27.07.2014 tandem






Klassikokkutulek 2014














Jaanika klõpsud



Nädalavahetus langevarjunduses












Puhkus algas



Apache-Spark map-reduce quick overview
I have file containing lines with text. I’d like to count all chars in the text. In case we have small file this is not the problem but what if we have huge text file. In example 1000TB distributed over Hadoop-HDFS.
Apache-Spark is one alternative for that job.
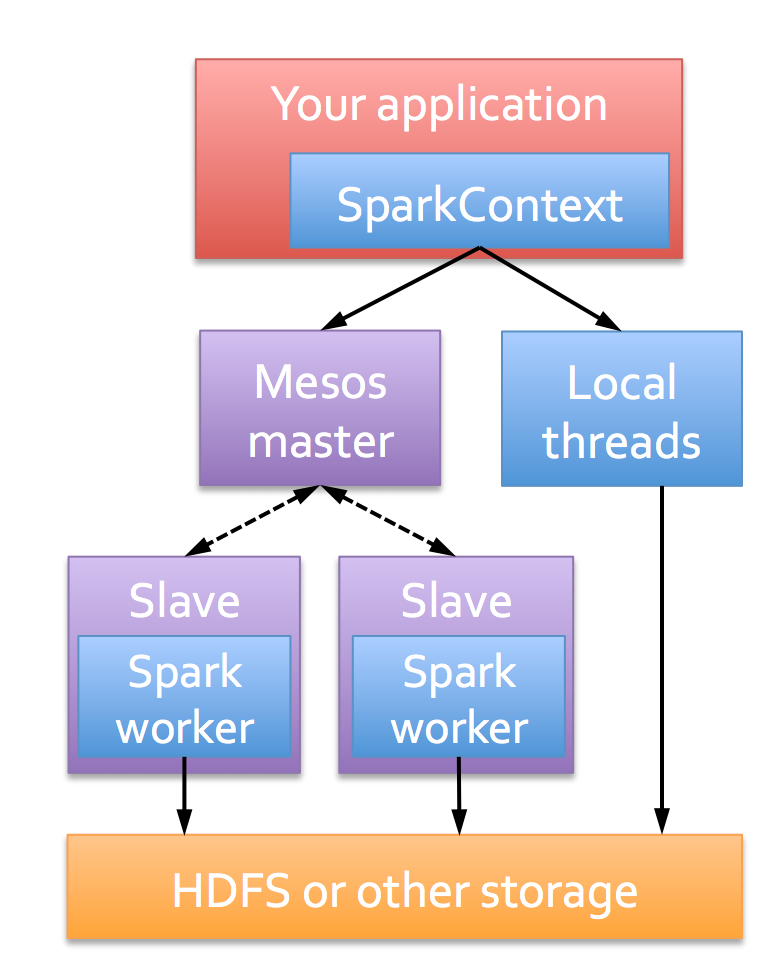
Big picture
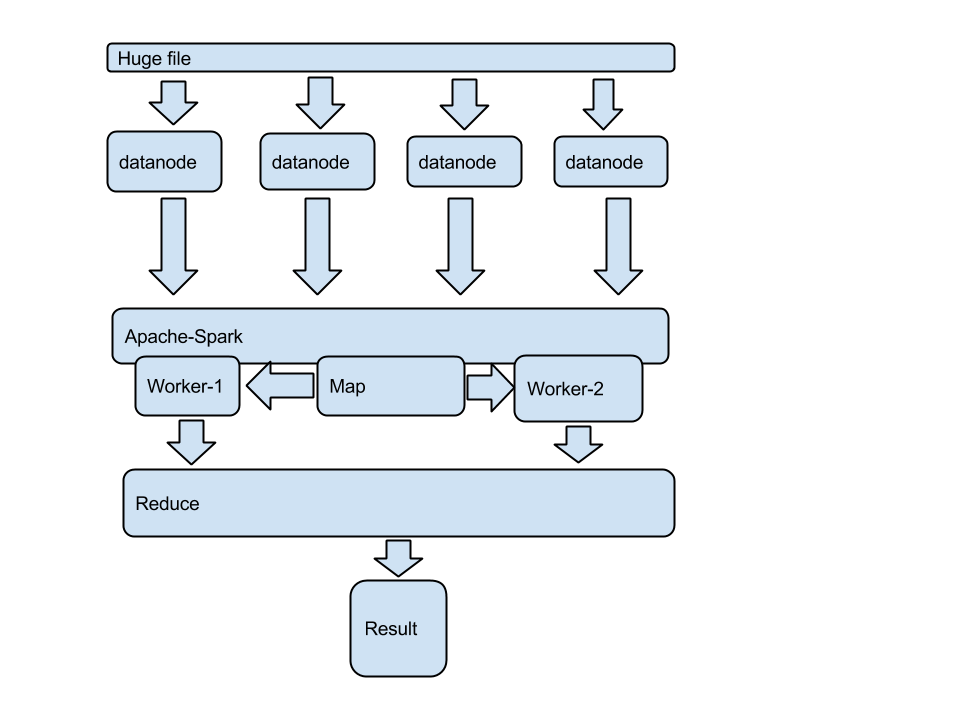
Now let’s dig into details
Apache Spark is a fast and general-purpose cluster computing system.
It provides high-level APIs in Java, Scala and Python,
and an optimized engine that supports general execution graphs.
It also supports a rich set of higher-level tools including Shark (Hive on Spark),
Spark SQL for structured data,
MLlib for machine learning,
GraphX for graph processing, and Spark Streaming.
This is java (spark) code:
String master = "local[3]";
String appName = "SparkReduceDemo";
SparkConf conf = new SparkConf().setAppName(appName).setMaster(master);
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD file = sc.textFile(“data.txt”); // this is our text file
// this is map function – splits tasks between workers
JavaRDD lineLengths = file.map(new Function<String, Integer>() {
public Integer call(String s) {
System.out.println(“line: “+s + ” “+ s.length());
return s.length();
}
});
// this is reduce function – collects results from workers for driver programm
int totalLength = lineLengths.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) {
System.out.println(“a: “+ a);
System.out.println(“b: “+ b);
return a + b;
}
});
System.out.println(“Lenght: “+ totalLength);
compile and run. Let’s analyse result:
14/06/19 10:34:42 INFO SecurityManager: Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
14/06/19 10:34:42 INFO SecurityManager: Changing view acls to: margusja
14/06/19 10:34:42 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(margusja)
14/06/19 10:34:42 INFO Slf4jLogger: Slf4jLogger started
14/06/19 10:34:42 INFO Remoting: Starting remoting
14/06/19 10:34:43 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://spark@10.10.5.12:52116]
14/06/19 10:34:43 INFO Remoting: Remoting now listens on addresses: [akka.tcp://spark@10.10.5.12:52116]
14/06/19 10:34:43 INFO SparkEnv: Registering MapOutputTracker
14/06/19 10:34:43 INFO SparkEnv: Registering BlockManagerMaster
14/06/19 10:34:43 INFO DiskBlockManager: Created local directory at /var/folders/vm/5pggdh2x3_s_l6z55brtql3h0000gn/T/spark-local-20140619103443-bc5e
14/06/19 10:34:43 INFO MemoryStore: MemoryStore started with capacity 74.4 MB.
14/06/19 10:34:43 INFO ConnectionManager: Bound socket to port 52117 with id = ConnectionManagerId(10.10.5.12,52117)
14/06/19 10:34:43 INFO BlockManagerMaster: Trying to register BlockManager
14/06/19 10:34:43 INFO BlockManagerInfo: Registering block manager 10.10.5.12:52117 with 74.4 MB RAM
14/06/19 10:34:43 INFO BlockManagerMaster: Registered BlockManager
14/06/19 10:34:43 INFO HttpServer: Starting HTTP Server
14/06/19 10:34:43 INFO HttpBroadcast: Broadcast server started at http://10.10.5.12:52118
14/06/19 10:34:43 INFO HttpFileServer: HTTP File server directory is /var/folders/vm/5pggdh2x3_s_l6z55brtql3h0000gn/T/spark-b5c0fd3b-d197-4318-9d1d-7eda2b856b3c
14/06/19 10:34:43 INFO HttpServer: Starting HTTP Server
14/06/19 10:34:43 INFO SparkUI: Started SparkUI at http://10.10.5.12:4040
2014-06-19 10:34:43.751 java[816:1003] Unable to load realm info from SCDynamicStore
14/06/19 10:34:43 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
14/06/19 10:34:44 INFO MemoryStore: ensureFreeSpace(146579) called with curMem=0, maxMem=77974732
14/06/19 10:34:44 INFO MemoryStore: Block broadcast_0 stored as values to memory (estimated size 143.1 KB, free 74.2 MB)
14/06/19 10:34:44 INFO FileInputFormat: Total input paths to process : 1
14/06/19 10:34:44 INFO SparkContext: Starting job: reduce at SparkReduce.java:50
14/06/19 10:34:44 INFO DAGScheduler: Got job 0 (reduce at SparkReduce.java:50) with 2 output partitions (allowLocal=false)
14/06/19 10:34:44 INFO DAGScheduler: Final stage: Stage 0(reduce at SparkReduce.java:50)
14/06/19 10:34:44 INFO DAGScheduler: Parents of final stage: List()
14/06/19 10:34:44 INFO DAGScheduler: Missing parents: List()
14/06/19 10:34:44 INFO DAGScheduler: Submitting Stage 0 (MappedRDD[2] at map at SparkReduce.java:43), which has no missing parents
14/06/19 10:34:44 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (MappedRDD[2] at map at SparkReduce.java:43)
14/06/19 10:34:44 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
14/06/19 10:34:44 INFO TaskSetManager: Starting task 0.0:0 as TID 0 on executor localhost: localhost (PROCESS_LOCAL)
14/06/19 10:34:44 INFO TaskSetManager: Serialized task 0.0:0 as 1993 bytes in 3 ms
14/06/19 10:34:44 INFO TaskSetManager: Starting task 0.0:1 as TID 1 on executor localhost: localhost (PROCESS_LOCAL)
14/06/19 10:34:44 INFO TaskSetManager: Serialized task 0.0:1 as 1993 bytes in 0 ms
14/06/19 10:34:44 INFO Executor: Running task ID 0
14/06/19 10:34:44 INFO Executor: Running task ID 1
14/06/19 10:34:44 INFO BlockManager: Found block broadcast_0 locally
14/06/19 10:34:44 INFO BlockManager: Found block broadcast_0 locally
14/06/19 10:34:44 INFO HadoopRDD: Input split: file:/Users/margusja/Documents/workspace/Spark_1.0.0/data.txt:0+192
14/06/19 10:34:44 INFO HadoopRDD: Input split: file:/Users/margusja/Documents/workspace/Spark_1.0.0/data.txt:192+193
14/06/19 10:34:44 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
14/06/19 10:34:44 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
14/06/19 10:34:44 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
14/06/19 10:34:44 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
14/06/19 10:34:44 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
14/06/19 10:34:44 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
line: Apache Spark is a fast and general-purpose cluster computing system. 69
line: It provides high-level APIs in Java, Scala and Python, 55
a: 69
b: 55
line: and an optimized engine that supports general execution graphs. 64
a: 124
b: 64
line: It also supports a rich set of higher-level tools including Shark (Hive on Spark), 83
a: 188
b: 83
line: Spark SQL for structured data, 31
line: MLlib for machine learning, 28
a: 31
b: 28
line: GraphX for graph processing, and Spark Streaming. 49
a: 59
b: 49
14/06/19 10:34:44 INFO Executor: Serialized size of result for 0 is 675
14/06/19 10:34:44 INFO Executor: Serialized size of result for 1 is 675
14/06/19 10:34:44 INFO Executor: Sending result for 1 directly to driver
14/06/19 10:34:44 INFO Executor: Sending result for 0 directly to driver
14/06/19 10:34:44 INFO Executor: Finished task ID 1
14/06/19 10:34:44 INFO Executor: Finished task ID 0
14/06/19 10:34:44 INFO TaskSetManager: Finished TID 0 in 88 ms on localhost (progress: 1/2)
14/06/19 10:34:44 INFO TaskSetManager: Finished TID 1 in 79 ms on localhost (progress: 2/2)
14/06/19 10:34:44 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
14/06/19 10:34:44 INFO DAGScheduler: Completed ResultTask(0, 0)
14/06/19 10:34:44 INFO DAGScheduler: Completed ResultTask(0, 1)
14/06/19 10:34:44 INFO DAGScheduler: Stage 0 (reduce at SparkReduce.java:50) finished in 0.110 s
a: 271
b: 108
14/06/19 10:34:45 INFO SparkContext: Job finished: reduce at SparkReduce.java:50, took 0.2684 s
Lenght: 379
(r) above a|b means task was reduce.

Marek & Fred


Why there is BigData
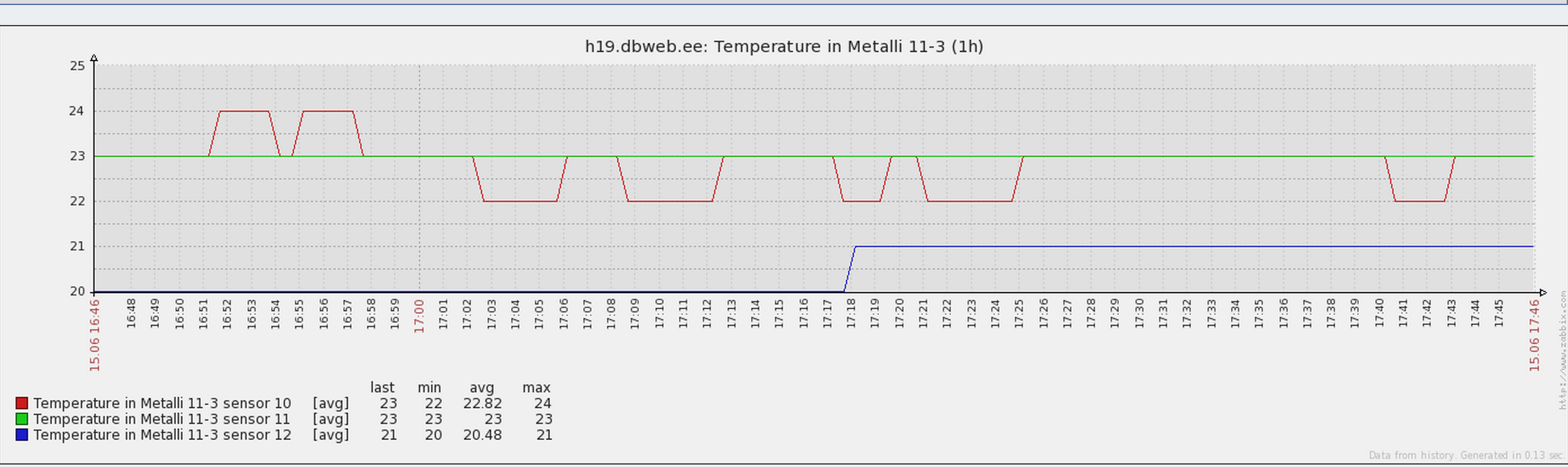
Even I am creating continuous data every day via home made temperature sensors in my home




And let’s send our data to the “real world” – in to the Internet

And output on zabbix
How to motivate yourself to discover new technology
There is apache-spark. I installed it examined examples and run them. Worked. Now what?
One way is to go to linkedin and mark yourself now as the expert of spark and forget the topic.
Another way is to create a interesting problem and try to solve it. After that you may go to the linkedin and mark yourself as a expert 😉
So here is my prolem
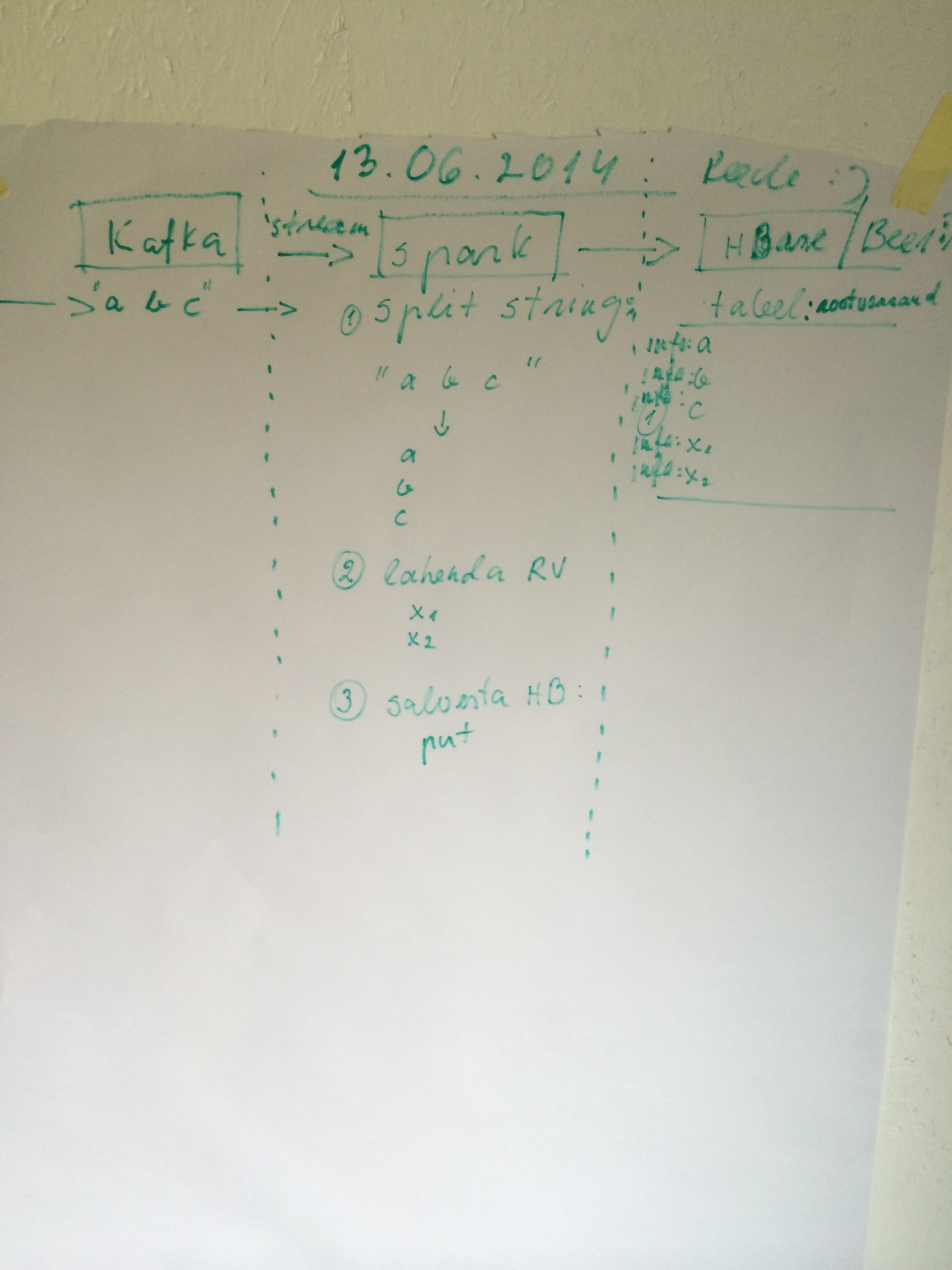
What do I have here. From the left to right. Apache-kafka is receives stream like string “a b c” thous are quadratic equation‘s (ax2 + bx + c = 0) input.
Apache-Spark is going to resolve quadratic equation and saves input parameters and results x1 and x2 to hbase.
The big picture

As you see now the day is much more interesting 🙂
On let’s jump into technology.
First I am going to create HBase table with one column family:
hbase(main):027:0> create ‘rootvorrand’, ‘info’
hbase(main):043:0> describe ‘rootvorrand’
DESCRIPTION ENABLED
‘rootvorrand’, {NAME => ‘info’, DATA_BLOCK_ENCODING => ‘NONE’, BLOOMFILTER => ‘ROW’, REPLICATION_SCOPE => ‘0’, VERSIONS => ‘1’, COMPRESSION => ‘NONE’, MIN_VERSIONS => ‘0’, TT true
L => ‘2147483647’, KEEP_DELETED_CELLS => ‘false’, BLOCKSIZE => ‘65536’, IN_MEMORY => ‘false’, BLOCKCACHE => ‘true’}
1 row(s) in 0.0330 seconds
I can see my new table in UI too
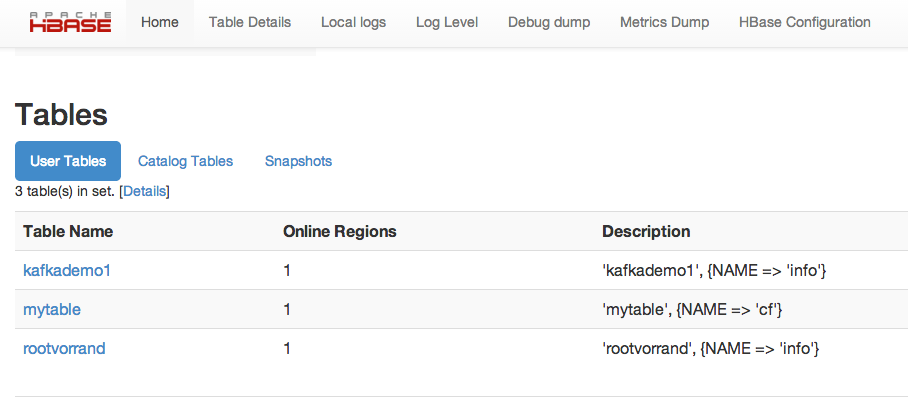
Now I going to create apache-kafka topic with 3 replica and 1 partition
margusja@IRack:~/kafka_2.9.1-0.8.1.1$ bin/kafka-topics.sh –create –topic rootvorrand –partitions 1 –replication-factor 3 –zookeeper vm24:2181
margusja@IRack:~/kafka_2.9.1-0.8.1.1$ bin/kafka-topics.sh –describe –topic rootvorrand –zookeeper vm24.dbweb.ee:2181
Topic:rootvorrand PartitionCount:1 ReplicationFactor:3 Configs:
Topic: rootvorrand Partition: 0 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
Add some input data

Now lets set up development environment in Eclipse. I need some external jars. As you can see I am using the latest apache-spark 1.0.0 released about week ago.
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.UUID;
import java.util.regex.Pattern;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka.*;
import scala.Tuple2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.HTablePool;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
public class KafkaSparkHbase {
private static final Pattern SPACE = Pattern.compile(” “);
private static HTable table;
public static void main(String[] args) {
String topic = “rootvorrand”;
int numThreads = 1;
String zkQuorum = “vm38:2181,vm37:2181,vm24:2181”;
String KafkaConsumerGroup = “sparkScript”;
String master = “spark://dlvm2:7077”;
// HBase config
Configuration conf = HBaseConfiguration.create();
conf.set(“hbase.defaults.for.version”,”0.96.0.2.0.6.0-76-hadoop2″);
conf.set(“hbase.defaults.for.version.skip”,”true”);
conf.set(“hbase.zookeeper.quorum”, “vm24,vm38,vm37”);
conf.set(“hbase.zookeeper.property.clientPort”, “2181”);
conf.set(“hbase.rootdir”, “hdfs://vm38:8020/user/hbase/data”);
try {
table = new HTable(conf, “rootvorrand”);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//SparkConf sparkConf = new SparkConf().setAppName(“KafkaSparkHbase”).setMaster(master).setJars(jars);
JavaStreamingContext jssc = new JavaStreamingContext(master, “KafkaWordCount”,
new Duration(2000), System.getenv(“SPARK_HOME”),
JavaStreamingContext.jarOfClass(KafkaSparkHbase.class));
//JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, new Duration(2000));
Map<String, Integer> topicMap = new HashMap<String, Integer>();
topicMap.put(topic, numThreads);
JavaPairReceiverInputDStream<String, String> messages = KafkaUtils.createStream(jssc, zkQuorum, KafkaConsumerGroup, topicMap);
JavaDStream lines = messages.map(new Function<Tuple2<String, String>, String>() {
@Override
public String call(Tuple2<String, String> tuple2) {
return tuple2._2();
}
});
// resolve quadratic equation
JavaDStream result = lines.map(
new Function<String, String>()
{
@Override
public String call(String x) throws Exception {
//System.out.println(“Input is: “+ x);
Integer a,b,c,y, d;
String[] splitResult = null;
Integer x1 = null;
Integer x2 = null;
splitResult = SPACE.split(x);
//System.out.println(“Split: “+ splitResult.length);
if (splitResult.length == 3)
{
a = Integer.valueOf(splitResult[0]);
b = Integer.valueOf(splitResult[1]);
c = Integer.valueOf(splitResult[2]);
y=(b*b)-(4*a*c);
d=(int) Math.sqrt(y);
//System.out.println(“discriminant: “+ d);
if (d > 0)
{
x1=(-b+d)/(2*a);
x2=(-b-d)/(2*a);
}
}
return x + ” “+ x1 + ” “+ x2;
}
}
);
result.foreachRDD(
new Function<JavaRDD, Void>() {
@Override
public Void call(final JavaRDD x) throws Exception {
System.out.println(x.count());
List arr = x.toArray();
for (String entry : arr) {
//System.out.println(entry);
Put p = new Put(Bytes.toBytes(UUID.randomUUID().toString()));
p.add(Bytes.toBytes(“info”), Bytes.toBytes(“record”), Bytes.toBytes(entry));
table.put(p);
}
table.flushCommits();
return null;
}
}
);
//result.print();
jssc.start();
jssc.awaitTermination();
}
}
pack it and run it:
[root@dlvm2 ~]java -cp kafkasparkhbase-0.1.jar KafkaSparkHbase
…
14/06/17 12:14:48 INFO JobScheduler: Finished job streaming job 1402996488000 ms.0 from job set of time 1402996488000 ms
14/06/17 12:14:48 INFO JobScheduler: Total delay: 0.052 s for time 1402996488000 ms (execution: 0.047 s)
14/06/17 12:14:48 INFO MappedRDD: Removing RDD 134 from persistence list
14/06/17 12:14:48 INFO BlockManager: Removing RDD 134
14/06/17 12:14:48 INFO MappedRDD: Removing RDD 133 from persistence list
14/06/17 12:14:48 INFO BlockManager: Removing RDD 133
14/06/17 12:14:48 INFO BlockRDD: Removing RDD 132 from persistence list
14/06/17 12:14:48 INFO BlockManager: Removing RDD 132
14/06/17 12:14:48 INFO KafkaInputDStream: Removing blocks of RDD BlockRDD[132] at BlockRDD at ReceiverInputDStream.scala:69 of time 1402996488000 ms
14/06/17 12:14:48 INFO BlockManagerInfo: Added input-0-1402996488400 in memory on dlvm2:33264 (size: 78.0 B, free: 294.9 MB)
14/06/17 12:14:48 INFO BlockManagerInfo: Added input-0-1402996488400 in memory on dlvm1:41044 (size: 78.0 B, free: 294.9 MB)
14/06/17 12:14:50 INFO ReceiverTracker: Stream 0 received 1 blocks
14/06/17 12:14:50 INFO JobScheduler: Starting job streaming job 1402996490000 ms.0 from job set of time 1402996490000 ms
14/06/17 12:14:50 INFO JobScheduler: Added jobs for time 1402996490000 ms
14/06/17 12:14:50 INFO SparkContext: Starting job: take at DStream.scala:593
14/06/17 12:14:50 INFO DAGScheduler: Got job 5 (take at DStream.scala:593) with 1 output partitions (allowLocal=true)
14/06/17 12:14:50 INFO DAGScheduler: Final stage: Stage 6(take at DStream.scala:593)
14/06/17 12:14:50 INFO DAGScheduler: Parents of final stage: List()
14/06/17 12:14:50 INFO DAGScheduler: Missing parents: List()
14/06/17 12:14:50 INFO DAGScheduler: Computing the requested partition locally
14/06/17 12:14:50 INFO BlockManager: Found block input-0-1402996488400 remotely
Input is: 1 4 3
Split: 3
discriminant: 2
x1: -1 x2: -3
14/06/17 12:14:50 INFO SparkContext: Job finished: take at DStream.scala:593, took 0.011823803 s
——————————————-
Time: 1402996490000 ms
——————————————-
1 4 3 -1 -3
As we can see. Input data from kafka is 1 4 3 and spark output line is 1 4 3 -1 -3 where -1 -3 are roots.
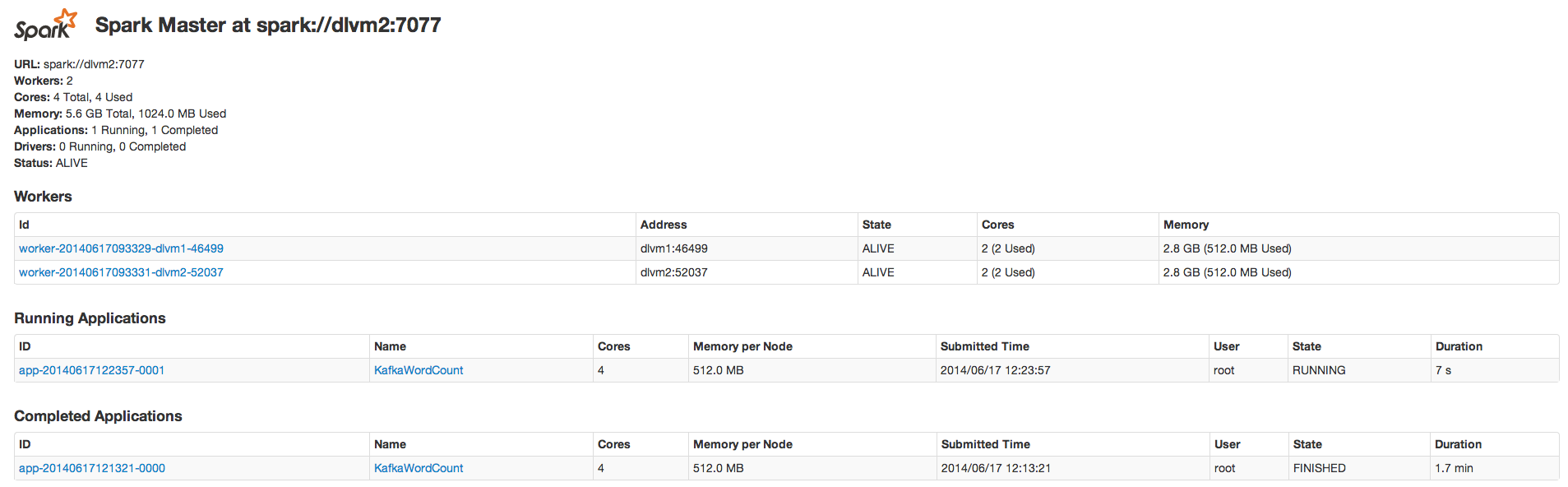
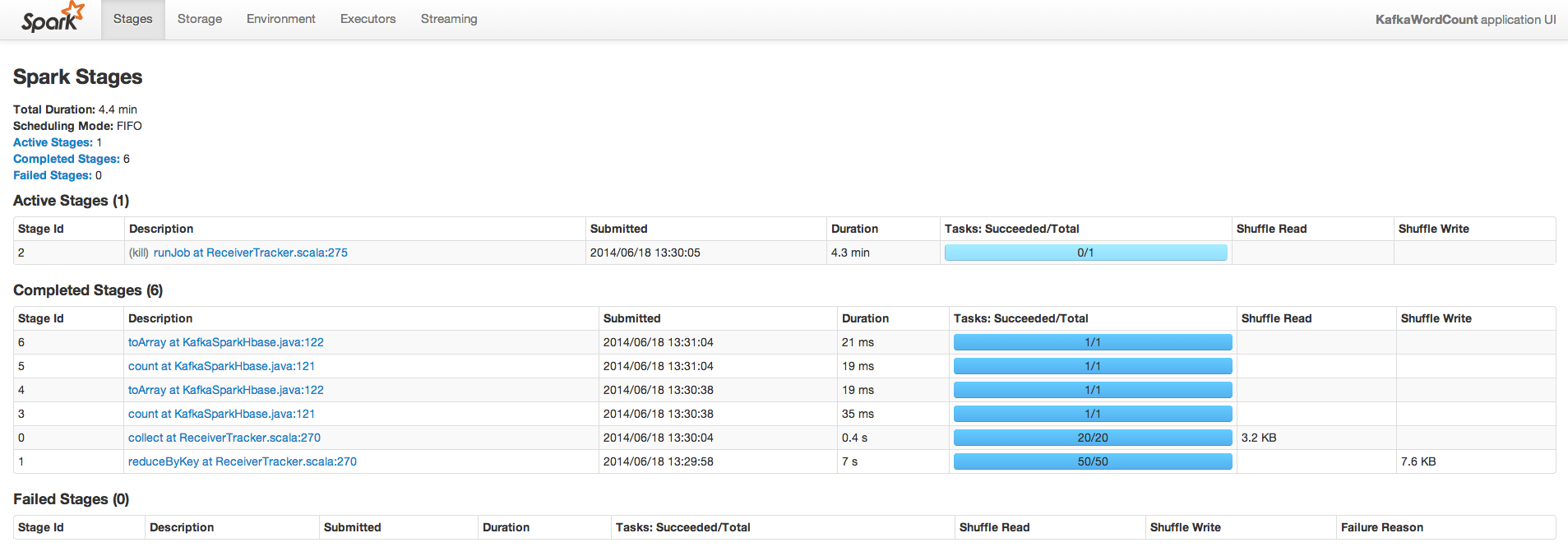
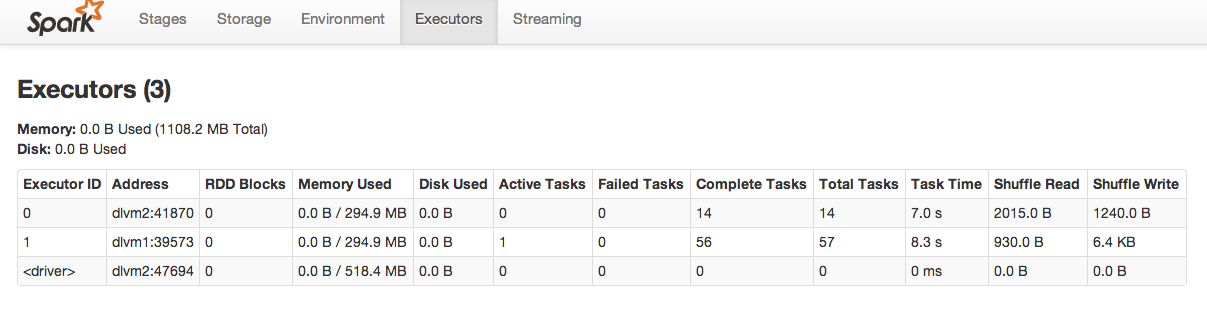
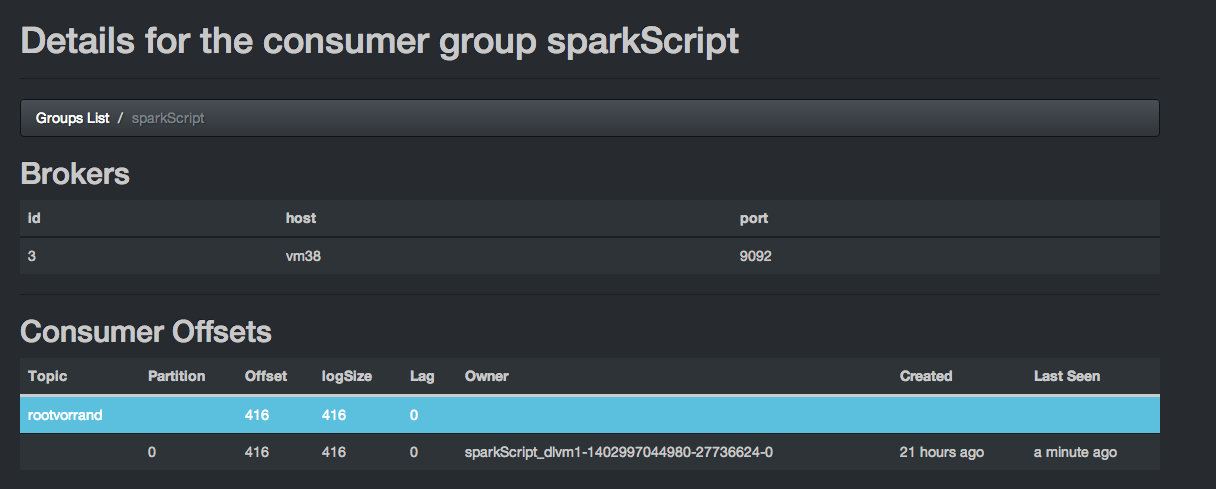
We can also see that there no lag in kafka queue. Spark worker is consumed all data from the queue
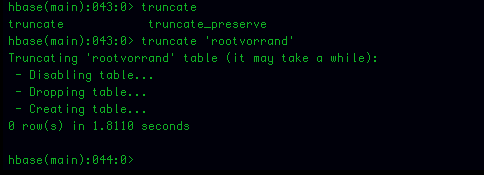
Let’s empty our HBase table:
put some input variables to kafka queue
-2 -3 10
2 -4 -10
And scan HBase table rootvorrand

As you can see. There are our input variables and roots.
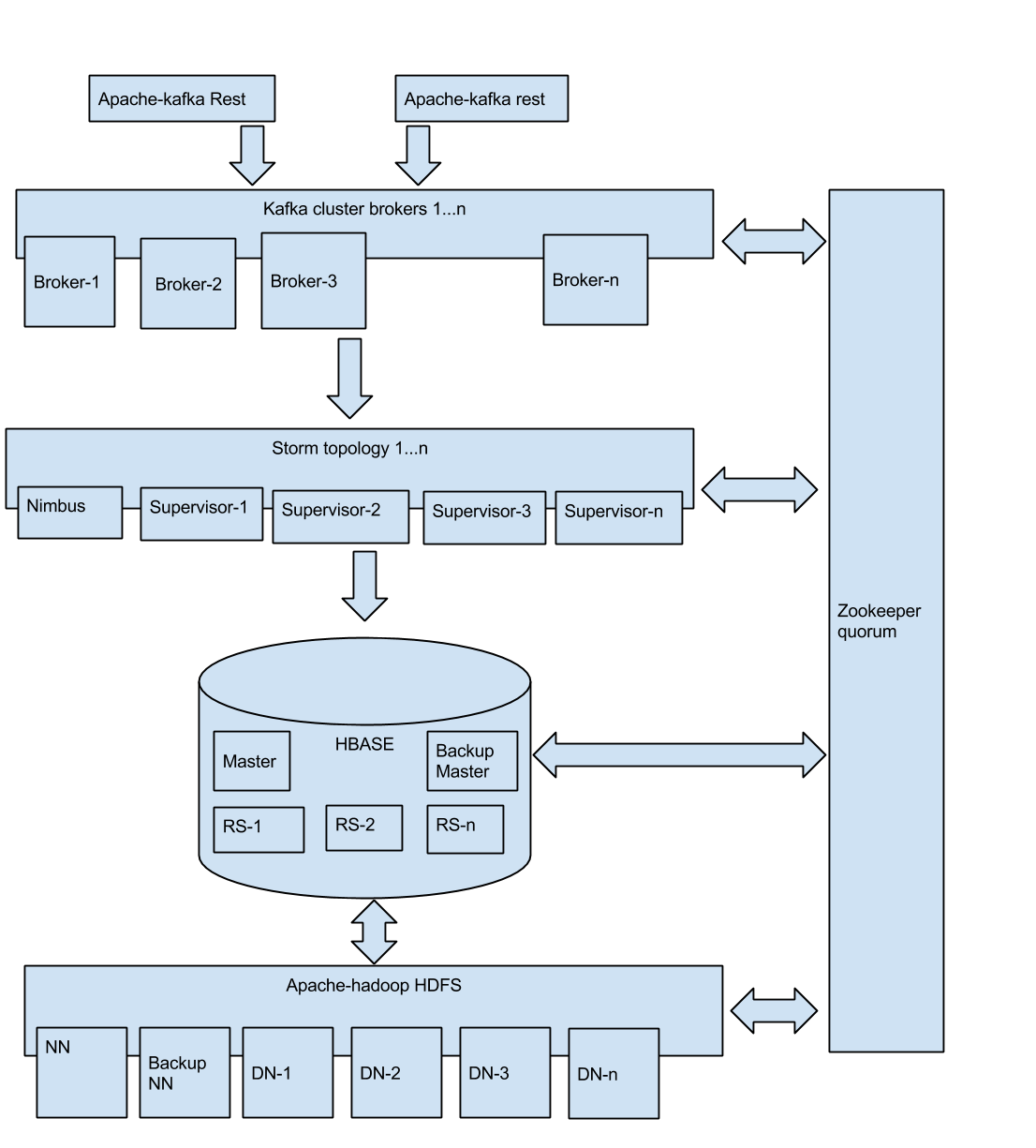
Ilus pilt bigdata vahenditega – Kafka storm hbase hadoop-hdfs zookeeper