After many-many hours solution was not in fluend side but in fluent-bit side
If you're inventing and pioneering, you have to be willing to be misunderstood for long periods of time
After many-many hours solution was not in fluend side but in fluent-bit side
One good example how community works!
I had a strange error:
Hi
It looks similar to problems I’ve seen many years ago around mapreduce.task.io.sort.mb. You can try reducing that value. It also may be related to a bug in your Hadoop version.
What a great power of community!
Br, Margus
For me personally, very difficult to thing recursively. So I’ll put some examples for me down here.
First – higher-order function is a function takes function as an argument or returns result as a function.
Lets create a high-order function in scala:
scala> def highF(f: Int => Int, a: Int) = f(a)
highF: (f: Int => Int, a: Int)Int
As we can see it does not do anything usable. Just takes f(Int) and returns Int.
Lets create two first class functions:
scala> def first1(a: Int) : Int = { a.+(a) }
first1: (a: Int)Int
scala> def first2(a: Int) : Int = { a.-(a) }
first2: (a: Int)Int
This functions are already easier to explain. First one takes Int and just does Int + Int. In example a => a + a.
Second one just subtracts a => a – a.
Now comes interesting part – how we use higher-order function.
scala> highF(first1, 2)
res23: Int = 4
scala> highF(first2, 2)
res24: Int = 0
And there is more. We can use anonymous function as an argument:
scala> highF(a => a.+(10), 2)
res25: Int = 12
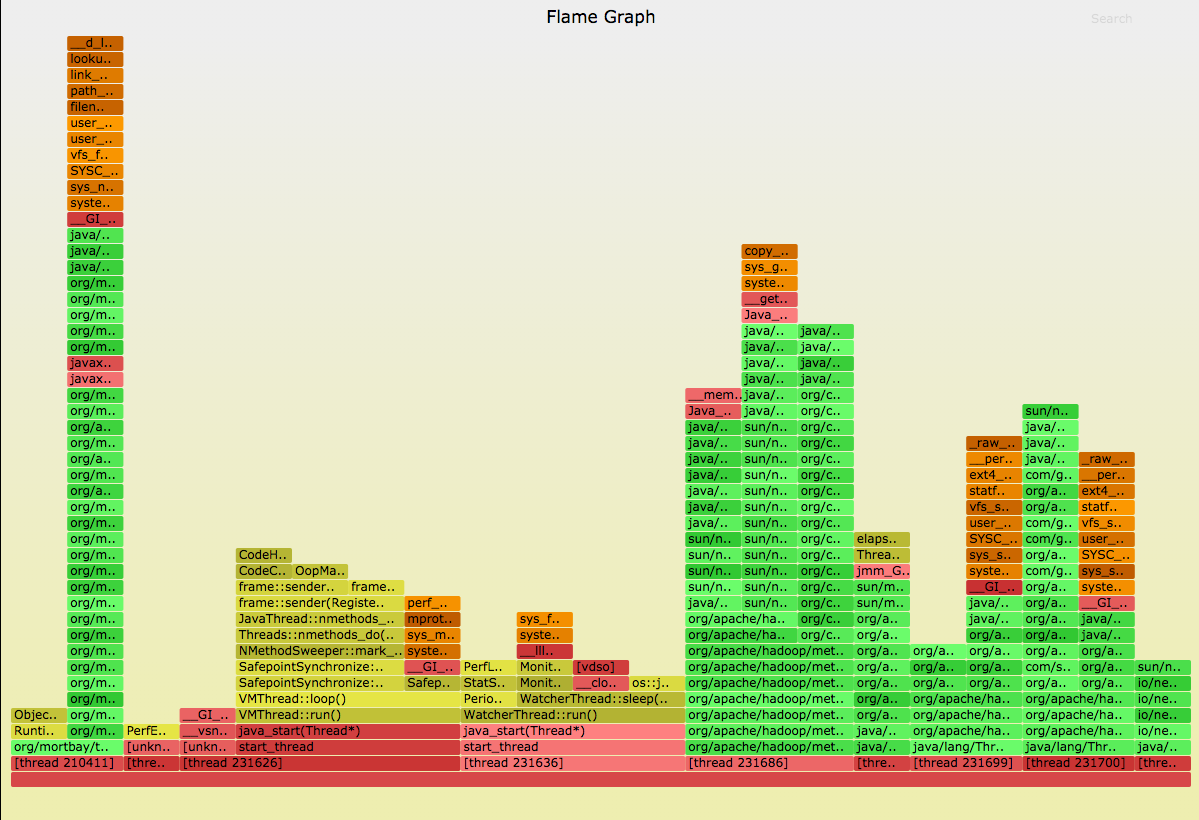
Thanks to Erkki I found project FlameGraph.
Just to remember to myself one session:
su – hdfs
28 git clone https://github.com/jvm-profiling-tools/async-profiler
29 git clone https://github.com/BrendanGregg/FlameGraph
30 cd async-profiler
33 JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk/ make
34 cd ../
35 mkdir async-profiler-output
36 cd async-profiler-output
37 jps (get hdfs datanode process)
38 ../async-profiler/profiler.sh -t -d 10 -o collapsed -f /tmp/collapsed.txt 231591
41 ../FlameGraph/flamegraph.pl –colors=java /tmp/collapsed.txt > flamegraph_yarn-bigdata40_hdfs_namenode.svg
Got nice flame
:sp filename for a horizontal split:vsp filename or :vs filename for a vertical splitmove between splits: CNTR+w and arrow
I got following errors when tried to enable Hive LLAP via ambari:
2017-10-30 14:37:31,925 - LLAP app 'llap0' deployment unsuccessful.
Traceback (most recent call last):
File "/var/lib/ambari-agent/cache/common-services/HIVE/0.12.0.2.0/package/scripts/hive_server_interactive.py", line 616, in <module>
HiveServerInteractive().execute()
File "/usr/lib/python2.6/site-packages/resource_management/libraries/script/script.py", line 329, in execute
method(env)
File "/var/lib/ambari-agent/cache/common-services/HIVE/0.12.0.2.0/package/scripts/hive_server_interactive.py", line 123, in start
raise Fail("Skipping START of Hive Server Interactive since LLAP app couldn't be STARTED.")
resource_management.core.exceptions.Fail: Skipping START of Hive Server Interactive since LLAP app couldn't be STARTED.
WARN cli.LlapStatusServiceDriver: Watch timeout 200s exhausted before desired state RUNNING is attained. INFO cli.LlapStatusServiceDriver: LLAP status finished 2017-10-30 14:37:31,924 - LLAP app 'llap0' current state is LAUNCHING. 2017-10-30 14:37:31,925 - LLAP app 'llap0' current state is LAUNCHING. 2017-10-30 14:37:31,925 - LLAP app 'llap0' deployment unsuccessful. Command failed after 1 tries In my case the solution was: num_retries_for_checking_llap_status from 10 to 30
import scalaj.http._
val hkey = Base64.getEncoder.encodeToString(key.getBytes(StandardCharsets.UTF_8))
val value = Base64.getEncoder.encodeToString(rawValue.getBytes(StandardCharsets.UTF_8))
val data = "{\"Row\":[{\"key\":\" " + hkey + " \", \"Cell\":[{\"column\":\"Y2Y6Y29sMw==\", \"$\":\" " + value + " \"}]}]}"
Http("http://bigdata33.webmedia.int:8080/deepscan_data_1_1/" + key + "/cf:content").postData(data).header("content-type", "application/json").asString
In case you need PUT instead of POST:
Http("http://bigdata41.webmedia.int:9090/nifi-api/processors/10001184-103f-112d-799b-662b43e70ced").postData(data).header("content-type", "application/json").method("put").asString
$ git config credential.helper store
$ git push https://github.com/repo.git
Username for 'https://github.com': <USERNAME>
Password for 'https://USERNAME@github.com': <PASSWORD>Tried to install Nifi using Ambari.
Got error message:
File “/var/lib/ambari-agent/cache/common-services/NIFI/1.0.0/package/scripts/params.py”, line 47, in <module> stack_version_buildnum = get_component_version_with_stack_selector(“/usr/bin/hdf-select”, “nifi”) NameError: name ‘get_component_version_with_stack_selector’ is not defined
All hosts in Ambari Hosts menu showed Stack: HDP, Name: HDP-2.6.1.0, Status: Current.
Could not resolve it via Ambari. Even hdf-select in node where to I tried to install Nifi I cot executing:
hdf-select
…
nifi – 3.0.0.0-453
…
Solution for me was to change some lines in /var/lib/ambari-agent/cache/common-services/NIFI/1.0.0/package/scripts/params.py. Commented out red line and added green:
if stack_name == “HDP”:
# Override HDP stack root
stack_root = “/usr/hdf”
# Override HDP stack version
#stack_version_buildnum = get_component_version_with_stack_selector(“/usr/bin/hdf-select”, “nifi”)
stack_version_buildnum = get_component_version(stack_name, “nifi”)
elif not stack_version_buildnum and stack_name:
stack_version_buildnum = get_component_version(stack_name, “nifi”)
service ntpd stop
ntpdate 0.rhel.pool.ntp.org
service ntpd start