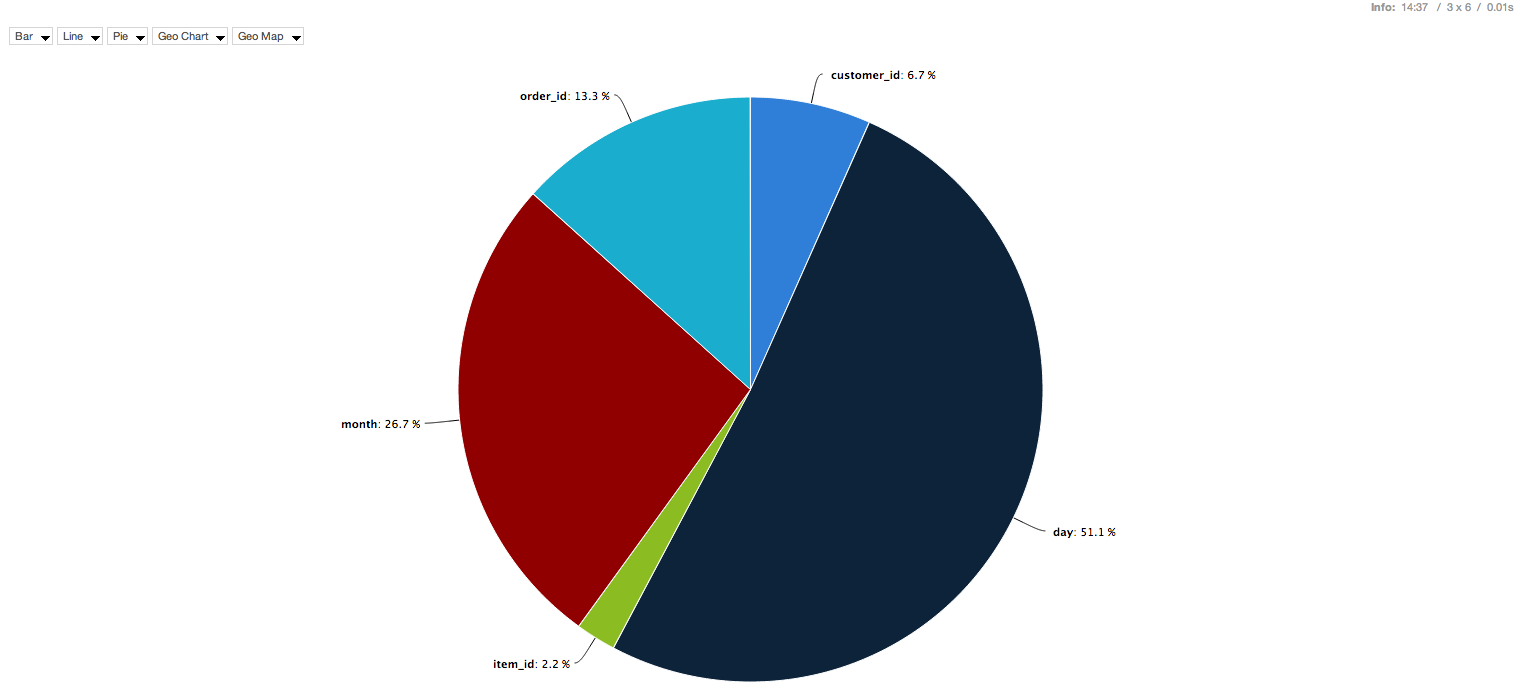
Display and nodes
Raadiomoodul (RFM12B) datasheet 868MHz

Andurid saadavad serial andmeid vastuvõtjasse.
Andmete saatjad. Kasutavad raadiomoodulit RFM12B 868MHz TX seades.
Ühte võrku saab panna suhtlema omavahel 256 raadiot.
Andurite voolutarve on 0.3 mA (IDLE) Optimeeritud patareitoitele. Näiteks 3×1.5 jadamisi 2200mAh on võimalik üle ühe kuu toita.
Andmete saatmise hetkel 0.7mA.
Andureid vajavad loogilist HI 3.3V
Näidikute loogikaosa vajab samuti 3.3V. Minul kasutatavad LCDd vajavad loogilist HI 5V ja taustavalguseks ka 5V


Vastuvõtjad töötavad samuti samade raadiomoodulitega RFM12B 868MHz RX seades.
Lisaks on võimalus vastuvõtja poolt saadud andmed internetis olevasse serverisse saata.


Lets build a calculator
This is the first prototype of simple calculator that can add 4-bits.
Green and blue leds are input registers I can switch with a buttons in the middle. Output register are red leds and the most left one red is carry out.
The chip I use is 74HCT283
Pull down resistors are 4.7K (VCC is 5V)
At the moment I can only add.
In future I’ll implement subtract multiply and divide functions

mahout and recommenditembased
Lets imagine we have data about how user rated our products they have bought.
userID – productID – rate.
So with mahout recommenditembased class we can recommend new products to our users. Here is simple command line example how can we do this.
lets create a file where we are going to put our present data about users, products and rates.
vim intro.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
Put it into hadoop dfs:
hdfs dfs -moveFromLocal intro.csv input/
We need output directory in hadoop dfs:
[speech@h14 ~]$ hdfs dfs -mkdir output
Now we can run recommend command:
[speech@h14 ~]$ mahout/bin/mahout recommenditembased –input input/intro.csv –output output/recommendation -s SIMILARITY_PEARSON_CORRELATION
Our result will be in hadoop dfs output/recommendation
[speech@h14 ~]$ hdfs dfs -cat output/recommendation/part-r-00000
1 [104:3.9258494]
3 [102:3.2698717]
4 [102:4.7433763]
But if we do not have rates. We have only users and items they have bought. We can still use mahout recommenditembased class.
speech@h14 ~]$ vim boolean.csv
1,101
1,102
1,103
2,101
2,102
2,103
2,104
3,101
3,104
3,105
3,107
4,101
4,103
4,104
4,106
5,101
5,102
5,103
5,104
5,105
[speech@h14 ~]$ hdfs dfs -moveFromLocal boolean.cvs input/
[speech@h14 ~]$ mahout/bin/mahout recommenditembased –input /user/speech/input/boolean.csv –output output/boolean -b -s SIMILARITY_LOGLIKELIHOOD
[speech@h14 ~]$ hdfs dfs -cat /user/speech/output/boolean/part-r-00000
1 [104:1.0,105:1.0]
2 [106:1.0,105:1.0]
3 [103:1.0,102:1.0]
4 [105:1.0,102:1.0]
5 [106:1.0,107:1.0]
[speech@h14 ~]$
Audio (Estonian) to text with Kaldi
https://github.com/alumae/kaldi-offline-transcriber
CentOS release 6.5 (Final) Linux vm38 2.6.32-431.3.1.el6.x86_64 #1 SMP Fri Jan 3 21:39:27 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
[root@h14 ~]# yum groupinstall “Development Tools”
[root@h14 ~]# yum install zlib-devel
[root@h14 ~]# yum install java-1.7.0-openjdk.x86_64
[root@vm38 ~]# yum install ffmpeg
[root@vm38 ~]# yum install sox
[root@vm38 ~]# yum install atlas
[root@vm38 ~]# yum install atlas-devel
[root@vm38 ~]# su – margusja
[margusja@vm38 ~]$ mkdir kaldi
[margusja@vm38 ~]$ cd kaldi/
[margusja@vm38 ~]$ mkdir tool
[margusja@vm38 ~]$ cd tools /
[margusja@vm38 ~]$ svn co svn://svn.code.sf.net/p/kaldi/code/trunk kaldi-trunk Hetkel annab alltoodud probleemi ID-2
[margusja@vm38 tools]$ svn co -r 2720 svn://svn.code.sf.net/p/kaldi/code/trunk kaldi-trunk
svn co -r 2720 svn://svn.code.sf.net/p/kaldi/code/trunk kaldi-trunk // 4xxxx series build
[margusja@vm38 ~]$ cd kaldi-trunk/
[margusja@vm38 ~]$ cd tools/
Downloaded http://sourceforge.net/projects/math-atlas/files/Stable/3.10.0/atlas3.10.0.tar.bz2 and build it – huge work!
[margusja@vm38 ~]$ make – Kuna on vana co siis, Makefile sees olevad viited välistele ressursidele on muutunud, mida tuleb uuendada
[margusja@vm38 tools]$ cd ../src/
[margusja@vm38 ~]$ ./configure
[margusja@vm38 ~]$ make depend
[margusja@vm38 ~]$ make test (optional)
[margusja@vm38 ~]$ make valgrind (optional – memory tests can contain errors – takes long time)
[margusja@vm38 ~]$ make
[root@h14 ~]# wget http://mirror-fpt-telecom.fpt.net/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm
[root@h14 ~]# rpm -i epel-release-6-8.noarch.rpm
[root@vm38 ~]# yum install python-pip
[root@vm38 ~]$ CPPFLAGS=”-I/home/margusja/kaldi/tools/kaldi-trunk/tools/openfst/include -L/home/margusja/kaldi/tools/kaldi-trunk/tools/openfst/lib” pip install pyfst
[margusja@vm38 ~]$ cd /home/margusja/kaldi/tools/
[margusja@vm38 tools]$ git clone https://github.com/alumae/kaldi-offline-transcriber.git
[margusja@vm38 tools]$ cd kaldi-offline-transcriber/
[margusja@vm38 kaldi-offline-transcriber]$ curl http://www.phon.ioc.ee/~tanela/kaldi-offline-transcriber-data.tgz | tar xvz
[margusja@vm38 kaldi-offline-transcriber]$ vim Makefile.options // Inside it add a line KALDI_ROOT=/home/margusja/kaldi/tools/kaldi-trunk – whatever where is your path
[margusja@vm38 kaldi-offline-transcriber]$ make .init
…
Problem ID-1:
sox formats: no handler for file extension `mp3′
Solution:
Convert mp3 to ogg
…
Problem ID-2:
steps/decode_nnet_cpu.sh –num-threads 1 –skip-scoring true –cmd “$decode_cmd” –nj 1 \
–transform-dir build/trans/test3/tri3b_mmi_pruned/decode \
build/fst/tri3b/graph_prunedlm build/trans/test3 `dirname build/trans/test3/nnet5c1_pruned/decode/log`
steps/decode_nnet_cpu.sh –num-threads 1 –skip-scoring true –cmd run.pl –nj 1 –transform-dir build/trans/test3/tri3b_mmi_pruned/decode build/fst/tri3b/graph_prunedlm build/trans/test3 build/trans/test3/nnet5c1_pruned/decode
steps/decode_nnet_cpu.sh: feature type is lda
steps/decode_nnet_cpu.sh: using transforms from build/trans/test3/tri3b_mmi_pruned/decode
run.pl: job failed, log is in build/trans/test3/nnet5c1_pruned/decode/log/decode.1.log
make: *** [build/trans/test3/nnet5c1_pruned/decode/log] Error 1
Solution:
[margusja@vm38 tools]$ svn co -r 2720 svn://svn.code.sf.net/p/kaldi/code/trunk kaldi-trunk
…
Problem ID-3
make /build/output/[file].txt annab
EFFECT OPTIONS (effopts): effect dependent; see –help-effect
sox: unrecognized option `–norm’
sox: SoX v14.2.0
Failed: invalid option
Solution hetkel Makefile seest eemaldada –norm võti sox käsult.
…
Problem ID-4
Decoding done.
(cd build/trans/test2/nnet5c1_pruned; ln -s ../../../fst/tri3b/graph_prunedlm graph)
rm -rf build/trans/test2/nnet5c1_pruned_rescored_main
mkdir -p build/trans/test2/nnet5c1_pruned_rescored_main
(cd build/trans/test2/nnet5c1_pruned_rescored_main; for f in ../../../fst/nnet5c1/*; do ln -s $f; done)
local/lmrescore_lowmem.sh –cmd “$decode_cmd” –mode 1 build/fst/data/prunedlm build/fst/data/mainlm \
build/trans/test2 build/trans/test2/nnet5c1_pruned/decode build/trans/test2/nnet5c1_pruned_rescored_main/decode || exit 1;
local/lmrescore_lowmem.sh –cmd run.pl –mode 1 build/fst/data/prunedlm build/fst/data/mainlm build/trans/test2 build/trans/test2/nnet5c1_pruned/decode build/trans/test2/nnet5c1_pruned_rescored_main/decode
run.pl: job failed, log is in build/trans/test2/nnet5c1_pruned_rescored_main/decode/log/rescorelm.JOB.log
queue.pl: probably you forgot to put JOB=1:$nj in your script.
make: *** [build/trans/test2/nnet5c1_pruned_rescored_main/decode/log] Error 1
local/lmrescore_lowmem.sh –cmd utils/run.pl –mode 1 build/fst/data/prunedlm build/fst/data/mainlm build/trans/test2 build/trans/test2/nnet5c1_pruned/decode build/trans/test2/nnet5c1_pruned_rescored_main/decode
run.pl: job failed, log is in build/trans/test2/nnet5c1_pruned_rescored_main/decode/log/rescorelm.JOB.log
queue.pl: probably you forgot to put JOB=1:$nj in your script.
…
Problem ID-5:
/usr/bin/ld: skipping incompatible /usr/lib/libz.so when searching for -lz
Solution:
[root@h14 ~]# rpm -qif /usr/lib/libz.so
Name : zlib-devel Relocations: (not relocatable)
Version : 1.2.3 Vendor: CentOS
Release : 29.el6 Build Date: Fri 22 Feb 2013 01:01:21 AM EET
Install Date: Fri 14 Mar 2014 10:21:49 AM EET Build Host: c6b9.bsys.dev.centos.org
Group : Development/Libraries Source RPM: zlib-1.2.3-29.el6.src.rpm
Size : 117494 License: zlib and Boost
Signature : RSA/SHA1, Sat 23 Feb 2013 07:53:47 PM EET, Key ID 0946fca2c105b9de
Packager : CentOS BuildSystem <http://bugs.centos.org>
URL : http://www.gzip.org/zlib/
Summary : Header files and libraries for Zlib development
Description :
The zlib-devel package contains the header files and libraries needed
to develop programs that use the zlib compression and decompression
library.
[root@h14 ~]# yum install zlib-devel
Hadoop HBase
https://hbase.apache.org/
Use Apache HBase when you need random, realtime read/write access to your Big Data. This project’s goal is the hosting of very large tables — billions of rows X millions of columns — atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google’s Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
Name : hbase
Arch : noarch
Version : 0.96.1.2.0.6.1
Release : 101.el6
Size : 44 M
Repo : HDP-2.0.6
Summary : HBase is the Hadoop database. Use it when you need random, realtime read/write access to your Big Data. This project’s goal is the hosting of very large tables — billions of rows X millions of columns — atop clusters of commodity hardware.
URL : http://hbase.apache.org/
License : APL2
Description : HBase is an open-source, distributed, column-oriented store modeled after Google’ Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, HBase
: provides Bigtable-like capabilities on top of Hadoop. HBase includes:
:
: * Convenient base classes for backing Hadoop MapReduce jobs with HBase tables
: * Query predicate push down via server side scan and get filters
: * Optimizations for real time queries
: * A high performance Thrift gateway
: * A REST-ful Web service gateway that supports XML, Protobuf, and binary data encoding options
: * Cascading source and sink modules
: * Extensible jruby-based (JIRB) shell
: * Support for exporting metrics via the Hadoop metrics subsystem to files or Ganglia; or via JMX
/etc/hosts
90.190.106.56 vm37.dbweb.ee
[root@vm37 ~]# yum install hbase
…
Resolving Dependencies
–> Running transaction check
—> Package hbase.noarch 0:0.96.1.2.0.6.1-101.el6 will be installed
…
Total download size: 44 M
Installed size: 50 M
Is this ok [y/N]: y
Downloading Packages:
hbase-0.96.1.2.0.6.1-101.el6.noarch.rpm | 44 MB 00:23
Running rpm_check_debug
Running Transaction Test
Transaction Test Succeeded
Running Transaction
Installing : hbase-0.96.1.2.0.6.1-101.el6.noarch 1/1
Verifying : hbase-0.96.1.2.0.6.1-101.el6.noarch 1/1
Installed:
hbase.noarch 0:0.96.1.2.0.6.1-101.el6
Complete!
[root@vm37 ~]#
important directories:
/etc/hbase/ – conf
/usr/bin/ – binaries
/usr/lib/hbase/ – libaries
/usr/lib/hbase/logs
/usr/lib/hbase/pids
/var/log/hbase
/var/run/hbase
etc/hbase/conf.dist/hbase-site.xml:
hbase.rootdir
hdfs://vm38.dbweb.ee:8020/user/hbase/data hbase.zookeeper.property.dataDir
hdfs://vm38.dbweb.ee:8020/user/hbase/data hbase.zookeeper.property.clientPort
2181 hbase.zookeeper.quorum
localhost hbase.cluster.distributed
true
[hdfs@vm37 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -mkdir /user/hbase
[hdfs@vm37 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -mkdir /user/hbase/data
[hdfs@vm37 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -chown -R hbase /user/hbase
[root@vm37 ~]# su – hbase
[root@vm37 ~]#export JAVA_HOME=/usr
[root@vm37 ~]#export HBASE_LOG_DIR=/var/log/hbase/
[hbase@vm37 ~]$ /usr/lib/hbase/bin/hbase-daemon.sh start master
#[hbase@vm37 ~]$ /usr/lib/hbase/bin/hbase-daemon.sh start zookeeper – we have distributed zookeepers quad now
starting zookeeper, logging to /var/log/hbase//hbase-hbase-zookeeper-vm37.dbweb.ee.out
[hbase@vm37 ~]$HADOOP_CONF_DIR=/etc/hadoop/conf
starting master, logging to /var/log/hbase//hbase-hbase-master-vm37.dbweb.ee.out
[hbase@vm37 ~]$ /usr/lib/hbase/bin/hbase-daemon.sh start regionserver
starting regionserver, logging to /var/log/hbase//hbase-hbase-regionserver-vm37.dbweb.ee.out
….
Problem:
2014-03-10 10:44:23,331 INFO [main] zookeeper.ZooKeeper: Client environment:java.library.path=:/usr/lib/hadoop/lib/native/Linux-amd64-64:/usr/lib/hadoop/lib/native
2014-03-10 10:44:23,331 INFO [main] zookeeper.ZooKeeper: Client environment:java.io.tmpdir=/tmp
2014-03-10 10:44:23,331 INFO [main] zookeeper.ZooKeeper: Client environment:java.compiler=
2014-03-10 10:44:23,331 INFO [main] zookeeper.ZooKeeper: Client environment:os.name=Linux
2014-03-10 10:44:23,331 INFO [main] zookeeper.ZooKeeper: Client environment:os.arch=amd64
2014-03-10 10:44:23,331 INFO [main] zookeeper.ZooKeeper: Client environment:os.version=2.6.32-431.3.1.el6.x86_64
2014-03-10 10:44:23,331 INFO [main] zookeeper.ZooKeeper: Client environment:user.name=hbase
2014-03-10 10:44:23,331 INFO [main] zookeeper.ZooKeeper: Client environment:user.home=/home/hbase
2014-03-10 10:44:23,331 INFO [main] zookeeper.ZooKeeper: Client environment:user.dir=/home/hbase
2014-03-10 10:44:23,333 INFO [main] zookeeper.ZooKeeper: Initiating client connection, connectString=localhost:2181 sessionTimeout=90000 watcher=master:60000, quorum=localhost:2181, baseZNode=/hbase
2014-03-10 10:44:23,360 INFO [main] zookeeper.RecoverableZooKeeper: Process identifier=master:60000 connecting to ZooKeeper ensemble=localhost:2181
2014-03-10 10:44:23,366 INFO [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Opening socket connection to server localhost/0:0:0:0:0:0:0:1:2181. Will not attempt to authenticate using SASL (unknown error)
2014-03-10 10:44:23,374 WARN [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:361)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1072)
2014-03-10 10:44:23,481 INFO [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2014-03-10 10:44:23,484 WARN [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:361)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1072)
2014-03-10 10:44:23,491 WARN [main] zookeeper.RecoverableZooKeeper: Possibly transient ZooKeeper, quorum=localhost:2181, exception=org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss for /hbase
2014-03-10 10:44:23,491 INFO [main] util.RetryCounter: Sleeping 1000ms before retry #0…
2014-03-10 10:44:24,585 INFO [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Opening socket connection to server localhost/0:0:0:0:0:0:0:1:2181. Will not attempt to authenticate using SASL (unknown error)
2014-03-10 10:44:24,585 WARN [main-SendThread(localhost:2181)] zookeeper.ClientCnxn: Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused
Solution:
Zookeeper have to configured and running before master
….
[hbase@vm37 ~]$ /usr/lib/hbase/bin/hbase shell
2014-03-10 10:24:32,720 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter ‘help’ for list of supported commands.
Type “exit” to leave the HBase Shell
Version 0.96.1.2.0.6.1-101-hadoop2, rcf3f71e5014c66e85c10a244fa9a1e3c43cef077, Wed Jan 8 21:59:02 PST 2014
hbase(main):001:0>
hbase(main):001:0> create ‘test’, ‘cf’
0 row(s) in 11.6950 seconds
=> Hbase::Table – test
hbase(main):002:0> list ‘test’
TABLE
test
1 row(s) in 3.9510 seconds
=> [“test”]
hbase(main):003:0> put ‘test’, ‘row1’, ‘cf:a’, ‘value1’
0 row(s) in 0.1420 seconds
hbase(main):004:0> put ‘test’, ‘row2’, ‘cf:b’, ‘value2’
0 row(s) in 0.0170 seconds
hbase(main):006:0> put ‘test’, ‘row3’, ‘cf:c’, ‘value3’
0 row(s) in 0.0090 seconds
hbase(main):007:0> scan ‘test’
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1394440138295, value=value1
row2 column=cf:b, timestamp=1394440145368, value=value2
row3 column=cf:c, timestamp=1394440161856, value=value3
3 row(s) in 0.0660 seconds
hbase(main):008:0> get ‘test’, ‘row1’
COLUMN CELL
cf:a timestamp=1394440138295, value=value1
1 row(s) in 0.0390 seconds
hbase(main):009:0> disable ‘test’
0 row(s) in 2.6660 seconds
hbase(main):010:0> drop ‘test’
0 row(s) in 0.5050 seconds
hbase(main):011:0> exit
[hbase@vm37 ~]$
…
Problem:
2014-03-10 11:16:33,892 WARN [RpcServer.handler=16,port=60000] master.HMaster: Table Namespace Manager not ready yet
hbase(main):001:0> create ‘test’, ‘cf’
ERROR: java.io.IOException: Table Namespace Manager not ready yet, try again later
at org.apache.hadoop.hbase.master.HMaster.getNamespaceDescriptor(HMaster.java:3092)
at org.apache.hadoop.hbase.master.HMaster.createTable(HMaster.java:1729)
at org.apache.hadoop.hbase.master.HMaster.createTable(HMaster.java:1768)
at org.apache.hadoop.hbase.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java:38221)
at org.apache.hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2175)
at org.apache.hadoop.hbase.ipc.RpcServer$Handler.run(RpcServer.java:1879)
Solution: At least one regionalserver have to by configured and running
…
hbase(main):007:0> status
1 servers, 0 dead, 3.0000 average load
http://vm37:16010/master-status
Map/Reduced Export
[hbase@vm37 ~]$ hbase org.apache.hadoop.hbase.mapreduce.Export test test_out2 and result will be in hdfs://server/user/hbase/test_out2/
hbase(main):001:0> create ‘test2’, ‘cf’
hbase(main):002:0> scan ‘test2’
ROW COLUMN+CELL
0 row(s) in 0.0440 seconds
Map/Reduced Import
[hbase@vm37 ~]$ /usr/lib/hbase/bin/hbase org.apache.hadoop.hbase.mapreduce.Import test2 hdfs://vm38.dbweb.ee:8020/user/hbase/test_out2
hbase(main):004:0> scan ‘test2’
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1394445121367, value=value1
row2 column=cf:b, timestamp=1394445137811, value=value2
row3 column=cf:c, timestamp=1394445149457, value=value3
3 row(s) in 0.0230 seconds
hbase(main):005:0>
Add a new regionserver:
Just add new record in master
[root@vm37 kafka_2.9.1-0.8.1.1]# vim /etc/hbase/conf/regionservers
In hbase-site.xml (master and regionserver(s) ) set at least one common zookeepr server in hbase.zookeeper.quorum.
In slave start regionserver:
/usr/lib/hbase/bin/hbase-daemon.sh –config /etc/hbase/conf start regionserver
Check http://master:16010/master-status are regionservers available
Apache Hive-0.12 and Hadoop-2.2.0
http://hive.apache.org/
The Apache Hive ™ data warehouse software facilitates querying and managing large datasets residing in distributed storage. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.
[root@vm24 ~]# yum install hive
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: ftp.hosteurope.de
* epel: ftp.lysator.liu.se
* extras: ftp.hosteurope.de
* rpmforge: mirror.bacloud.com
* updates: ftp.hosteurope.de
Setting up Install Process
Resolving Dependencies
--> Running transaction check
---> Package hive.noarch 0:0.12.0.2.0.6.1-101.el6 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
================================================================================================================================================================================================================================================================================
Package Arch Version Repository Size
================================================================================================================================================================================================================================================================================
Installing:
hive noarch 0.12.0.2.0.6.1-101.el6 HDP-2.0.6 44 M
Transaction Summary
================================================================================================================================================================================================================================================================================
Install 1 Package(s)
Total download size: 44 M
Installed size: 207 M
Is this ok [y/N]: y
Downloading Packages:
hive-0.12.0.2.0.6.1-101.el6.noarch.rpm | 44 MB 00:19
Running rpm_check_debug
Running Transaction Test
Transaction Test Succeeded
Running Transaction
Installing : hive-0.12.0.2.0.6.1-101.el6.noarch 1/1
Verifying : hive-0.12.0.2.0.6.1-101.el6.noarch 1/1
Installed:
hive.noarch 0:0.12.0.2.0.6.1-101.el6
Complete!
[root@vm24 ~]#
Olulisemad kataloogid, mis tekkisid (rpm -ql hive)
/usr/lib/hive/ – see peaks olema hive home
/var/lib/hive
/var/lib/hive/metastore
/var/log/hive
/var/run/hive
[root@vm24 ~]# su – hive
[hive@vm24 ~]$ export HIVE_HOME=/usr/lib/hive
[hive@vm24 ~]$ export HADOOP_HOME=/usr/lib/hadoop
[hdfs@vm24 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -mkdir /user/hive
[hdfs@vm24 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -mkdir /user/hive/warehouse
[hdfs@vm24 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -chmod g+w /tmp
[hdfs@vm24 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -chmod g+w /user/hive/warehouse
[hdfs@vm24 ~]$ /usr/lib/hadoop-hdfs/bin/hdfs dfs -chown -R hive /user/hive/
[hdfs@vm24 ~]$
[hive@vm24 ~]$ /usr/lib/hive/bin/hive
Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path
[hive@vm24 ~]$
Ilmselt olen segamine ajanud hadoop ja hadoop-hdfs
[hive@vm24 ~]$ export HADOOP_HOME=/usr/lib/hadoop
[hive@vm24 ~]$ /usr/lib/hive/bin/hive
Error: JAVA_HOME is not set and could not be found.
Unable to determine Hadoop version information.
'hadoop version' returned:
Error: JAVA_HOME is not set and could not be found.
[hive@vm24 ~]$
[hive@vm24 ~]$ export JAVA_HOME=/usr
[hive@vm24 ~]$ /usr/lib/hive/bin/hive
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
14/03/07 11:49:15 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
Logging initialized using configuration in jar:file:/usr/lib/hive/lib/hive-common-0.12.0.2.0.6.1-101.jar!/hive-log4j.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/lib/hadoop/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/hive/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive>
Session on hive:
[hive@vm24 ~]$ wget https://hadoop-clusternet.googlecode.com/svn-history/r20/trunk/clusternet/thirdparty/data/ml-data.tar__0.gz
–2014-03-07 11:53:56– https://hadoop-clusternet.googlecode.com/svn-history/r20/trunk/clusternet/thirdparty/data/ml-data.tar__0.gz
Resolving hadoop-clusternet.googlecode.com… 2a00:1450:4001:c02::52, 173.194.70.82
Connecting to hadoop-clusternet.googlecode.com|2a00:1450:4001:c02::52|:443… connected.
HTTP request sent, awaiting response… 200 OK
Length: 4948405 (4.7M) [application/octet-stream]
Saving to: “ml-data.tar__0.gz”
100%[======================================================================================================================================================================================================================================>] 4,948,405 609K/s in 7.1s
2014-03-07 11:54:03 (681 KB/s) – “ml-data.tar__0.gz” saved [4948405/4948405]
[hive@vm24 ~]$
[hive@vm24 ~]$ tar zxvf ml-data.tar__0.gz
ml-data/
ml-data/README
ml-data/allbut.pl
ml-data/mku.sh
ml-data/u.data
ml-data/u.genre
ml-data/u.info
ml-data/u.item
ml-data/u.occupation
ml-data/u.user
ml-data/ub.test
ml-data/u1.test
ml-data/u1.base
ml-data/u2.test
ml-data/u2.base
ml-data/u3.test
ml-data/u3.base
ml-data/u4.test
ml-data/u4.base
ml-data/u5.test
ml-data/u5.base
ml-data/ua.test
ml-data/ua.base
ml-data/ub.base
[hive@vm24 ~]$
hive> CREATE TABLE u_data (
> userid INT,
> movieid INT,
> rating INT,
> unixtime STRING)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ‘\t’
> STORED AS TEXTFILE;
hive> LOAD DATA LOCAL INPATH ‘ml-data/u.data’
> OVERWRITE INTO TABLE u_data;
Copying data from file:/home/hive/ml-data/u.data
Copying file: file:/home/hive/ml-data/u.data
Loading data to table default.u_data
Table default.u_data stats: [num_partitions: 0, num_files: 1, num_rows: 0, total_size: 1979173, raw_data_size: 0]
OK
Time taken: 3.0 seconds
hive>
hive> SELECT COUNT(*) FROM u_data;
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapred.reduce.tasks=
Starting Job = job_1394027471317_0016, Tracking URL = http://vm38:8088/proxy/application_1394027471317_0016/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1394027471317_0016
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2014-03-07 11:59:47,212 Stage-1 map = 0%, reduce = 0%
2014-03-07 11:59:57,933 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 11:59:58,998 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:00,094 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:01,157 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:02,212 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:03,268 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:04,323 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:05,378 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:06,434 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:07,489 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:08,573 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:09,630 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.14 sec
2014-03-07 12:00:10,697 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.14 sec
2014-03-07 12:00:11,745 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.14 sec
MapReduce Total cumulative CPU time: 5 seconds 140 msec
Ended Job = job_1394027471317_0016
MapReduce Jobs Launched:
Job 0: Map: 1 Reduce: 1 Cumulative CPU: 5.14 sec HDFS Read: 1979386 HDFS Write: 7 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 140 msec
OK
100000
Time taken: 67.285 seconds, Fetched: 1 row(s)
hive>
Siin on ka näha, et hadoop arvutusosa tegeleb antud tööga(1394027471317_0016):
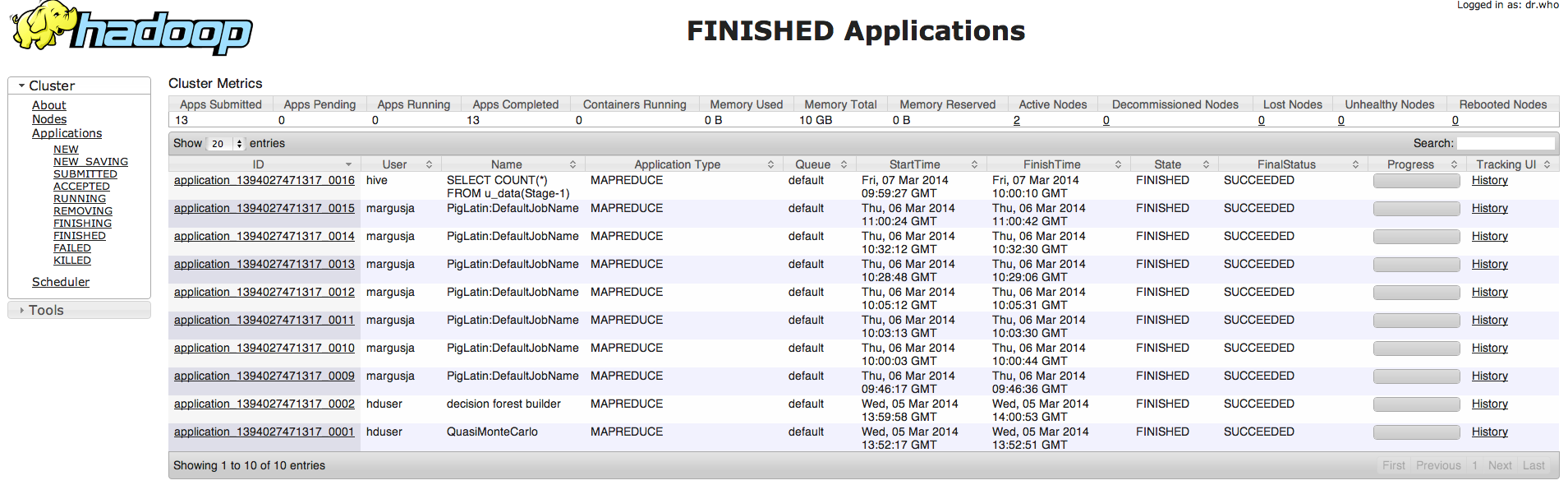
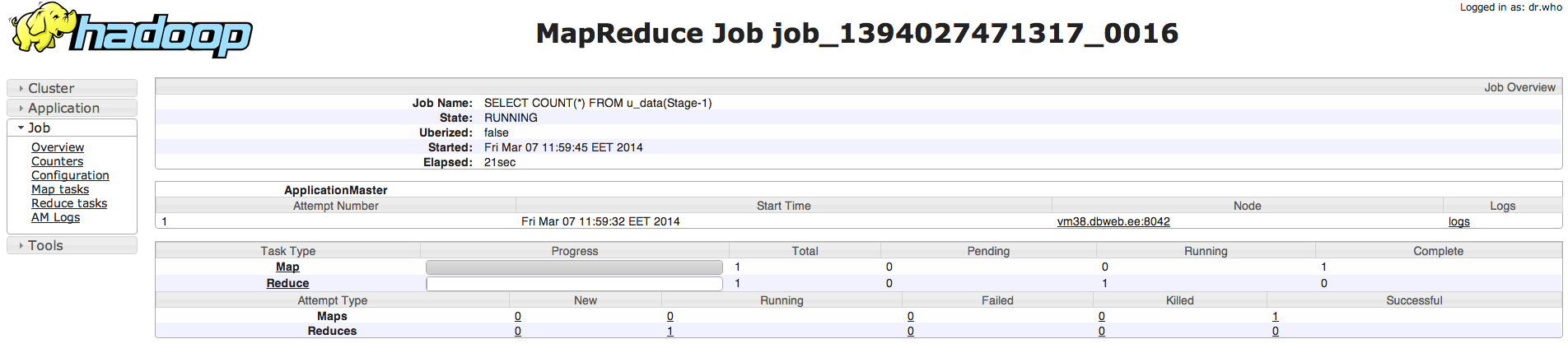
[hive@vm24 ~]$ hive –service hiveserver
Starting Hive Thrift Server
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
14/03/11 15:21:05 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/lib/hadoop/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/hive/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
…
Start Web UI
/etc/hive/conf/hive-site.xml
[hive@vm24 ~]$ hive –service hwi
14/03/11 15:14:57 INFO hwi.HWIServer: HWI is starting up
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
14/03/11 15:14:58 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/lib/hadoop/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/hive/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
14/03/11 15:14:59 INFO mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog
14/03/11 15:14:59 INFO mortbay.log: jetty-6.1.26
14/03/11 15:14:59 INFO mortbay.log: Extract /usr/lib/hive/lib/hive-hwi-0.12.0.2.0.6.1-101.war to /tmp/Jetty_0_0_0_0_9999_hive.hwi.0.12.0.2.0.6.1.101.war__hwi__4ykn6s/webapp
14/03/11 15:15:00 INFO mortbay.log: Started SocketConnector@0.0.0.0:9999
http://vm24:9999/hwi/
[hive@vm24 ~]$ hive –service metastore -p 10000
Starting Hive Metastore Server
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
14/03/11 16:00:26 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/lib/hadoop/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/lib/hive/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
…
Eelnevalt teised hive teenused sulgeda, kuna praeguse seadistusega lukustatakse Derby andmebaas
Metastore