MCP1703
Pig install, configure to use remote hadoop-yarn resourcemanager and a simple session
https://pig.apache.org/ pig.noarch : Pig is a platform for analyzing large data sets
[root@vm24 ~]# yum install pig
Loading mirror speeds from cached hostfile
* base: mirrors.coreix.net
* epel: ftp.lysator.liu.se
* extras: mirrors.coreix.net
* rpmforge: mirror.bacloud.com
* updates: mirrors.coreix.net
Setting up Install Process
Resolving Dependencies
–> Running transaction check
—> Package pig.noarch 0:0.12.0.2.0.6.1-101.el6 will be installed
–> Processing Dependency: hadoop-client for package: pig-0.12.0.2.0.6.1-101.el6.noarch
–> Running transaction check
—> Package hadoop-client.x86_64 0:2.2.0.2.0.6.0-101.el6 will be installed
–> Processing Dependency: hadoop-yarn = 2.2.0.2.0.6.0-101.el6 for package: hadoop-client-2.2.0.2.0.6.0-101.el6.x86_64
–> Processing Dependency: hadoop-mapreduce = 2.2.0.2.0.6.0-101.el6 for package: hadoop-client-2.2.0.2.0.6.0-101.el6.x86_64
–> Processing Dependency: hadoop-hdfs = 2.2.0.2.0.6.0-101.el6 for package: hadoop-client-2.2.0.2.0.6.0-101.el6.x86_64
–> Processing Dependency: hadoop = 2.2.0.2.0.6.0-101.el6 for package: hadoop-client-2.2.0.2.0.6.0-101.el6.x86_64
–> Running transaction check
—> Package hadoop.x86_64 0:2.2.0.2.0.6.0-101.el6 will be installed
—> Package hadoop-hdfs.x86_64 0:2.2.0.2.0.6.0-101.el6 will be installed
—> Package hadoop-mapreduce.x86_64 0:2.2.0.2.0.6.0-101.el6 will be installed
—> Package hadoop-yarn.x86_64 0:2.2.0.2.0.6.0-101.el6 will be installed
–> Finished Dependency Resolution
Dependencies Resolved
================================================================================================================================================================================================================================================================================
Package Arch Version Repository Size
================================================================================================================================================================================================================================================================================
Installing:
pig noarch 0.12.0.2.0.6.1-101.el6 HDP-2.0.6 64 M
Installing for dependencies:
hadoop x86_64 2.2.0.2.0.6.0-101.el6 HDP-2.0.6 18 M
hadoop-client x86_64 2.2.0.2.0.6.0-101.el6 HDP-2.0.6 9.2 k
hadoop-hdfs x86_64 2.2.0.2.0.6.0-101.el6 HDP-2.0.6 13 M
hadoop-mapreduce x86_64 2.2.0.2.0.6.0-101.el6 HDP-2.0.6 11 M
hadoop-yarn x86_64 2.2.0.2.0.6.0-101.el6 HDP-2.0.6 9.5 M
Transaction Summary
================================================================================================================================================================================================================================================================================
Install 6 Package(s)
Total download size: 115 M
Installed size: 191 M
Is this ok [y/N]: y
Downloading Packages:
(1/6): hadoop-2.2.0.2.0.6.0-101.el6.x86_64.rpm | 18 MB 00:11
(2/6): hadoop-client-2.2.0.2.0.6.0-101.el6.x86_64.rpm | 9.2 kB 00:00
(3/6): hadoop-hdfs-2.2.0.2.0.6.0-101.el6.x86_64.rpm | 13 MB 00:05
(4/6): hadoop-mapreduce-2.2.0.2.0.6.0-101.el6.x86_64.rpm | 11 MB 00:06
(5/6): hadoop-yarn-2.2.0.2.0.6.0-101.el6.x86_64.rpm | 9.5 MB 00:05
(6/6): pig-0.12.0.2.0.6.1-101.el6.noarch.rpm | 64 MB 00:26
——————————————————————————————————————————————————————————————————————————————————————————–
Total 2.0 MB/s | 115 MB 00:56
Running rpm_check_debug
Running Transaction Test
Transaction Test Succeeded
Running Transaction
Installing : hadoop-2.2.0.2.0.6.0-101.el6.x86_64 1/6
Installing : hadoop-yarn-2.2.0.2.0.6.0-101.el6.x86_64 2/6
warning: group yarn does not exist – using root
Installing : hadoop-mapreduce-2.2.0.2.0.6.0-101.el6.x86_64 3/6
Installing : hadoop-hdfs-2.2.0.2.0.6.0-101.el6.x86_64 4/6
Installing : hadoop-client-2.2.0.2.0.6.0-101.el6.x86_64 5/6
Installing : pig-0.12.0.2.0.6.1-101.el6.noarch 6/6
Verifying : hadoop-yarn-2.2.0.2.0.6.0-101.el6.x86_64 1/6
Verifying : hadoop-client-2.2.0.2.0.6.0-101.el6.x86_64 2/6
Verifying : hadoop-2.2.0.2.0.6.0-101.el6.x86_64 3/6
Verifying : hadoop-hdfs-2.2.0.2.0.6.0-101.el6.x86_64 4/6
Verifying : pig-0.12.0.2.0.6.1-101.el6.noarch 5/6
Verifying : hadoop-mapreduce-2.2.0.2.0.6.0-101.el6.x86_64 6/6
Installed:
pig.noarch 0:0.12.0.2.0.6.1-101.el6
Dependency Installed:
hadoop.x86_64 0:2.2.0.2.0.6.0-101.el6 hadoop-client.x86_64 0:2.2.0.2.0.6.0-101.el6 hadoop-hdfs.x86_64 0:2.2.0.2.0.6.0-101.el6 hadoop-mapreduce.x86_64 0:2.2.0.2.0.6.0-101.el6 hadoop-yarn.x86_64 0:2.2.0.2.0.6.0-101.el6
Complete!
[root@vm24 ~]#
[root@vm24 ~]# su – margusja
[margusja@vm24 ~]$ pig
which: no hbase in (:/usr/local/apache-maven-3.1.1/bin:/usr/lib64/qt-3.3/bin:/usr/local/maven/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/margusja/bin)
2014-03-06 10:17:18,392 [main] INFO org.apache.pig.Main – Apache Pig version 0.12.0.2.0.6.1-101 (rexported) compiled Jan 08 2014, 22:49:47
2014-03-06 10:17:18,393 [main] INFO org.apache.pig.Main – Logging error messages to: /home/margusja/pig_1394093838389.log
2014-03-06 10:17:18,690 [main] INFO org.apache.pig.impl.util.Utils – Default bootup file /home/margusja/.pigbootup not found
2014-03-06 10:17:19,680 [main] INFO org.apache.hadoop.conf.Configuration.deprecation – mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2014-03-06 10:17:19,680 [main] INFO org.apache.hadoop.conf.Configuration.deprecation – fs.default.name is deprecated. Instead, use fs.defaultFS
2014-03-06 10:17:19,680 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine – Connecting to hadoop file system at: file:///
2014-03-06 10:17:19,692 [main] INFO org.apache.hadoop.conf.Configuration.deprecation – mapred.used.genericoptionsparser is deprecated. Instead, use mapreduce.client.genericoptionsparser.used
2014-03-06 10:17:22,675 [main] INFO org.apache.hadoop.conf.Configuration.deprecation – fs.default.name is deprecated. Instead, use fs.defaultFS
grunt>
—
Siinkohal tehes päringut ebaõnnestume, sest pig ei tea olulisi parameetreid hadoop ja yarn keskkondade kohta.
Üks võimalus, mida mina kasutan – määrata PIG_CLASSPATH=/etc/hadoop/conf, kus omakorda
yarn-site.xml:
mapred-site.xml:
core-site.xml:
Nüüd on pig kliendil piisavalt informatsiooni, et saata map-reduce tööd hadoop-yarn ressursijaotajale, kes omakorda jagab töö temale kättesaadavate ressursside (nodemanageride) vahel.
Näide pig sessioonist:
[margusja@vm24 ~]$ env
SHELL=/bin/bash
TERM=xterm-256color
HADOOP_HOME=/usr/lib/hadoop
HISTSIZE=1000
QTDIR=/usr/lib64/qt-3.3
QTINC=/usr/lib64/qt-3.3/include
USER=margusja
LS_COLORS=rs=0:di=38;5;27:ln=38;5;51:mh=44;38;5;15:pi=40;38;5;11:so=38;5;13:do=38;5;5:bd=48;5;232;38;5;11:cd=48;5;232;38;5;3:or=48;5;232;38;5;9:mi=05;48;5;232;38;5;15:su=48;5;196;38;5;15:sg=48;5;11;38;5;16:ca=48;5;196;38;5;226:tw=48;5;10;38;5;16:ow=48;5;10;38;5;21:st=48;5;21;38;5;15:ex=38;5;34:*.tar=38;5;9:*.tgz=38;5;9:*.arj=38;5;9:*.taz=38;5;9:*.lzh=38;5;9:*.lzma=38;5;9:*.tlz=38;5;9:*.txz=38;5;9:*.zip=38;5;9:*.z=38;5;9:*.Z=38;5;9:*.dz=38;5;9:*.gz=38;5;9:*.lz=38;5;9:*.xz=38;5;9:*.bz2=38;5;9:*.tbz=38;5;9:*.tbz2=38;5;9:*.bz=38;5;9:*.tz=38;5;9:*.deb=38;5;9:*.rpm=38;5;9:*.jar=38;5;9:*.rar=38;5;9:*.ace=38;5;9:*.zoo=38;5;9:*.cpio=38;5;9:*.7z=38;5;9:*.rz=38;5;9:*.jpg=38;5;13:*.jpeg=38;5;13:*.gif=38;5;13:*.bmp=38;5;13:*.pbm=38;5;13:*.pgm=38;5;13:*.ppm=38;5;13:*.tga=38;5;13:*.xbm=38;5;13:*.xpm=38;5;13:*.tif=38;5;13:*.tiff=38;5;13:*.png=38;5;13:*.svg=38;5;13:*.svgz=38;5;13:*.mng=38;5;13:*.pcx=38;5;13:*.mov=38;5;13:*.mpg=38;5;13:*.mpeg=38;5;13:*.m2v=38;5;13:*.mkv=38;5;13:*.ogm=38;5;13:*.mp4=38;5;13:*.m4v=38;5;13:*.mp4v=38;5;13:*.vob=38;5;13:*.qt=38;5;13:*.nuv=38;5;13:*.wmv=38;5;13:*.asf=38;5;13:*.rm=38;5;13:*.rmvb=38;5;13:*.flc=38;5;13:*.avi=38;5;13:*.fli=38;5;13:*.flv=38;5;13:*.gl=38;5;13:*.dl=38;5;13:*.xcf=38;5;13:*.xwd=38;5;13:*.yuv=38;5;13:*.cgm=38;5;13:*.emf=38;5;13:*.axv=38;5;13:*.anx=38;5;13:*.ogv=38;5;13:*.ogx=38;5;13:*.aac=38;5;45:*.au=38;5;45:*.flac=38;5;45:*.mid=38;5;45:*.midi=38;5;45:*.mka=38;5;45:*.mp3=38;5;45:*.mpc=38;5;45:*.ogg=38;5;45:*.ra=38;5;45:*.wav=38;5;45:*.axa=38;5;45:*.oga=38;5;45:*.spx=38;5;45:*.xspf=38;5;45:
MAIL=/var/spool/mail/margusja
PATH=/usr/local/apache-maven-3.1.1/bin:/usr/lib64/qt-3.3/bin:/usr/local/maven/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/margusja/bin
PWD=/home/margusja
JAVA_HOME=/usr/lib/jvm/jre-1.7.0
EDITOR=/usr/bin/vim
PIG_CLASSPATH=/etc/hadoop/conf
LANG=en_US.UTF-8
HISTCONTROL=ignoredups
M2_HOME=/usr/local/apache-maven-3.1.1
SHLVL=1
HOME=/home/margusja
LOGNAME=margusja
QTLIB=/usr/lib64/qt-3.3/lib
CVS_RSH=ssh
LESSOPEN=|/usr/bin/lesspipe.sh %s
G_BROKEN_FILENAMES=1
_=/bin/env
[margusja@vm24 ~]$
[margusja@vm24 ~]$ pig
which: no hbase in (:/usr/local/apache-maven-3.1.1/bin:/usr/lib64/qt-3.3/bin:/usr/local/maven/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/margusja/bin)
2014-03-06 11:55:56,557 [main] INFO org.apache.pig.Main – Apache Pig version 0.12.0.2.0.6.1-101 (rexported) compiled Jan 08 2014, 22:49:47
2014-03-06 11:55:56,558 [main] INFO org.apache.pig.Main – Logging error messages to: /home/margusja/pig_1394099756554.log
2014-03-06 11:55:56,605 [main] INFO org.apache.pig.impl.util.Utils – Default bootup file /home/margusja/.pigbootup not found
2014-03-06 11:55:57,292 [main] INFO org.apache.hadoop.conf.Configuration.deprecation – mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2014-03-06 11:55:57,292 [main] INFO org.apache.hadoop.conf.Configuration.deprecation – fs.default.name is deprecated. Instead, use fs.defaultFS
2014-03-06 11:55:57,292 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine – Connecting to hadoop file system at: hdfs://vm38:8020
2014-03-06 11:55:57,304 [main] INFO org.apache.hadoop.conf.Configuration.deprecation – mapred.used.genericoptionsparser is deprecated. Instead, use mapreduce.client.genericoptionsparser.used
2014-03-06 11:56:02,676 [main] INFO org.apache.hadoop.conf.Configuration.deprecation – fs.default.name is deprecated. Instead, use fs.defaultFS
grunt>
grunt> A = load ‘passwd’ using PigStorage(‘:’); (passwd fail peab olema eelnevalt vastava kasutaja dfs kodukatakoogis – /usr/lib/hadoop-hdfs/bin/hdfs dfs -put /etc/passwd /user/margusja)
grunt> B = foreach A generate $0 as id; (passwd failis omistame esimesel real oleva id muutujasse)
grunt> dump B;
2014-03-06 12:28:36,225 [main] INFO org.apache.pig.tools.pigstats.ScriptState – Pig features used in the script: UNKNOWN
2014-03-06 12:28:36,287 [main] INFO org.apache.pig.newplan.logical.optimizer.LogicalPlanOptimizer – {RULES_ENABLED=[AddForEach, ColumnMapKeyPrune, DuplicateForEachColumnRewrite, GroupByConstParallelSetter, ImplicitSplitInserter, LimitOptimizer, LoadTypeCastInserter, MergeFilter, MergeForEach, NewPartitionFilterOptimizer, PartitionFilterOptimizer, PushDownForEachFlatten, PushUpFilter, SplitFilter, StreamTypeCastInserter], RULES_DISABLED=[FilterLogicExpressionSimplifier]}
2014-03-06 12:28:36,459 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MRCompiler – File concatenation threshold: 100 optimistic? false
2014-03-06 12:28:36,499 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer – MR plan size before optimization: 1
2014-03-06 12:28:36,499 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer – MR plan size after optimization: 1
2014-03-06 12:28:36,926 [main] INFO org.apache.hadoop.yarn.client.RMProxy – Connecting to ResourceManager at vm38/90.190.106.33:8032
2014-03-06 12:28:37,167 [main] INFO org.apache.pig.tools.pigstats.ScriptState – Pig script settings are added to the job
2014-03-06 12:28:37,194 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler – mapred.job.reduce.markreset.buffer.percent is not set, set to default 0.3
2014-03-06 12:28:37,204 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler – creating jar file Job5693330381910866671.jar
2014-03-06 12:28:45,595 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler – jar file Job5693330381910866671.jar created
2014-03-06 12:28:45,595 [main] INFO org.apache.hadoop.conf.Configuration.deprecation – mapred.jar is deprecated. Instead, use mapreduce.job.jar
2014-03-06 12:28:45,635 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler – Setting up single store job
2014-03-06 12:28:45,658 [main] INFO org.apache.pig.data.SchemaTupleFrontend – Key [pig.schematuple] is false, will not generate code.
2014-03-06 12:28:45,658 [main] INFO org.apache.pig.data.SchemaTupleFrontend – Starting process to move generated code to distributed cache
2014-03-06 12:28:45,661 [main] INFO org.apache.pig.data.SchemaTupleFrontend – Setting key [pig.schematuple.classes] with classes to deserialize []
2014-03-06 12:28:45,737 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher – 1 map-reduce job(s) waiting for submission.
2014-03-06 12:28:45,765 [JobControl] INFO org.apache.hadoop.yarn.client.RMProxy – Connecting to ResourceManager at vm38/x.x.x.x:8032
2014-03-06 12:28:45,873 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – fs.default.name is deprecated. Instead, use fs.defaultFS
2014-03-06 12:28:45,875 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – mapreduce.job.counters.limit is deprecated. Instead, use mapreduce.job.counters.max
2014-03-06 12:28:45,875 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
2014-03-06 12:28:45,875 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – mapred.job.name is deprecated. Instead, use mapreduce.job.name
2014-03-06 12:28:45,875 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – mapreduce.inputformat.class is deprecated. Instead, use mapreduce.job.inputformat.class
2014-03-06 12:28:45,876 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
2014-03-06 12:28:45,876 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
2014-03-06 12:28:45,876 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – mapreduce.outputformat.class is deprecated. Instead, use mapreduce.job.outputformat.class
2014-03-06 12:28:45,876 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
2014-03-06 12:28:46,822 [JobControl] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat – Total input paths to process : 1
2014-03-06 12:28:46,822 [JobControl] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil – Total input paths to process : 1
2014-03-06 12:28:46,858 [JobControl] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil – Total input paths (combined) to process : 1
2014-03-06 12:28:46,992 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter – number of splits:1
2014-03-06 12:28:47,008 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – user.name is deprecated. Instead, use mapreduce.job.user.name
2014-03-06 12:28:47,009 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – fs.default.name is deprecated. Instead, use fs.defaultFS
2014-03-06 12:28:47,011 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – mapreduce.job.counters.limit is deprecated. Instead, use mapreduce.job.counters.max
2014-03-06 12:28:47,014 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
2014-03-06 12:28:47,014 [JobControl] INFO org.apache.hadoop.conf.Configuration.deprecation – mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
2014-03-06 12:28:47,674 [JobControl] INFO org.apache.hadoop.mapreduce.JobSubmitter – Submitting tokens for job: job_1394027471317_0013
2014-03-06 12:28:48,137 [JobControl] INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl – Submitted application application_1394027471317_0013 to ResourceManager at vm38/x.x.x.x:8032
2014-03-06 12:28:48,221 [JobControl] INFO org.apache.hadoop.mapreduce.Job – The url to track the job: http://vm38:8088/proxy/application_1394027471317_0013/
2014-03-06 12:28:48,222 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher – HadoopJobId: job_1394027471317_0013
2014-03-06 12:28:48,222 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher – Processing aliases A,B
2014-03-06 12:28:48,222 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher – detailed locations: M: A[1,4],B[2,4] C: R:
2014-03-06 12:28:48,293 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher – 0% complete
2014-03-06 12:29:06,570 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher – 50% complete
2014-03-06 12:29:09,274 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher – 100% complete
2014-03-06 12:29:09,277 [main] INFO org.apache.pig.tools.pigstats.SimplePigStats – Script Statistics:
HadoopVersion PigVersion UserId StartedAt FinishedAt Features
2.2.0.2.0.6.0-101 0.12.0.2.0.6.1-101 margusja 2014-03-06 12:28:37 2014-03-06 12:29:09 UNKNOWN
Success!
Job Stats (time in seconds):
JobId Maps Reduces MaxMapTime MinMapTIme AvgMapTime MedianMapTime MaxReduceTime MinReduceTime AvgReduceTime MedianReducetime Alias Feature Outputs
job_1394027471317_0013 1 0 7 7 7 7 n/a n/a n/a n/a A,B MAP_ONLY hdfs://vm38:8020/tmp/temp1191617276/tmp1745379757,
Input(s):
Successfully read 46 records (2468 bytes) from: “hdfs://vm38:8020/user/margusja/passwd”
Output(s):
Successfully stored 46 records (528 bytes) in: “hdfs://vm38:8020/tmp/temp1191617276/tmp1745379757”
Counters:
Total records written : 46
Total bytes written : 528
Spillable Memory Manager spill count : 0
Total bags proactively spilled: 0
Total records proactively spilled: 0
Job DAG:
job_1394027471317_0013
2014-03-06 12:29:09,414 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher – Success!
2014-03-06 12:29:09,419 [main] INFO org.apache.hadoop.conf.Configuration.deprecation – fs.default.name is deprecated. Instead, use fs.defaultFS
2014-03-06 12:29:09,419 [main] INFO org.apache.pig.data.SchemaTupleBackend – Key [pig.schematuple] was not set… will not generate code.
2014-03-06 12:29:17,690 [main] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat – Total input paths to process : 1
2014-03-06 12:29:17,690 [main] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil – Total input paths to process : 1
(root)
(bin)
(daemon)
(adm)
(lp)
(sync)
(shutdown)
(halt)
(mail)
(uucp)
(operator)
(games)
(gopher)
(ftp)
(nobody)
(vcsa)
(saslauth)
(postfix)
(sshd)
(ntp)
(bacula)
(apache)
(mysql)
(web)
(zabbix)
(hduser)
(margusja)
(zend)
(dbus)
(rstudio-server)
(tcpdump)
(postgres)
(puppet)
(ambari-qa)
(hdfs)
(mapred)
(zookeeper)
(nagios)
(yarn)
(hive)
(hbase)
(oozie)
(hcat)
(rrdcached)
(sqoop)
(hue)
grunt>
New tool – Fluke 87V

Informatsiooni väärtus
Alljärgnev ei ole otseselt seotud ühegi IT-projektiga, samas puudutab paljusid suuremaid viimasel ajal ellu viidud IT-alaseid saavutusi, kus kogutakse isikuandmeid. Ma ei pea silmas ainult otseselt isikut otseselt tuvastavaid andmeid nagu nimi, aadress, ID-kood vaid ka anonüümseid andmeid – mingi kasutajanimi, ost, kuupäev, logid jne.
Otseste isikuandmetega on asi selge, nendele rakendub isikuandmete käitlemise seadus. Samas kõik andmed, mis siiski isikut puudutavad, ei kuulu sinna haldusalasse ja neid võib koguda ja töödelda.
Miks ma pean antud teemat eetiliseks? Kuna infotehnoloogia, matemaatika ja struktureerimata andmed annavad väga tugeva indikatsiooni hetkel veel tundmatu isiku käitumisharjumiste kohta väga tugeva mustri, siis on see muster väärtus. Kas meie, selle mustri tekitajad, ei peaks saama siinkohal rohkem kaasa rääkida? Võib ju oponeerida, et peida rohkem, krüpteeri rohkem, aga miks peaks olema see eesmärk omaette? Võime näiteks tuua Tallinna ühistranspordi projekti. Ega minul, kui kasutajal ei olegi valida – kas ma lihtsalt ei kasuta seda süsteemi (ei jaga andmeid) või olen sunnitud neid andmeid siiski jagama. Miks ma peaks oma käitumisharjumusi jagama? Võib jällegi vastu küsida, et avalik ruum ja alati võib keegi minu kodu ukse juures passida ja märkida ülesse kellaaja, millal ma lahkun. Samas on vahe, kui seda teeb, mingi elektrooniline süsteem minu teadmata – minu jaoks oleks see siis süstemaatiline andmete kogumine. Juhul, kui seda teeb mõni inimene, mis iganes tema põhjus on, siis mis seal ikka – vaba maailm. Minu jaoks on piir inimese ja masina vahel.
Veel näiteid. Kui maha on sadanud paks ja värske lumi, siis esimene kodanik, soovides punktist A punkti B minna, tekitab lumme mingid jäljed. Järgmine tegelane tõenäoliselt liigub punktist A punkti B eelkäija järgi. Mõne aja pärast on tekkinud korralik rada, mis omab juba järgmiste, kes soovivad liikuda punktist A punkti B, jaoks korraliku väärtust – nad saavad puhaste kingadega läbida antud teekonna.
Nüüd võib küsida, et kus see probleem ikkagi on. Niikaua ei olegi, kui seda ära ei kasutata. Näide – oleme nüüd kena raja sisse tallanud punktist A punkti B. Kui nüüd tee haldur, kes peaks seda teed lumest puhtana hoidma, avastab, et inimesed nagunii kõnnivad selle ala kenasti kõvaks, siis ei ole ju tarvis siit lükata enam. Teehooldusteks eraldatud ressursid jäävad aga teehooldajale, mitte ei jagata lumes sumpajate vahel ära.
Kui nüüd eetilisuse juurde tagasi pöörduda ja osapooli esile tuua, siis on lihtne eristada eraisikuid, kes tekitavad mustreid ja andmekogujaid, kes koguvad andmeid ja nendest mustreid genereerivad.
Kui nüüd väita, et inimesed on alati mustreid tekitanud, siis nüüd on see eetiline probleem seetõttu, et neid mustreid on väga lihtne nüüd, kus me jätame oma elektroonilise jälje, koguda ja analüüsida.
Ma ei ole enda jaoks antud teemat päris lõpuni mõelnud, sellest tulenevalt ei oska ma ka ühest lahendust, minu jaoks probleemina tunduva, teemale anda. Võib juhtuda, et ühel päeval oleme me kõik tuluteenijad, kui informatsioonitekitajad – meie käitumismustreid tegelikult ju vajatakse. Täna tundub ulmelisena. Toon näite. 1953 aastal ei olnud ilmselt mingi probleem, kui ajalehes avaldati informatsioon, et Ants Konn, Tiidu poeg on ostnud piima ja muna. Kui täna selline informatsioon avaldada, siis on olukord kohe teine. Sama kogus informatsiooni aastal 1953 ja 2014 aastal on erineva väärtusega.
Lõpetuseks tooksin veel selgelt välja, miks on tegu minu arust eetilise probleemiga. Tänaseks ei ole selgelt informatsiooni omanik määratletud, kui me peame silmas selliseid andmeid, mida me enese teadmata toodame. Samas kasutatakse neid tulu saamisel teadlikult ära. Osapooled on selgelt eristuvad – ühelpool meie, kes me toodame vajaliku informatsiooni, saamata sellest täna tulu ja teisel pool komplekt arvutusvõimsus, matemaatika ja asjalik ärimees, kes juba saab eelmainitud komplekti väljundust tulu teenida. Mitte, et see halb oleks, lihtsalt informatsiooni tekitajad on minuarust valesti koheldud.
Minu uus jootejaam – Saike 852D+
Nüüd saan ma ka puhuda 🙂

Hello Word in GraphLab
GraphLab is downloaded and compiled
cd graphlab/apps/ and make a new dir my_first_app/
cd my_first_app
create a new file my_first_app.cpp and put following code in it
#include
int main(int argc, char** argv) {
graphlab::mpi_tools::init(argc, argv);
graphlab::distributed_control dc;
dc.cout() << “Hello World!\n”;
graphlab::mpi_tools::finalize();
}
Now make another file called CMakeLists.txt with a content
project(My_Project)
add_graphlab_executable(my_first_app my_first_app.cpp)
Go some levels up to graphlab main dir and execute ./configure
If configure script ended without errors you have to go graphlab/release/apps/my_first_app/ and there execute make -j4 and after it you will get your executable called my_first_app.
Exec it ./my_first_app and you probably get
margusja@IRack:~/graphlab/release/apps/my_first_app$ ./my_first_app
INFO: mpi_tools.hpp(init:63): MPI Support was not compiled.
INFO: dc.cpp(init:573): Cluster of 1 instances created.
Hello World!
margusja@IRack:~/graphlab/release/apps/my_first_app$
Some simple use cases in Neo4j
First we import some simple data, containing nodes and relations into neo4j
neo4j-sh (?)$ CREATE (Client1:client {name:’Ants Konn’, age:34, sex:’M’})
> CREATE (Client2:client {name:’Ivan Orav’, age:66, sex:’M’})
> CREATE (Client3:client {name:’Kadri Kala’, age:24, sex:’F’})
> CREATE (Client4:client {name:’Jaanika Tamm’, age:55, sex:’F’})
>
> CREATE (Basket1:pasket {name:’Basket1′})
> CREATE (Basket2:pasket {name:’Basket2′})
> CREATE (Basket3:pasket {name:’Basket3′})
> CREATE (Basket4:pasket {name:’Basket4′})
> CREATE (Basket5:pasket {name:’Basket5′})
>
> CREATE (Item1:item {name:’Item1′, price:”34″, amount:2})
> CREATE (Item2:item {name:’Item2′, price:”3″, amount:1})
> CREATE (Item3:item {name:’Item3′, price:”4″, amount:3})
> CREATE (Item4:item {name:’Item4′, price:”64″, amount:5})
> CREATE (Item5:item {name:’Item5′, price:”88″, amount:2})
> CREATE (Item6:item {name:’Item6′, price:”32″, amount:1})
> CREATE (Item7:item {name:’Item7′, price:”74″, amount:20})
> CREATE (Item8:item {name:’Item8′, price:”1″, amount:2})
>
> CREATE (Client1)-[:OWN]->(Basket1)
> CREATE (Client1)-[:OWN]->(Basket2)
> CREATE (Client2)-[:OWN]->(Basket3)
> CREATE (Client3)-[:OWN]->(Basket4)
> CREATE (Client4)-[:OWN]->(Basket5)
>
> CREATE (Item1)-[:IN]->(Basket1)
> CREATE (Item2)-[:IN]->(Basket1)
> CREATE (Item3)-[:IN]->(Basket2)
> CREATE (Item4)-[:IN]->(Basket3)
> CREATE (Item5)-[:IN]->(Basket4)
> CREATE (Item6)-[:IN]->(Basket5)
> CREATE (Item7)-[:IN]->(Basket1)
> CREATE (Item7)-[:IN]->(Basket2)
> CREATE (Item7)-[:IN]->(Basket3)
> CREATE (Item7)-[:IN]->(Basket4)
> CREATE (Item7)-[:IN]->(Basket5)
> CREATE (Item8)-[:IN]->(Basket2)
> CREATE (Item8)-[:IN]->(Basket3)
> ;
Now you can visualize your data in different environments.
The easiest way is to use neo4j databrowser
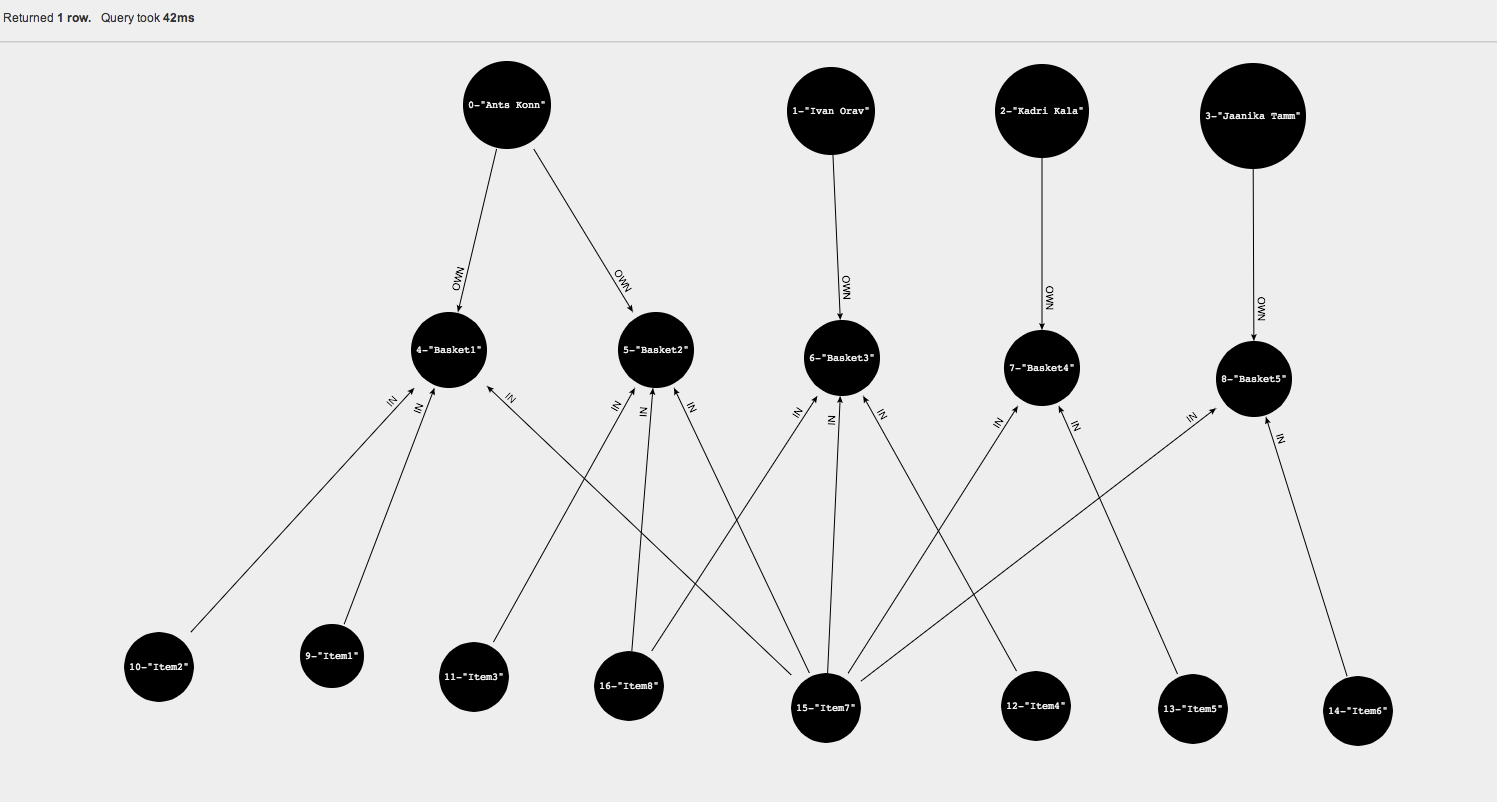
or you can choose some 3th part application to play with your data. In example I use neoclipse
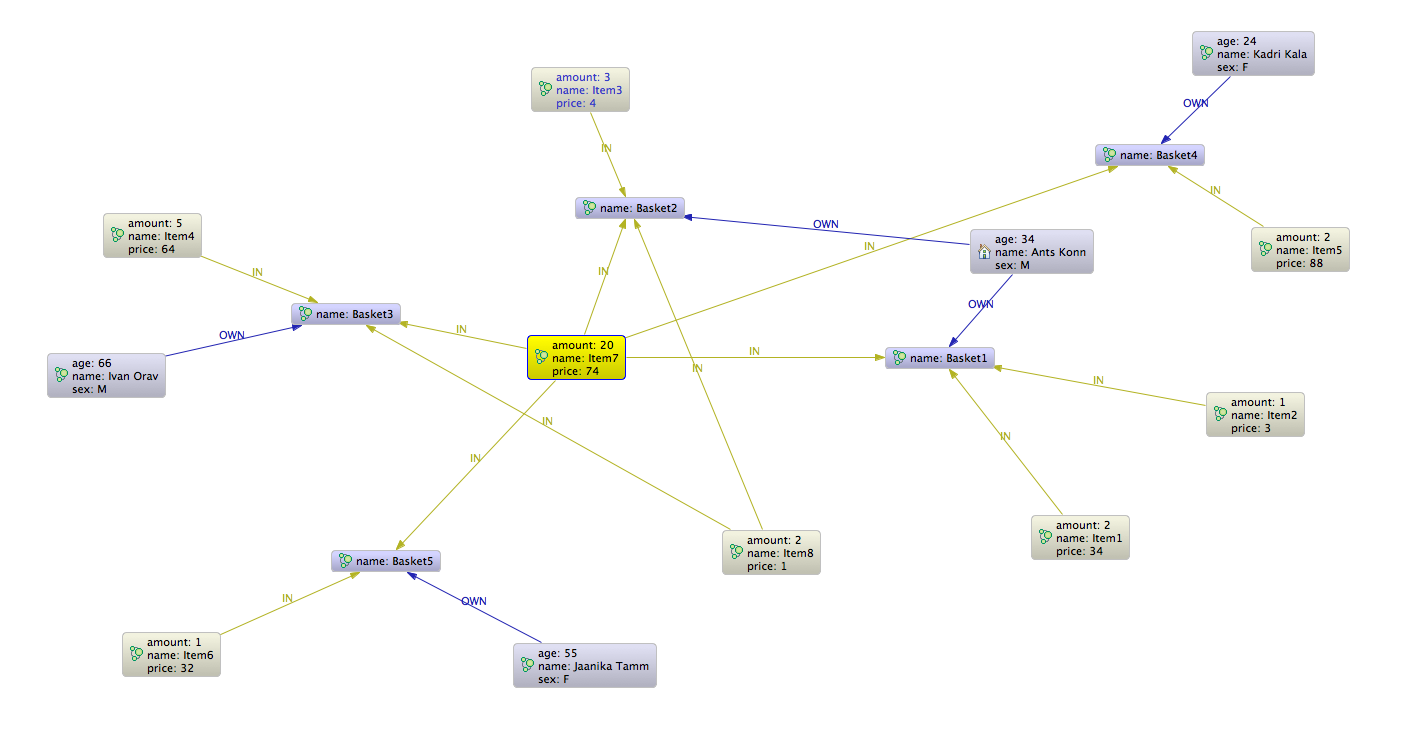
Now we have nodes and relations in db and we can visualize them.
Neo4j is more than tool for data visualization. It is database so we can make queries.
Why do we need queries if we have so nice graphical presentation. In case if we have huge amount of data the graphical presentation may be a little bit difficult to follow and patterns we are looking for my be not so easily found.
Lets see what interesting queries we can produce based on our existing data.
Lets take Item2 (NodeID: 10)
The easiest way to make queries for me is to use neo4j-shell.
Lets pretend we need to know who are buyers of current Item
neo4j-sh (Item2,10)$ MATCH (i {name:’Item2′})-[:IN]-b-[:OWN]-c RETURN i, b, c;
+—————————————————————————————————————-+
| i | b | c |
+—————————————————————————————————————-+
| Node[10]{name:”Item2″,price:”3″,amount:1} | Node[4]{name:”Basket1″} | Node[0]{name:”Ants Konn”,age:34,sex:”M”} |
+—————————————————————————————————————-+
1 row
We can see that Item2 is not very popular product. What about Item7?
neo4j-sh (?)$ MATCH (i {name:’Item7′})-[:IN]-b-[:OWN]-c RETURN i, b, c;
+———————————————————————————————————————+
| i | b | c |
+———————————————————————————————————————+
| Node[15]{name:”Item7″,price:”74″,amount:20} | Node[4]{name:”Basket1″} | Node[0]{name:”Ants Konn”,age:34,sex:”M”} |
| Node[15]{name:”Item7″,price:”74″,amount:20} | Node[5]{name:”Basket2″} | Node[0]{name:”Ants Konn”,age:34,sex:”M”} |
| Node[15]{name:”Item7″,price:”74″,amount:20} | Node[6]{name:”Basket3″} | Node[1]{name:”Ivan Orav”,age:66,sex:”M”} |
| Node[15]{name:”Item7″,price:”74″,amount:20} | Node[7]{name:”Basket4″} | Node[2]{name:”Kadri Kala”,age:24,sex:”F”} |
| Node[15]{name:”Item7″,price:”74″,amount:20} | Node[8]{name:”Basket5″} | Node[3]{name:”Jaanika Tamm”,age:55,sex:”F”} |
+———————————————————————————————————————+
5 rows
24 ms
We can see that Item7 is much popular product comparing with Item2.
So who are buyers bought Item7
neo4j-sh (?)$ MATCH (i {name:’Item7′})-[:IN]-b-[:OWN]-c RETURN DISTINCT c;
+———————————————+
| c |
+———————————————+
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} |
| Node[1]{name:”Ivan Orav”,age:66,sex:”M”} |
| Node[2]{name:”Kadri Kala”,age:24,sex:”F”} |
| Node[3]{name:”Jaanika Tamm”,age:55,sex:”F”} |
+———————————————+
4 rows
37 ms
So very cool queries 🙂
Lets make thinks more interesting and create new relation between customers Ants Konn and Jaanika Tamm and pretend they are couple. Ignore lastnames 🙂
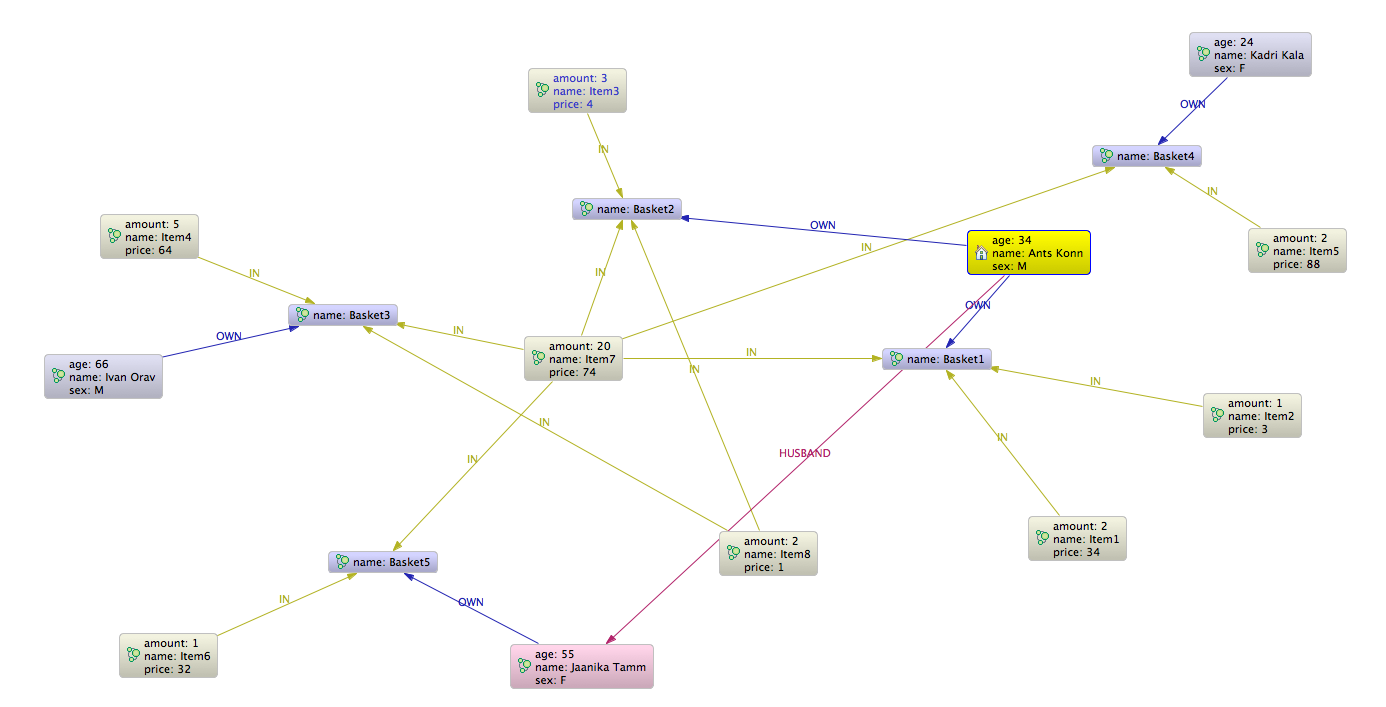
Now we can ask a question in example are there items bought by related persons?
neo4j-sh (?)$ MATCH i-[:IN]-b-[:OWN]-c-[]-c2-[OWN]-b2-[IN]-i RETURN DISTINCT c, i;
+——————————————————————————————-+
| c | i |
+——————————————————————————————-+
| Node[3]{name:”Jaanika Tamm”,age:55,sex:”F”} | Node[15]{name:”Item7″,price:”74″,amount:20} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[15]{name:”Item7″,price:”74″,amount:20} |
+——————————————————————————————-+
2 rows
29 ms
We found that Item7 is the only Item bought by that couple.
Lets make thinks more complicated and add one more relation between Ants Konn and Ivan Orav as father and son. Don’t lool surnames again 🙂 and put Item1 into basket3 as well.

Lets query now Items bought by related customers
neo4j-sh (?)$ MATCH i-[:IN]-b-[:OWN]-c-[]-c2-[OWN]-b2-[IN]-i RETURN DISTINCT c.name, i.name ORDER BY i.name;
+————————–+
| c.name | i.name |
+————————–+
| “Ivan Orav” | “Item1” |
| “Ants Konn” | “Item1” |
| “Jaanika Tamm” | “Item7” |
| “Ivan Orav” | “Item7” |
| “Ants Konn” | “Item7” |
| “Ivan Orav” | “Item8” |
| “Ants Konn” | “Item8” |
+————————–+
7 rows
100 ms
neo4j-sh (?)$
One example about query “my friends friends” that gives as all nodes after node we are connected
neo4j-sh (Ants Konn,0)$ start n=node:node_auto_index(name=’Ants Konn’) MATCH n–()–t RETURN n, t;
+—————————————————————————————-+
| n | t |
+—————————————————————————————-+
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[16]{name:”Item8″,price:”1″,amount:2} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[15]{name:”Item7″,price:”74″,amount:20} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[11]{name:”Item3″,price:”4″,amount:3} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[15]{name:”Item7″,price:”74″,amount:20} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[10]{name:”Item2″,price:”3″,amount:1} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[9]{name:”Item1″,price:”34″,amount:2} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[8]{name:”Basket5″} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[6]{name:”Basket3″} |
+—————————————————————————————-+
8 rows
17 ms
and here we can add information about node we jumped over
neo4j-sh (Ants Konn,0)$ start n=node:node_auto_index(name=’Ants Konn’) MATCH n–(i)–t RETURN n, i, t;
+————————————————————————————————————————————–+
| n | i | t |
+————————————————————————————————————————————–+
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[5]{name:”Basket2″} | Node[16]{name:”Item8″,price:”1″,amount:2} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[5]{name:”Basket2″} | Node[15]{name:”Item7″,price:”74″,amount:20} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[5]{name:”Basket2″} | Node[11]{name:”Item3″,price:”4″,amount:3} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[4]{name:”Basket1″} | Node[15]{name:”Item7″,price:”74″,amount:20} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[4]{name:”Basket1″} | Node[10]{name:”Item2″,price:”3″,amount:1} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[4]{name:”Basket1″} | Node[9]{name:”Item1″,price:”34″,amount:2} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[3]{name:”Jaanika Tamm”,age:55,sex:”F”} | Node[8]{name:”Basket5″} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | Node[1]{name:”Ivan Orav”,age:66,sex:”M”} | Node[6]{name:”Basket3″} |
+————————————————————————————————————————————–+
8 rows
16 ms
neo4j-sh (Ants Konn,0)$
Another query to get relations. So lets get all relations related with Ants Konn
neo4j-sh (Ants Konn,0)$ start n=node:node_auto_index(name=’Ants Konn’) MATCH n-[r]-t RETURN n, r;
+———————————————————–+
| n | r |
+———————————————————–+
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | :OWN[1]{} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | :OWN[0]{} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | :HUSBAND[21]{} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | :SON[22]{} |
+———————————————————–+
4 rows
10 ms
neo4j-sh (Ants Konn,0)$
You can specify relation direction using “>” and “<“. Query relations that goes out from Ants Konn
neo4j-sh (Ants Konn,0)$ sto_index(name=’Ants Konn’) MATCH n-[r]->t RETURN n, r;
+———————————————————–+
| n | r |
+———————————————————–+
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | :OWN[1]{} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | :OWN[0]{} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | :HUSBAND[21]{} |
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | :SON[22]{} |
+———————————————————–+
4 rows
6 ms
And query for incoming relations for Ants Konn
neo4j-sh (Ants Konn,0)$ start n=node:node_auto_index(name=’Ants Konn’) MATCH n<-[r]-t RETURN n, r;
+——-+
| n | r |
+——-+
+——-+
0 row
5 ms
So at the moment there are’t any incoming relation. Lets create one and lets query again.
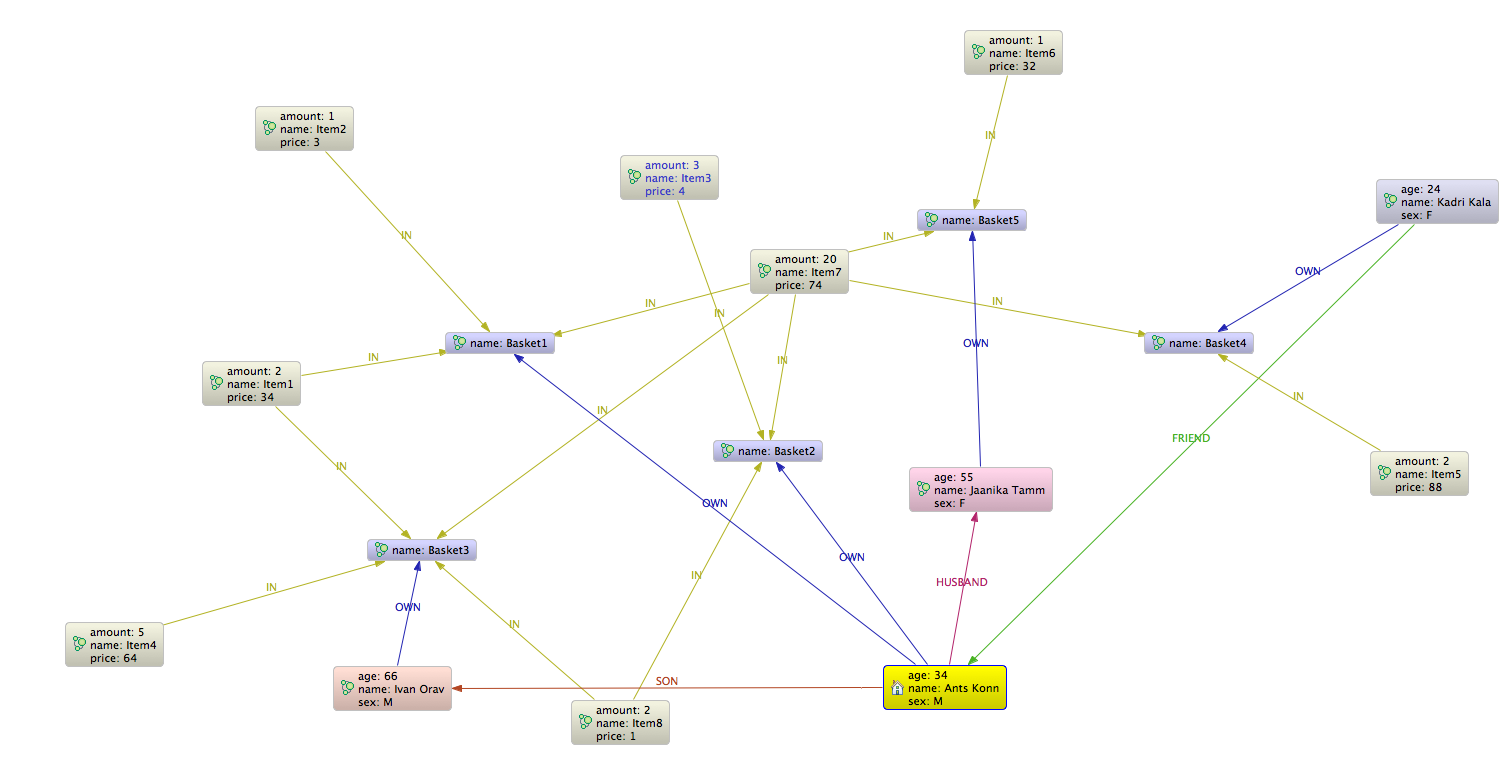
As you see there is now one incoming relation for Ants Konn. Lets query
neo4j-sh (Ants Konn,0)$ start n=node:node_auto_index(name=’Ants Konn’) MATCH n<-[r]-t RETURN n, r;
+———————————————————-+
| n | r |
+———————————————————-+
| Node[0]{name:”Ants Konn”,age:34,sex:”M”} | :FRIEND[24]{} |
+———————————————————-+
1 row
5 ms
neo4j-sh (Ants Konn,0)$
So Ants Konn is not so lonely any more he has one friend 🙂
One more nice picture about our relations using neo4j web tools
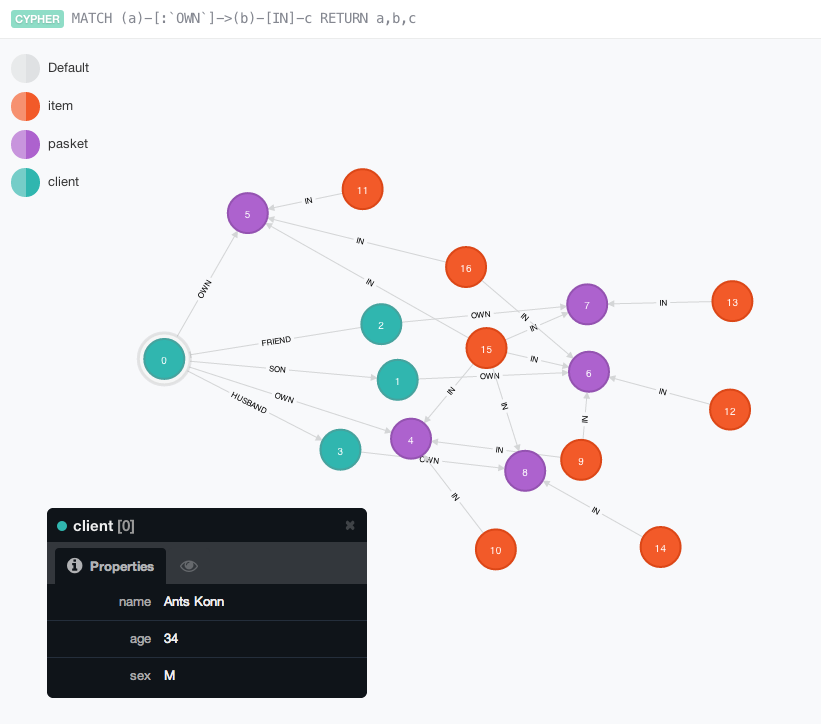
Sow that was a light introduction about some possibilities of neo4j.
Home made outside temperature measure based on ATmega 328p and DS18S20
This is the first prototype of outside package 🙂

I don’t know what neighbours are thinking

My display solution supports 30 external node in one network. One of them is outside at the moment and on is in room. So now I can measure inside temperature and outside temperature.

yet another solution for atmel mkii to feed target
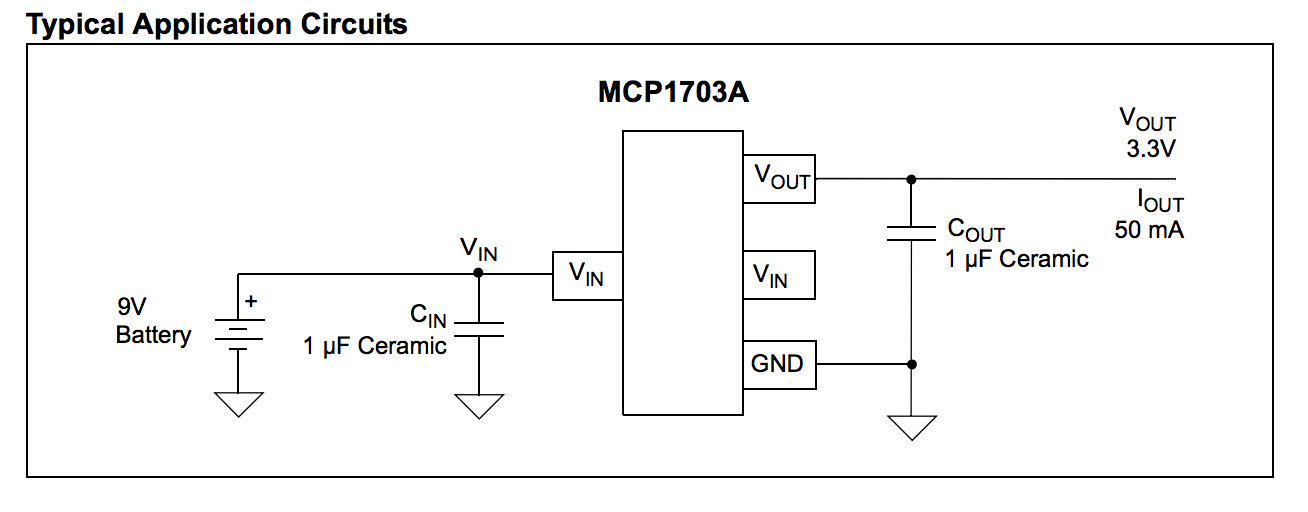
Basically get positive and ground from usb port. Solder MCP1703 voltage stabiliser into right switch pin. Between voltage stabiliser pins solder in and out capacitors. MCP1703 out goes to ISP pin2.
In my projects most needed voltage is 3.3V so now I have 5V and 3.3V for my targets. No extra wire anymore 🙂
