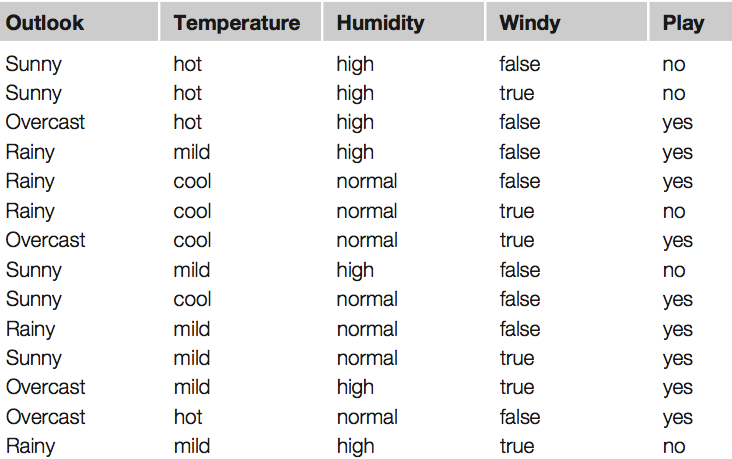
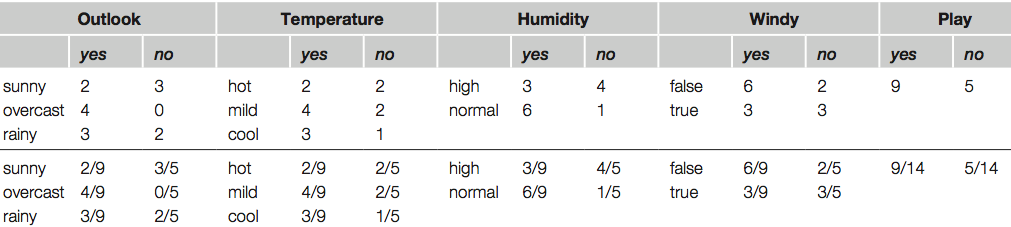
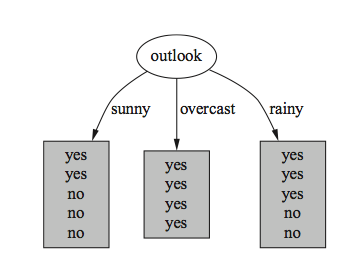
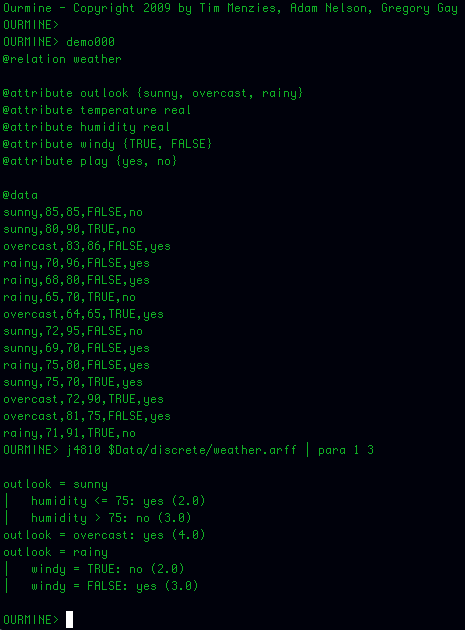
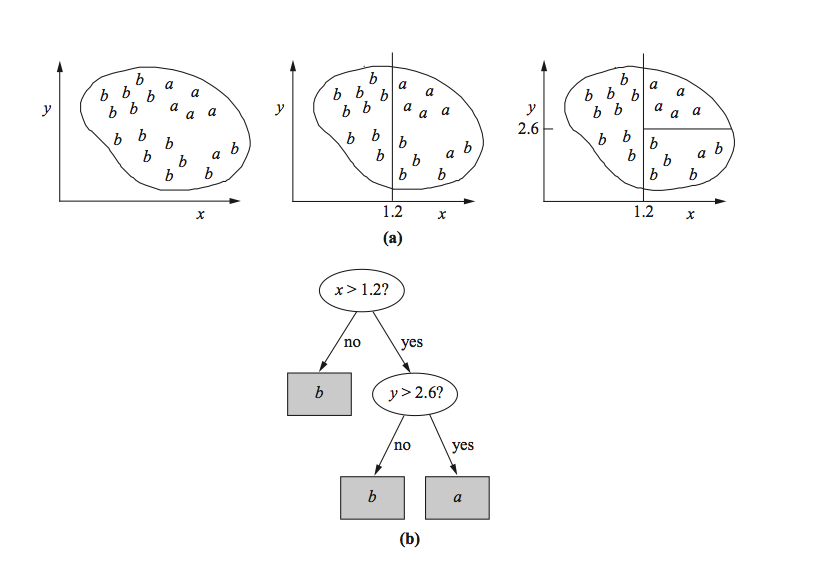
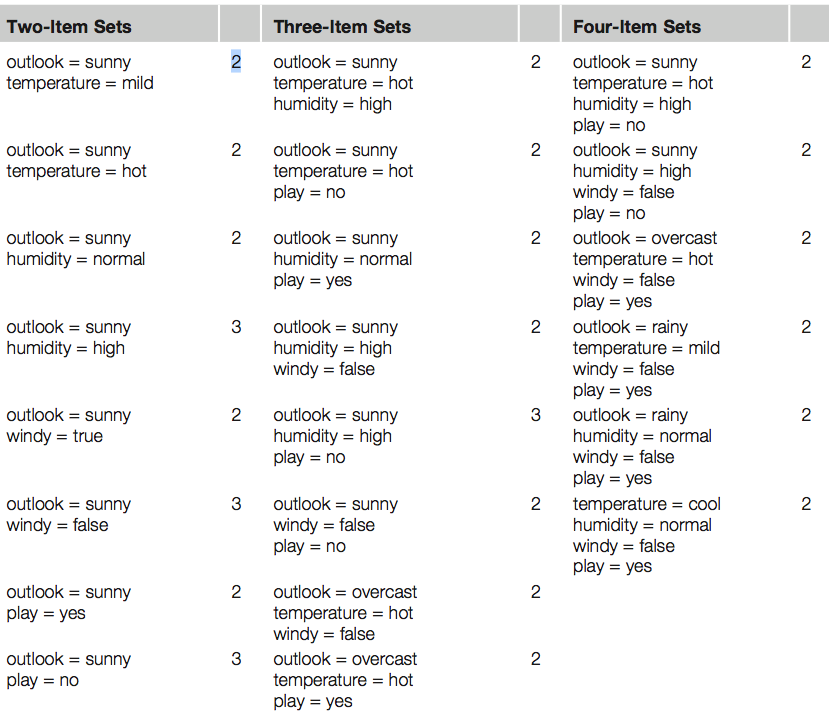
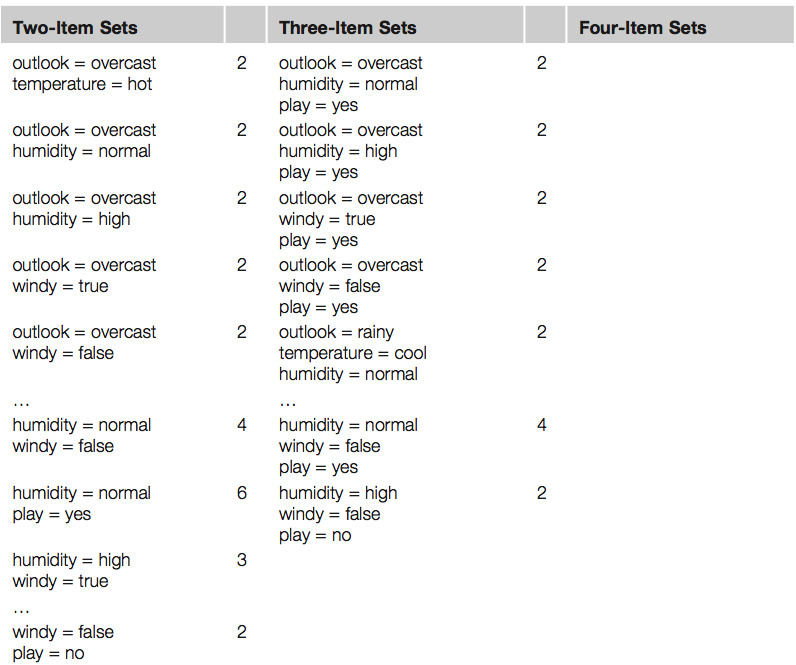
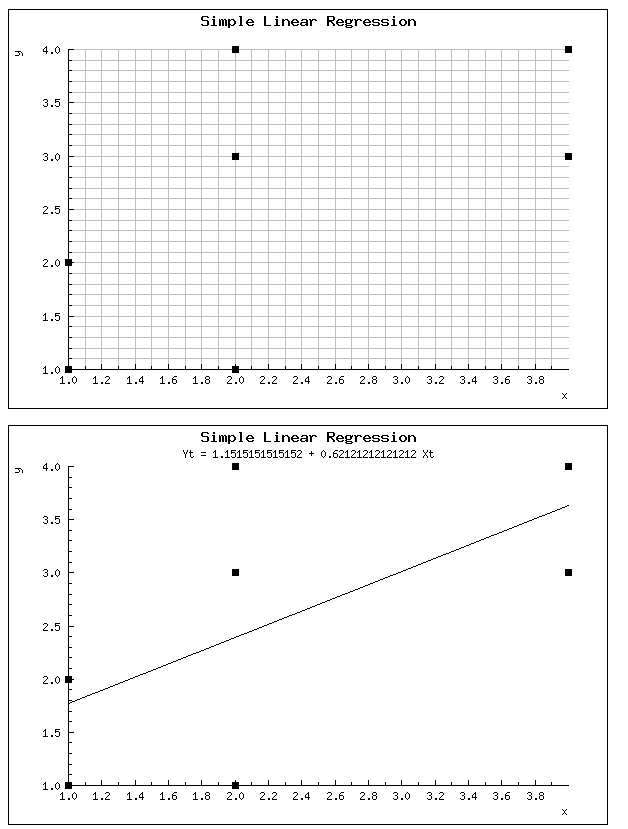
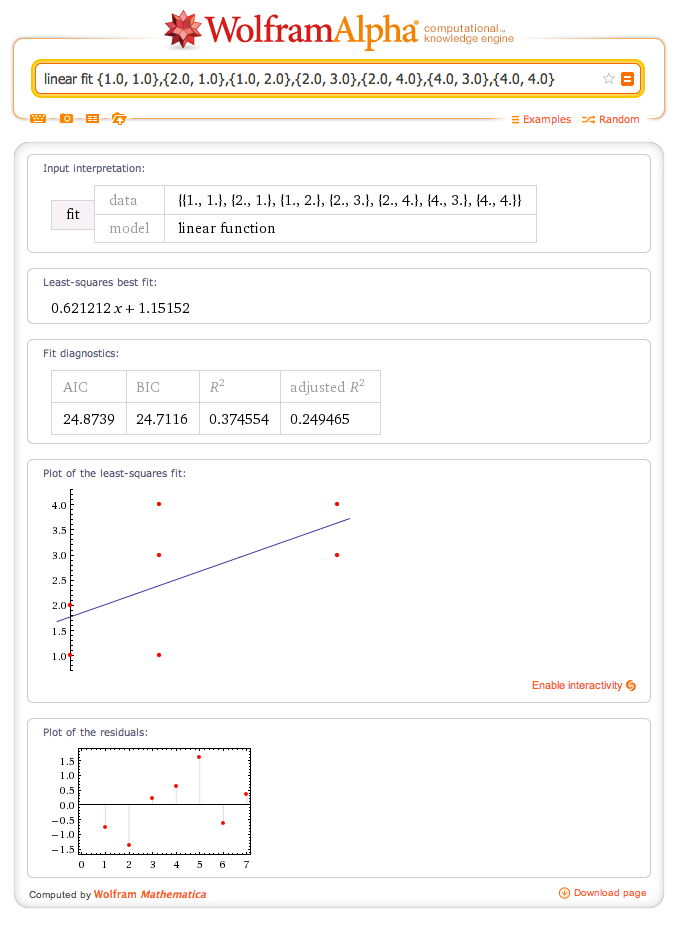
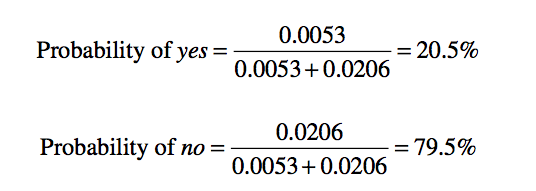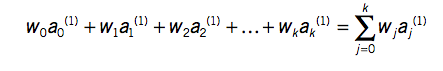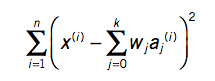* Eelduseks on, et sõltuva ja sõltumatu (sõltumatute) muutuja (muutujate) vahel on lineaarne seos.
* Sõltuv muutuja – muutuja mida üritatakse ennustada ühe või enama sõltumatu muutuja kaudu
* Mida vähem sõltumatud muutujad omavahel korrelatsioonis on, seda parem. Võimalus eelnevalt tugevas korrelatsioonis olevad sõltumatud muutujad eemaldada.
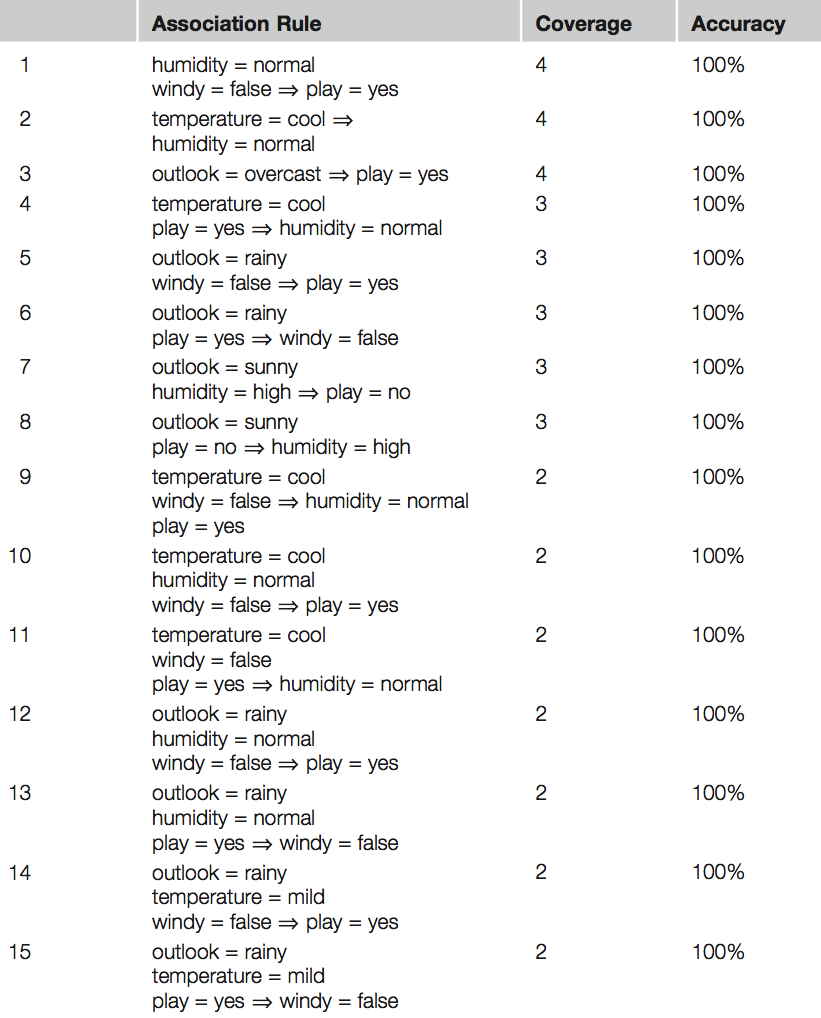
* Mudeli kvaliteeti saab mõõta “Root Mean Squared Error” valemiga, mille tulemus on 0 ja 1 vahel. Mida lähemal on see tulemus 0-le seda parem. Kirjeldab punktide kauguste summa ruutu lineaarsest joonest
* Standard error – Standardviga (standard error, SE) ehk valimi keskväärtuse standardhälve on SD/pn. Formaalselt on tegu standardhälbega sellises uues üldkogumis, mis tekib, kui tegelikust üldkogumist võetakse uuritava valimiga võrdse suurusega valimeid ja arvutatakse uute valimite keskväärtused. Standardviga on siis selliste hüpoteetiliste valimite keskmiste standardhälve. Iseloomustab meie teadmiste täpsust uuritava üldkogumi keskmisest, mida täpsem on meie teadmine, seda väiksem on SE. SE sõltub seega a) üldkogumi dispersioonist; b) valimi suurusest. Mida suurem on valim, seda väiksem on SE. Valimi suurenedes läheneb SE nullile. See on siis oluline erinevus SD-st. Mida lähem 0-le, seda parem
* t-Stats – Mida kaugemal nullist, seda parem
* p-value – Mida lähemal nullile, seda parem.
* Student’s t-test is a method in statistics to determine the probability (p) that two populations are the same in respect to the variable that you are testing.
* Tolerance – the tolerance measures the influence of one independent variable on all other independent variables; the tolerance is calculated with an initial linear regression analysis. Tolerance is defined as T = 1 – R² for these first step regression analysis. With T < 0.1 there might be multicollinearity in the data and with T < 0.01 there certainly is
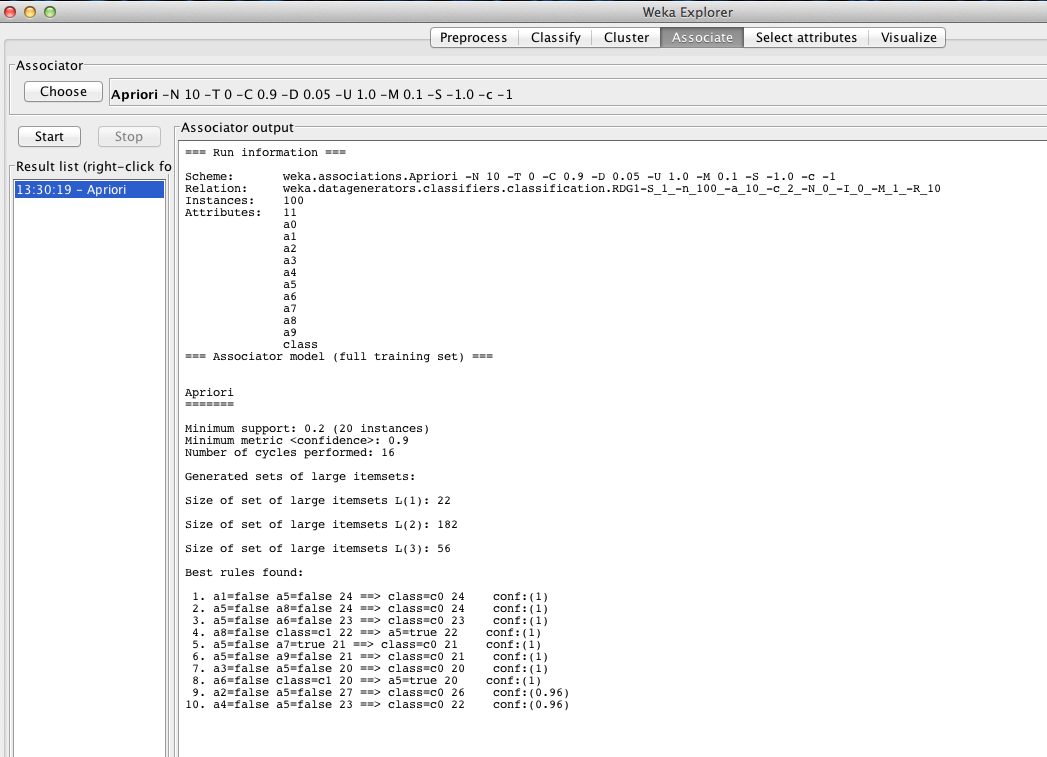
* p-value The p value is NOT a probability but a likelihood. It tells you the likelihood that the coefficient of a variable in regression is non zero.
The p-value is: The probability of observing the calculated value of the test statistic if the null hypothesis is true
p-values smaller than our chosen significance level (usually 0.05) indicate variables that should be in our final model.
P-values larger than our significance level may be left out of the model.
Nullhüpotees ( H0 või H0 ) – konservatiivne väide, mis eeldab tavaliselt, et muutusi ei ole, erinevus puudub jms.
Alati määratakse kindlaks ülempiir tõenäosusele teha esimest liiki viga. Taolist
ülempiiri nimetatakse olulisusenivooks ja tähistatakse � (alfa, significance level).
Vähimat olulisusenivood, mille korral me saame alternatiivse hüpoteesi vastu võtta,
nimetatakse olulisustõenäosuseks ja tähistatakse p (significance probability, pvalue). Kui olulisustõenäosus on väiksem kui meie poolt valitud olulisuse nivoo,
võime H1 vastu võtta. Teaduskirjanduses on saanud tavaks valida �=0.05 või 0.01.